



Hi everyone!
I’m back with the second and last part of the GraphQL best practice series. First part was all about authentication types & which one you should use and how to authenticate GraphQL requests. This post will focus on how to work with MMM in GraphQL - so let’s get into it.
If you’d like to check out the first part I’m sharing it here 👇
ONE Metadata Readers Or GraphQL?
MMM is the name for the linked list that holds all metadata and the connections between them. Pretty much everything in MMM can be explored via GraphQL - as GraphQL is what happens behind the scenes in most steps/actions in ONE Desktop.
As far as ONE Desktop is concerned, while ONE Metadata Readers are often all you need, highly nested queries and associated joins can become quite tricky to handle via ONE Desktop plans, and can sometimes be simpler to build by just running a specific GraphQL query. In addition to that, some things, such as raw profiling information can only be extracted via GraphQL.
Exploring MMM
One of the questions you might have is how to get the data out of MMM?
To find a route in the MMM model, you can either use the Settings panel, or in ONE Desktop you can use the ONE Metadata Explorer tab + the Advanced tab in Properties to help you plot a route.
In the below example, we can see that rule links to termInstances links to target.
When using GraphQL, you would use “term”, rather than the descriptive name “target” as part of your query:

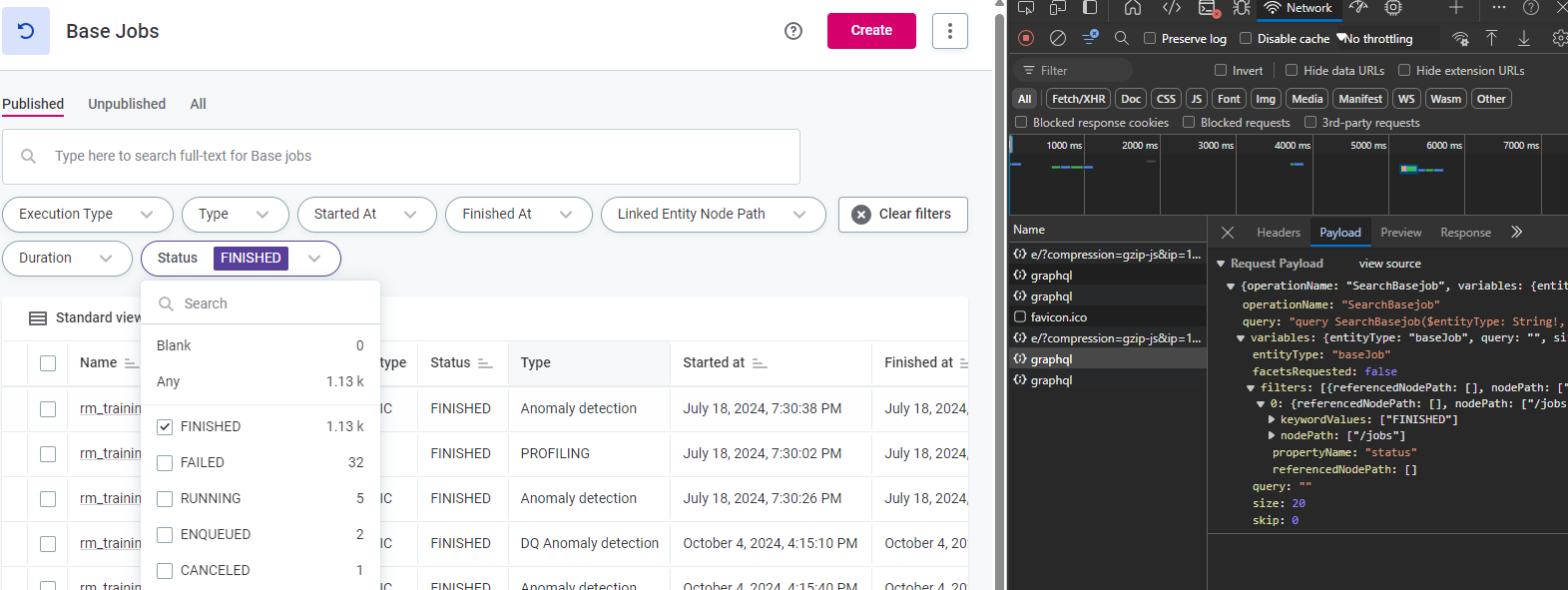
Browser DevTools
You can also get non MMM information (e.g. job status, audit, etc), if you know what graphQL gets called by the platform at the right time. If you’d like to explore this, check your Network section under the Browser’s DevTools, which captures all web requests and responses. There are also web extensions that can help simplify this.
