
Ataccama MDM presents particular challenges for multiple developers maintaining a solution together. There is no magic bullet to resolve this, but good working practices can minimise the risk of git conflicts and help resolve them when they occur.
Your organization may have established working practices for branch management, naming conventions and so on. Compare these practices with the suggestions here when defining your team processes.
This post assumes the reader is familiar both with MDM and with Git usage – there are many good resources available for Git in general and for Eclipse eGit as used in Ataccama ONE-Desktop; and Ataccama provides training for MDM. This post is long enough: I will not explain technical terms or procedures that should already be familiar or can be looked up elsewhere!
What is the problem?
MDM and RDM use a metadata-based configuration known as a Model Project. This consists of many xml files, and it is very easy for several developers to make model changes at the same time leaving the Git repository with conflicting changes that can only be resolved at the xml level.
Also, model changes in MDM need to be followed by a “generate” action that will apply the current metadata definition to the *.comp data processing files. This can have wide-ranging effects that may conflict when multiple development strands are active at once.
Working with branches
For an Ataccama project, the objective is to deploy code to servers. On our Cloud, we will provide one branch for each target server, usually prod and dev, and often test. These are used by our CI/CD pipelines for server deployment. We will also create a main (or master) branch, which is for the reference “good” copy of the solution. If your installation is self-managed then you can make different choices, but this is a good basis.
For this post, I have created a version of the CDI Example demonstration project that is provided for MDM. I have placed it into my c:\git folder, and I have created remote branches with this same code for each of dev, main and prod in my gitflow-demo project. My ONE Desktop Git perspective now looks like this:
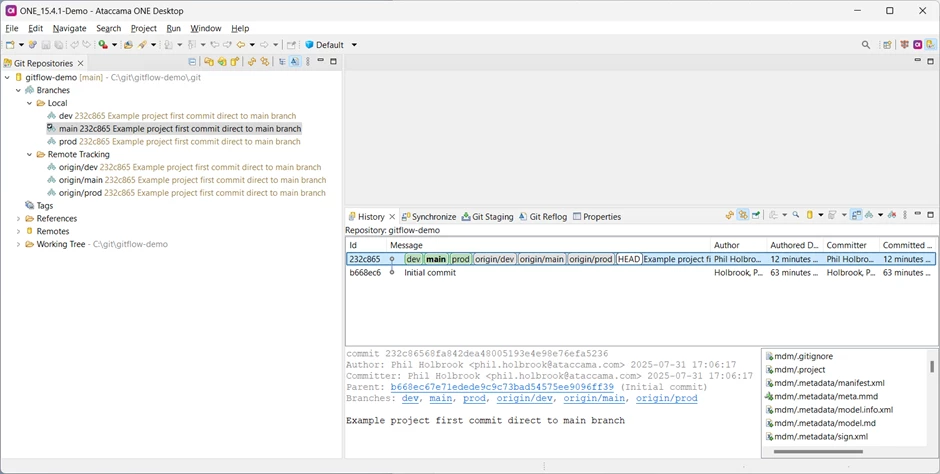
❗Never make any changes directly in a server branch unless you absolutely have to configure something differently for each environment. Try and avoid this, though, because it makes things harder to manage.
Walkthrough
I will implement changes to the MDM sample project using branches as if a development team were working on it together. The sample project represents an insurance company, and we will simply add a free text region field to the Address entity in both the instance and master layer.
Two developers, Adele and Bjorn, will implement the new column definition. Adele will implement the instance layer change; Bjorn will implement the master layer change. This is a terrible way to work, of course, but should show the principle for larger projects!
Starting the project
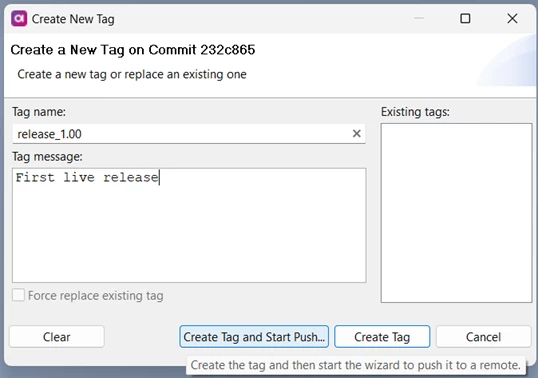
The change to add region will be release 1.01 of the solution. It’s good practice to tag releases in the Git history, so first let’s tag the current live version as release 1.00.
