How can we handle csv output from API response?
I tried to use json call ,SOAP call but it didn't work.Anyway, can we handle in One desktop csv output from API.

How can we handle csv output from API response?
I tried to use json call ,SOAP call but it didn't work.Anyway, can we handle in One desktop csv output from API.
Best answer by AKislyakov
Hi
Ataccama One desktop does not have built in step to handle CSV APIs.
I can suggest one of two ways.
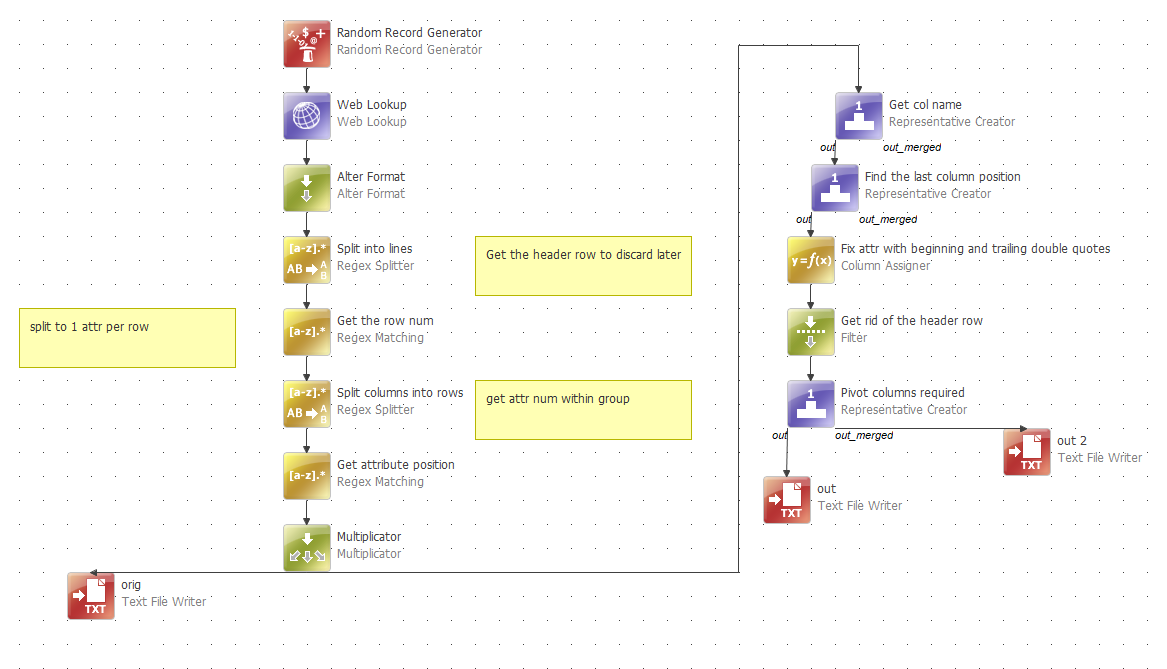
First one is to use HTTP Get step in the workflow to save a result of an API call as a text file and then process it using plan and Text File Reader step.