You can then work backwards to build your own - I’d keep in mind while reverse engineering how much of it can be put on prod.
GraphQL Requests Structure
To build requests yourself, it is helpful to understand the structure of how data is held in the platform.
💡Some tips:
- The root of your query normally either has to refer to a singular instance of something filtered by gid
catalogItem(gid: "5c866cdf-0000-7000-0000-0000000553fb")
-
or as a plural when returning for multiple items belonging to a single entity
catalogItems
- Depending on what you select and how you select it, you normally have to specify if you want the published or draft version, and the way in which you specify this is often inconsistent. You may also have to combine these together over the course of your query:
catalogItem(gid: "5c866cdf-0000-7000-0000-0000000553fb") {
publishedVersion {
...
}
} -
catalogItems(versionSelector: {publishedVersion: true}) {
...
}To get at the attributes/other linked MMM items, you must almost always first go through 1-2 “layers” of non-attributes, edges and node/nodes (you will have to determine which of edge, edges, node and/or nodes work and in which order by trial/error)
catalogItems(versionSelector: {publishedVersion: true}) {
edges {
node { --(sometimes nodes instead of node)
...
}
}
}
- For performance reasons, most queries will allow you to use two top level attributes called size and skip, which lets you paginate responses. This is extremely difficult to orchestrate in ONE Desktop, but when you have the opportunity to use a different tool, and you know the response from your query will be huge it is a very good idea.
query GetJobs{
baseJobs(
versionSelector: {draftVersion: true}
orderBy: {property: "createdAt", direction: DESC}
size: 20
skip: 0
) {
edges {
node {
gid
type
draftVersion {
name
type
status
createdAt
linkedEntityId
linkedEntityNodePath
linkedEntityHcn
correlationId
}
}
}
}
}
Putting everything together, here is an example request that gets all Profiling data:
query getProfileData {
attributeProfiles(versionSelector: { publishedVersion: true }) {
edges {
node {
gid
publishedVersion {
displayName
attributeProfileData {
publishedVersion {
distinctCount
duplicateCount
frequencyCount
frequencyGroupsCount
masksCount
minValue
maxValue
nonUniqueCount
nullCount
numMin
numMean
numMax
numStdDeviation
numSum
numVariance
patternsCount
stringMinLength
stringMeanLength
stringMaxLength
totalCount
uniqueCount
frequencyGroupsHead(
orderBy: { property: "count", direction: DESC }
size: 3
) {
edges {
node {
publishedVersion {
value
count
}
}
}
}
masksHead(
orderBy: { property: "count", direction: DESC }
size: 3
) {
edges {
node {
publishedVersion {
value
count
}
}
}
}
patternsHead(
orderBy: { property: "count", direction: DESC }
size: 3
) {
edges {
node {
publishedVersion {
value
count
}
}
}
}
quantiles(
orderBy: { property: "percentile", direction: DESC }
size: 3
) {
edges {
node {
publishedVersion {
value
percentile
}
}
}
}
}
}
}
}
}
}
}
And that’s all!
My suggestion and what I use daily is to work these on the playground first, building the query in small chunks.
Hope you found this short series helpful, let me know if you have any best practices, tips, or questions in the comments!