Right-click on the released commit in the history and choose Create tag…
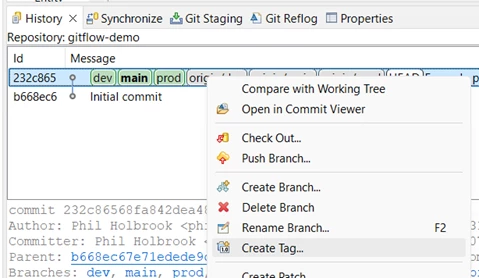
Create the tag and push it, following the prompts
Now create the Integration branch for the development project.
Make sure to have the main branch checked out, and create a new branch from it called
release_1.01:
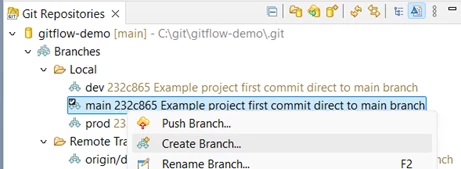
Push the new integration branch so it can be seen by the whole team.
The integration branch will be used to gather together the different developers’ work and make sure it is valid before pushing to any of the real servers. Bad code can prevent MDM servers from starting, so this is an important step.
It is poor practice to have more than one integration branch at a time: keeping one clean and synchronised is hard enough, don’t create two – it will not be practical to merge them when they diverge.
Most projects will involve multiple features – but we’ll just implement this as two, one to add the region to the instance layer, and another to add it to the master layer.
You should have a standard for naming feature branches.
Implementing a feature
Adele will implement the instance layer change.
She takes a new feature branch from the integration branch. Her team standard is to name all features as feature/[release_id]/descriptive_name, so she names her branch,
feature/release_1.01/instance-address-region
Forward slashes are just another character as far as Git is concerned but they are familiar as subdirectories so make a good hierarchical separator.
She makes the change to the model to implement the new column and saves the metadata.
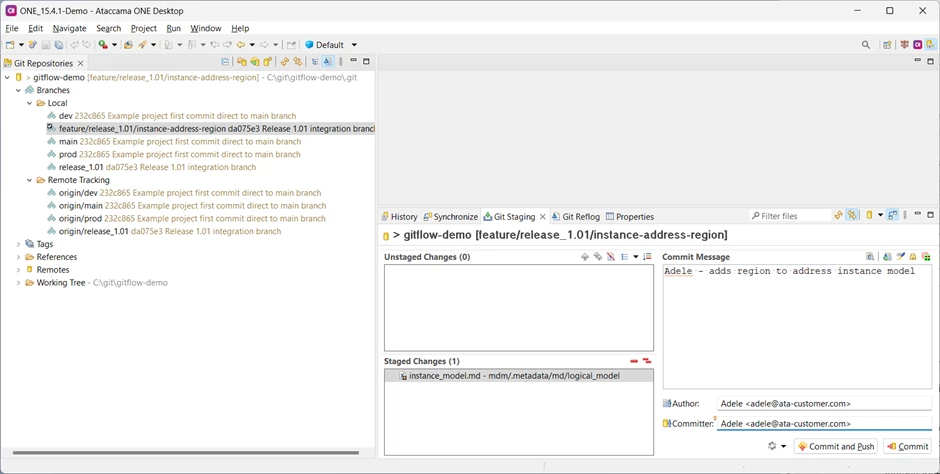
She commits the branch to her local repository but has not yet regenerated. At this point, there is no remote copy of the branch.
❗Best practice is to commit often – it gives you the possibility of resetting your branch to a previous commit if you decide you need to change approach. When working with individual feature branches then it’s best to push often too: it safeguards the code against computer failure, and won’t interfere with anyone else’s work until you change a shared branch.
Overlapping model edits
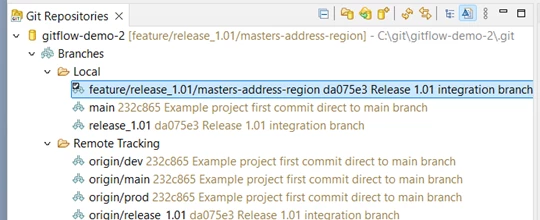
Meanwhile, Bjorn is impatient and decides to start implementing the region column on the master layer without waiting for Adele to finish her model edits. He performs a git fetch, checks out the integration branch and follows team practice to create his own feature branch from it:
feature/release_1.01/masters-address-region
He adds the new column, regenerates and prepares to commit the changes, but can’t complete the masters_address_merge.comp plan, because he needs the column from the instance layer. He decides to leave it and commit his branch.