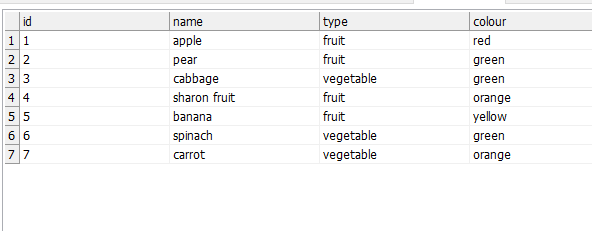
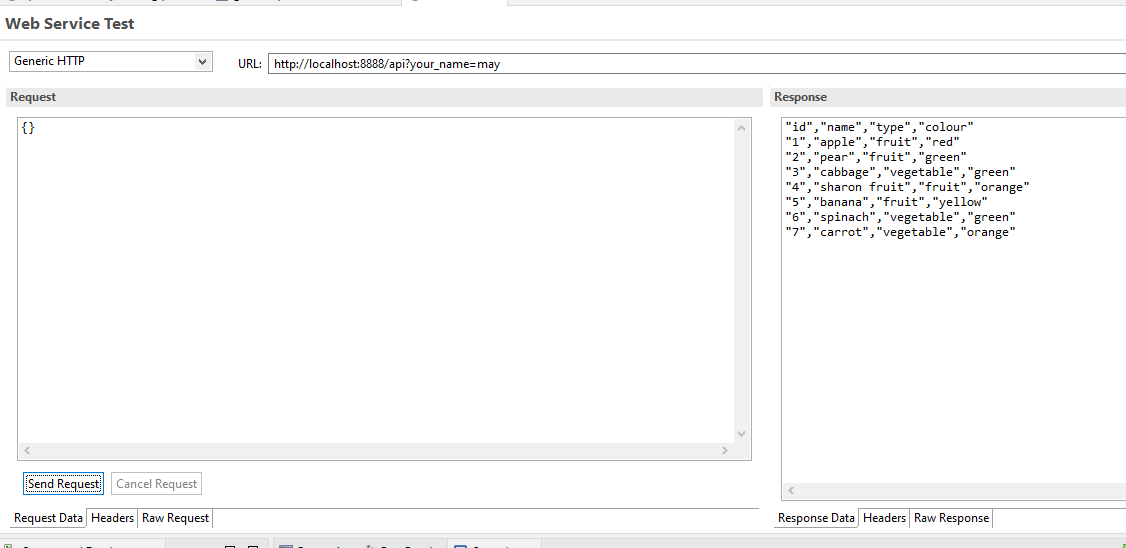
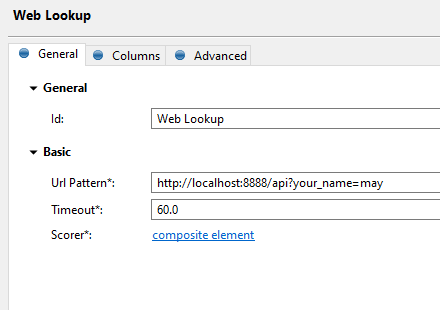
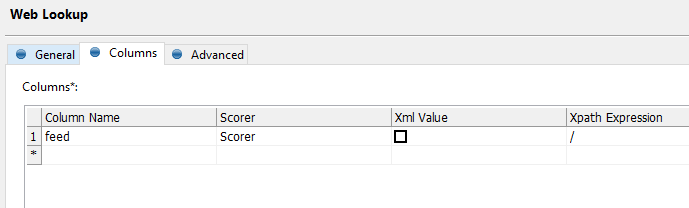
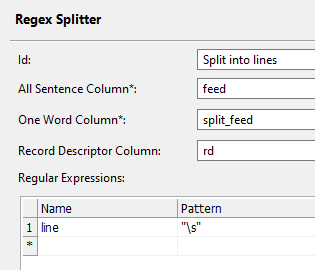
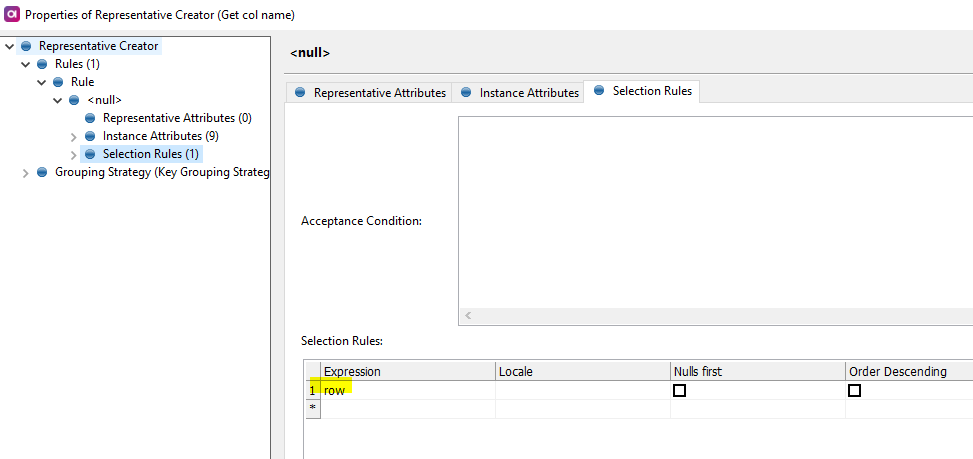
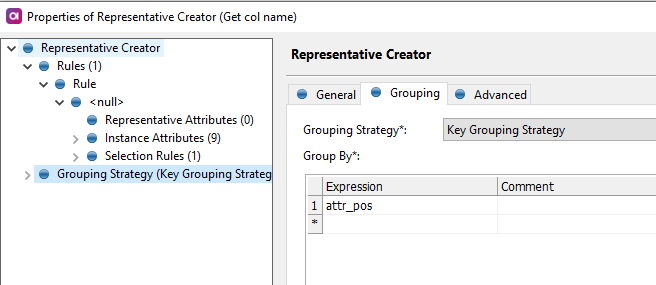
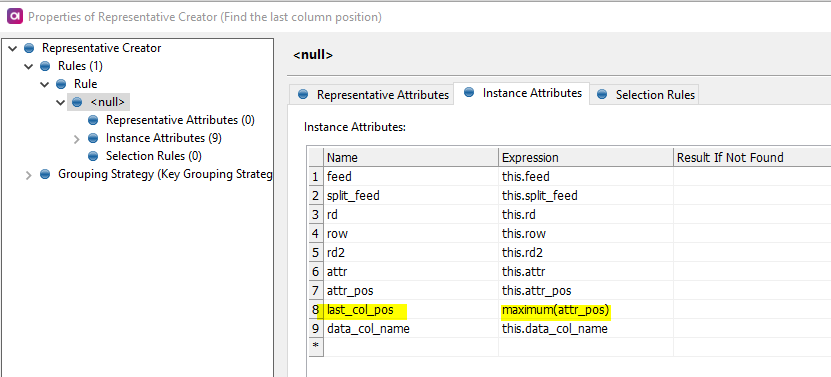
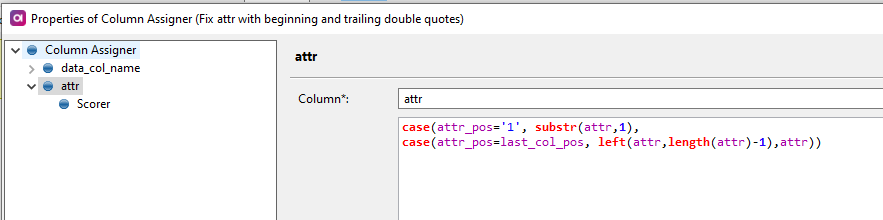
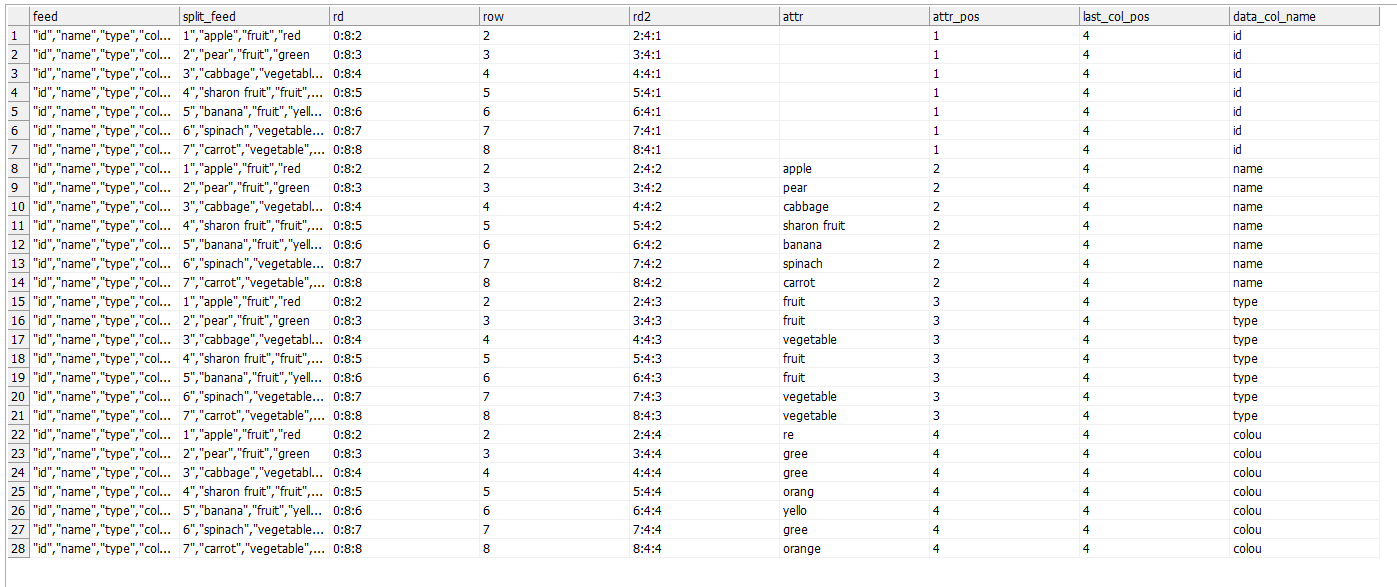
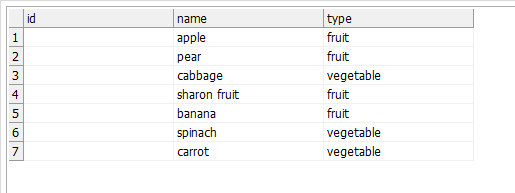
The second one is to use Web lookup step. The Web lookup step will obtain the CSV data and will warp it into an XML object which you can subsequently parse using Splitter and Tokenizer steps. The result should be similar to this:
<?xml version='1.0' encoding='UTF-8'?>
<html>
<head>
<meta name="generator" content="HTML Tidy for Java (vers. 2009-12-01), see jtidy.sourceforge.net"/>
<title/>
</head>
<body>src_full_name;pur_full_name;pur_first_name_orig;pur_last_name_orig;std_first_name;std_last_name;std_titles_prefix;pat_full_name;score_full_name;exp_full_name;pur_full_name_DQ_status;pur_full_name_status John Smith;John Smith;John;Smith;John;Smith;;F! L!;0;;NAME_OK;OK</body>
</html>
I’d recommend going with the first approach if it fits your requirements as it more straightforward and easier to debug.
No account yet? Create an account
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.