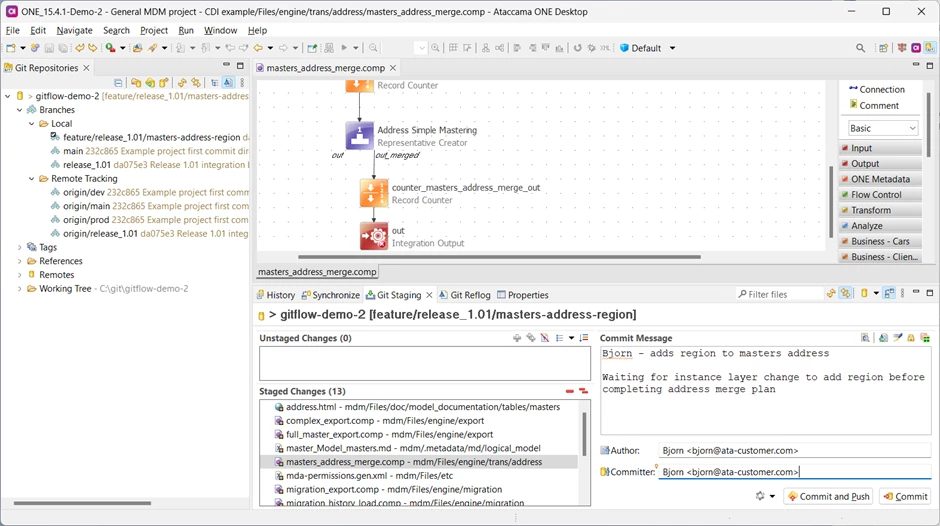
Bjorn’s branch is currently non-operational, because the merge plan is missing a column definition – warned by the red cross in the out step in his plan editor above. A non-functional feature branch is fine but try to merge only working code to the integration branch.
Both Adele and Bjorn have now made changes to the model. This is not good practice as it’s easy for widespread conflicts to occur.
❗It is poor practice for more than one developer to edit the model at a time, because the edits and regeneration can create conflicts
Adele now resumes work on her branch and regenerates the project. This updates 22 files, including several that Bjorn has also updated. There’s nothing to tell her this, though, and she proceeds to commit and push her changes.
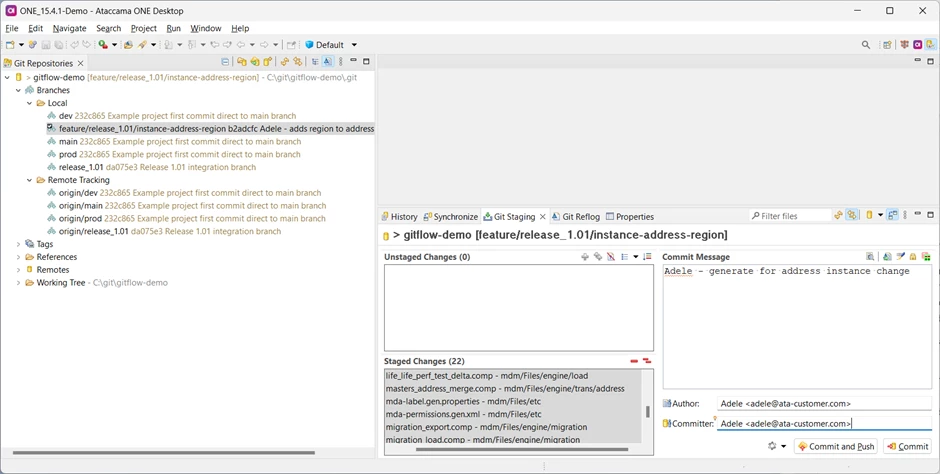
She’s now finished working and wants to merge her feature into the integration branch.
She performs a Fetch from Origin to check for changes in Git.
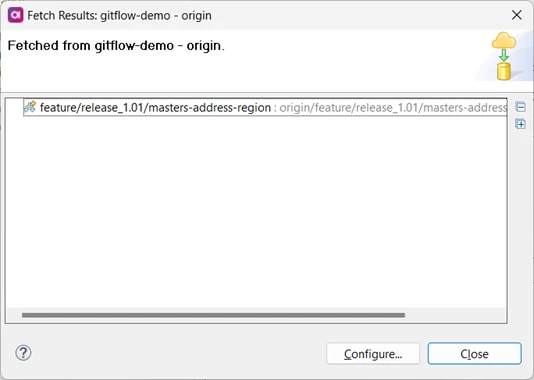
❗Fetch often. Nothing will be updated in your local repository and it helps you know what your colleagues have changed.
Bjorn’s change is there, but nothing has changed in the integration branch, so Adele is OK to merge her feature branch to it. She switches branch to release_1.01, right-clicks her feature branch, and selects merge:
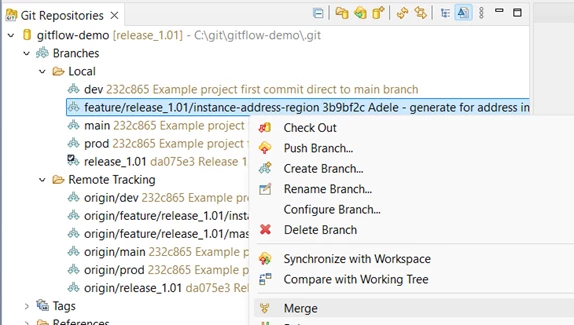
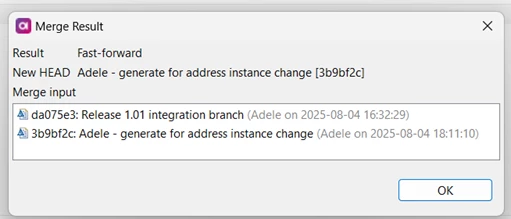
It’s a Fast-forward so everything’s good, and she can Push Head
Adele tells Bjorn she’s finished with the model, so he resumes work.
He performs a fetch and can see Adele’s latest changes:
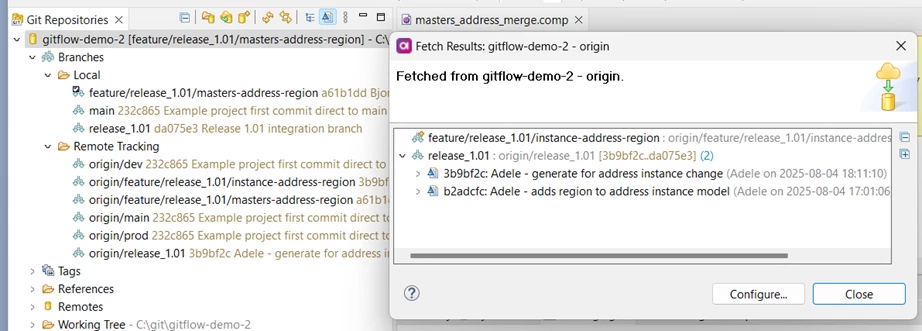
Bjorn sees there is a change to the integration branch. He needs to incorporate the changes from the integration branch into his own feature branch.
Bjorn has his feature branch checked out, but he will need to download the latest code for the integration branch, so he has to check that branch out and pull:
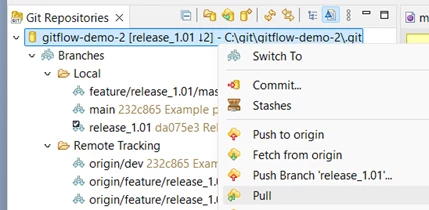
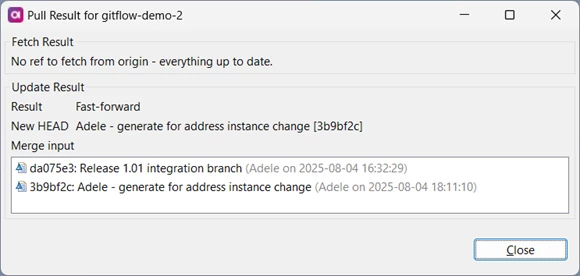
Now he switches back to his feature branch and merges the integration branch.
❗Always merge the Integration branch to your feature branch first. This allows you to fix any inconsistencies between the common project and your work before it gets shared round.
Do this often. If the team is working properly then the Integration branch should always contain working code and merging it to your feature branch will prevent your code from diverging too far.
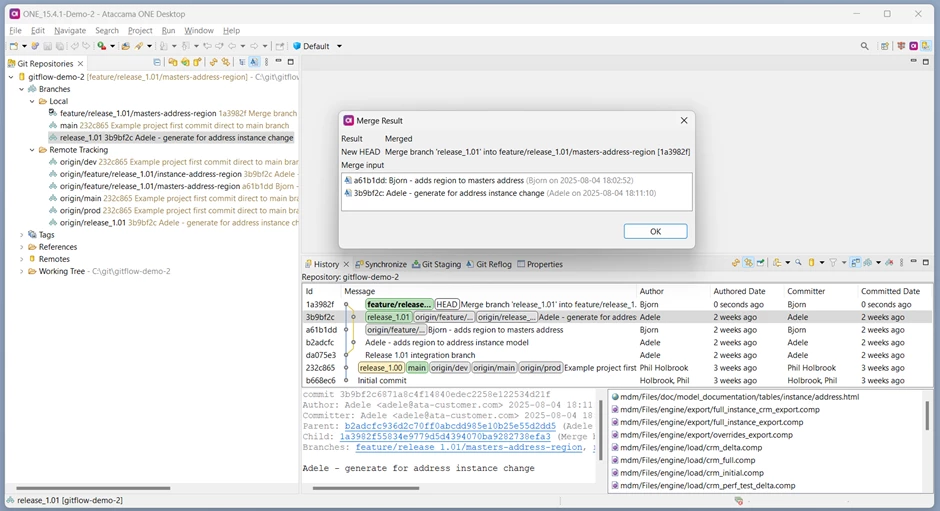
Git appears to have merged the two commits. We can usually compare any file in a commit with the previous version by double-clicking it in the history view, but if we try that now we cannot:
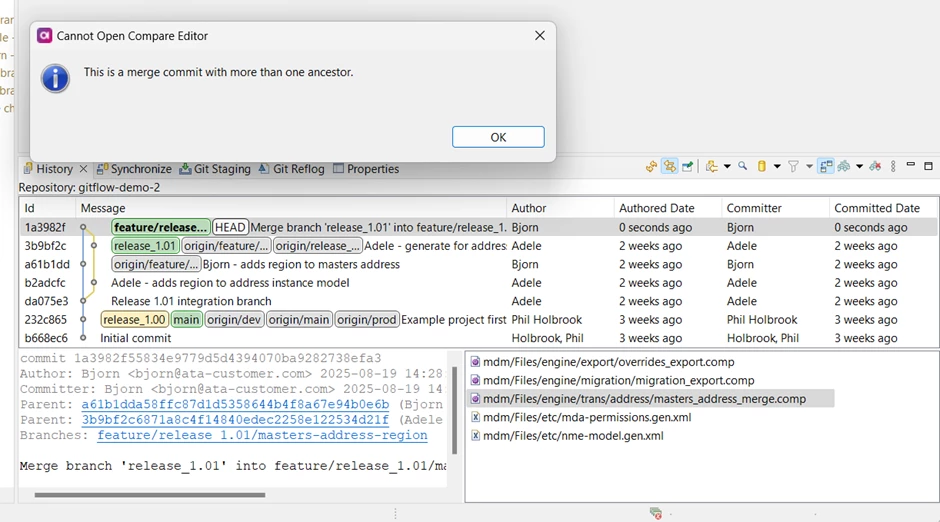
This is because this file was changed in both separate branches. It is still possible to compare the file with each of the parent commits by right-clicking it in the file explorer and selecting Compare with > Commit … which then shows this dialog:
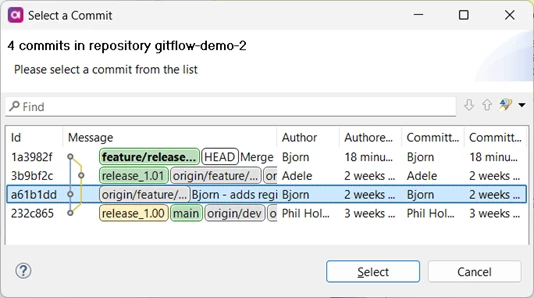
This will allow Bjorn to see what parts of the plan have been changed by merging Adele’s code:
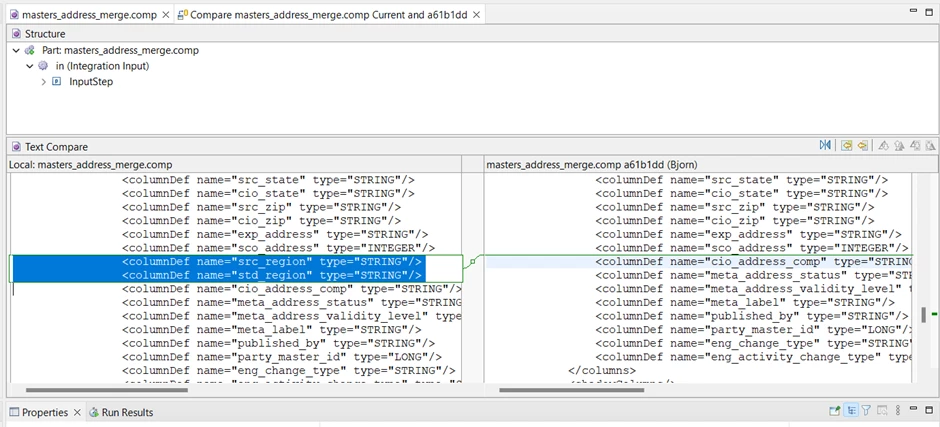
The two instance layer columns added by Adele have been included into the “in (Integration Input)” step.
This is correct, and in fact this whole merge has been handled correctly by Git.
This may not always be the case, though. Git does not “understand” xml syntax in general, or Ataccama plan design, and it is possible for overlapping merges like this to go very wrong. When two changes are made to the same plan or metadata file in separate branches then Git will often report a conflict, because it cannot work out how to combine the changes. You can’t rely on this, though: it is possible for incompatible updates to be merged without reporting a conflict.
It is much better to make sure that the wide-ranging changes caused by model updates are managed cooperatively by the whole team.
❗Only one developer should make model changes at a time and then promptly merge to the integration branch, after which all team members should merge the integration branch back to their own feature branch as a priority.
Now Bjorn has updated his feature branch with the latest changes to the integration branch, he can continue working.
First of all, he reloads the project metadata:
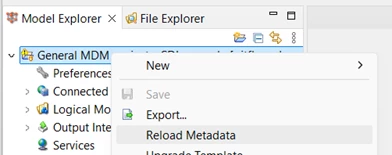
This is stressed in the MDM training, and it is absolutely vital when changing between Git branches or performing merge operations. ONE Desktop will not automatically reload metadata changes when the files stored on the disk change, but will instead carry on using the last copy that was loaded into memory. If you save instead of reloading metadata then you will revert files in the new branch to whatever you were using before, potentially erasing someone else’s work.
❗Always, always, always reload metadata immediately when switching or merging branches.
Bjorn now finishes up his work on the master layer by updating the merge plan, masters_address_merge.comp, to populate cmo_region from an appropriate value from the instance layer. He saves the plan and commits his feature branch.
Adele has carried on updating the cleanse plan, address_clean.comp. The requirement for the new Address Region field is simply to standardise it by converting to uppercase, so she adds a step to assign std_region to upper (src_region) and commits and pushes her branch. She is now finished. She performs a fetch from origin and checks for any further changes to the integration branch:
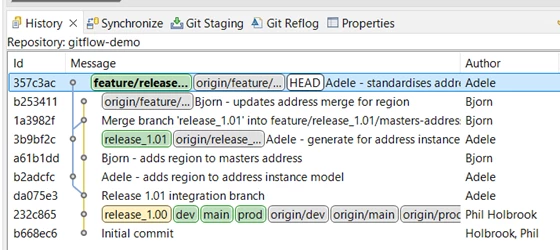
The integration branch release_1.01 is still a direct ancestor to her current commit with no subsequent merges. Bjorn’s feature branch is separate, so she is safe to merge her changes to the integration branch. She checks it out, merges her updated feature branch and pushes the result.
❗Only merge to the integration branch once you have fixed all conflicts using your release branch.
Adele is now finished with her feature. Her branch should be kept at least until the release is complete to help with progress tracking but can eventually be deleted: commits are what really matter, as well as the main (or master) and server-specific branches.
❗You may want to delete old branches from your system. This will make things tidier, but it can be difficult to fully delete old branches because of the distributed nature of Git repositories.
Back to Bjorn, who has completed his work in his feature branch and needs to merge to the integration branch to finish up the release.
He performs a fetch.
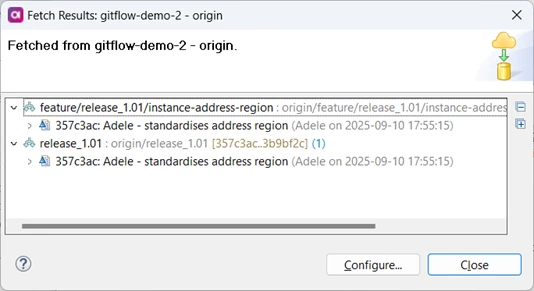
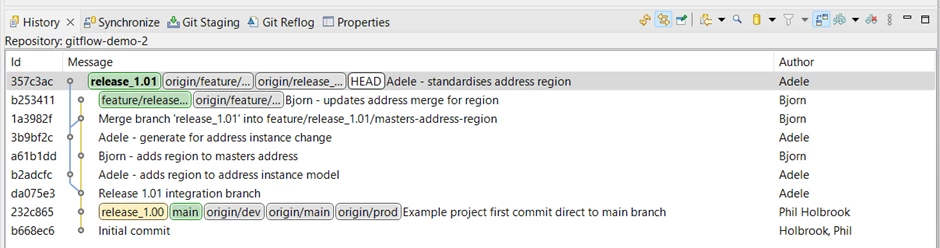
Looking at the history, he can see that there are commits on the integration branch that he has not yet merged to his feature branch.
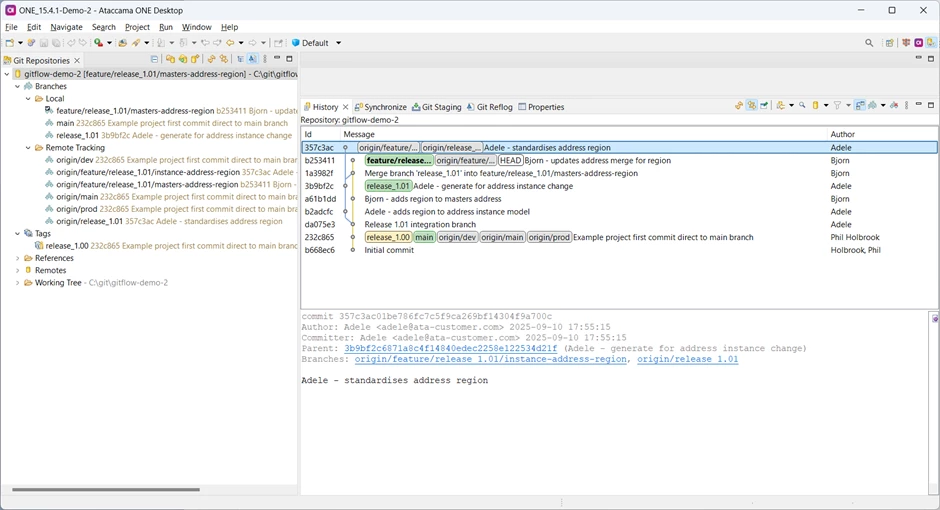
His local copy of the integration branch, shown as

is again behind the origin copy, so he needs to check it out and pull before he can merge it to his feature branch.
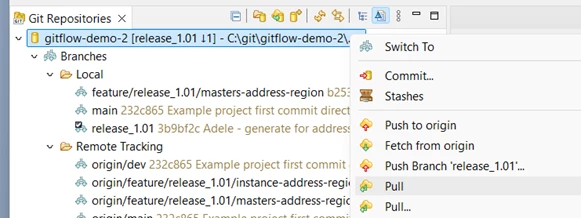
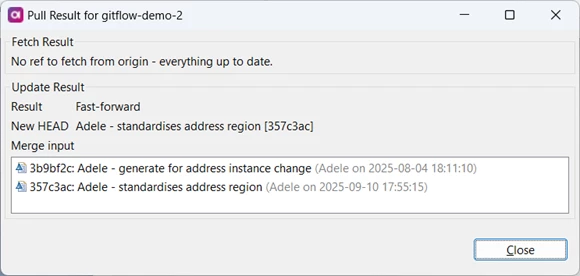
With his local copy of release_1.01 now updated, he can switch back to his feature branch and merge the integration branch to it:
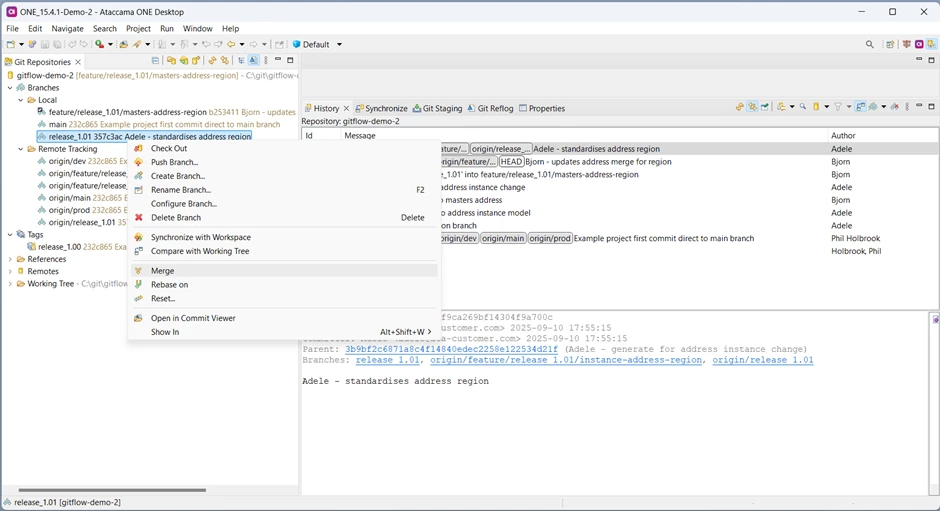
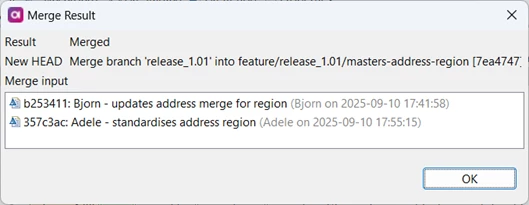
The result is ‘Merged’ so everything should be OK but to be sure, Bjorn selects both the new merged commit (7ea474) and his previous commit (b253411), right clicks and uses the “Compare with Each Other” feature to make sure nothing in the merged code conflicts with his changes
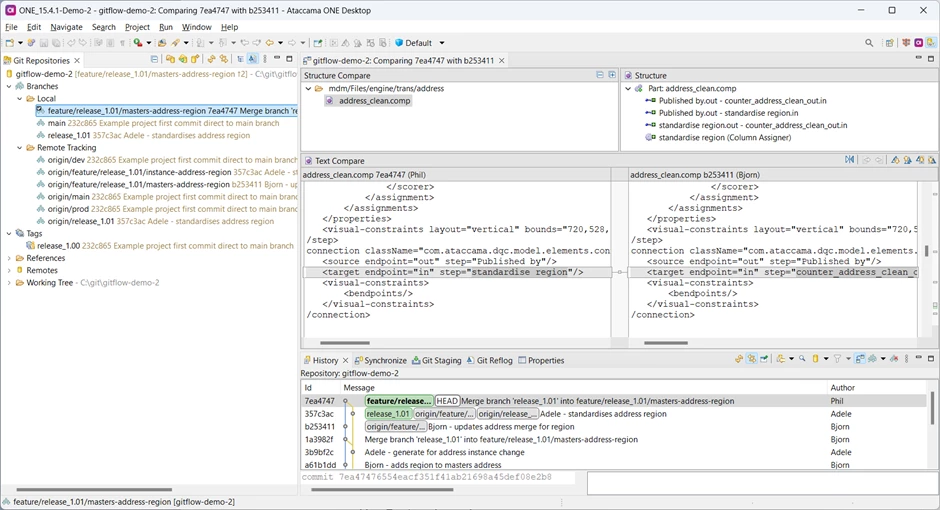
Only the file address_clean.comp has changed, which he wasn’t working on, so he’s confident the merge can’t have broken his code. He merges his feature branch back into the integration branch.
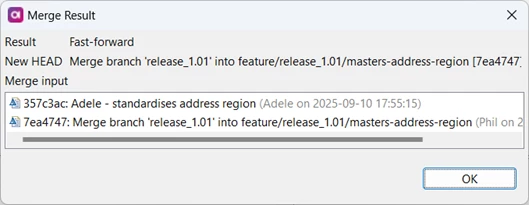
❗Merging to the Integration branch should always be fast forward because there should always be a local commit where you have already made all necessary changes.
Bjorn pushes the branch with Push Head on the Git Staging tab:
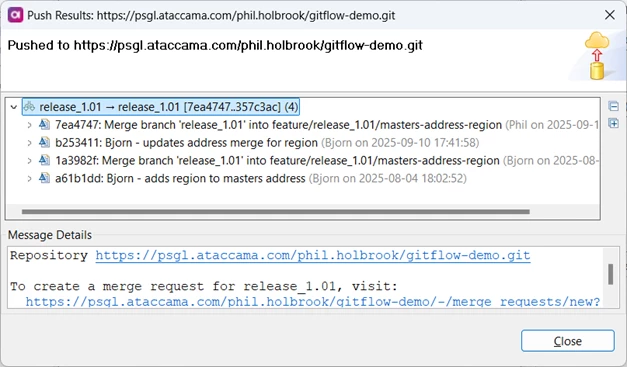
That should be it for the entire release.
Testing and deployment
Bjorn might at this point start up a local copy of MDM server and check that the integration branch starts correctly – although on a larger project he should be doing this frequently with his release branch anyway.
The Integration branch should always be maintained with operational code. This is normally the branch that will be tested on the Dev server, either by deploying it directly to Dev or, more commonly, merging to the Dev branch and deploying that.
Depending on your deployment pipeline, it may be practical to deploy feature branches directly to DEV without merging to the dev branch. If you do this, though, remember that incorrect solution code can prevent the server from starting, affecting everyone using it.
Once the code is unit tested then it’s ready to be deployed to the Test server, if you use one, or to be promoted to Production. In general, for either case you should merge the Integration (release) branch to the Main branch first, and tag that with the new version number.
It is common practice only to merge Main to the Test branch, and best practice only to use Main to merge to Prod. Using other branches as the basis for updating these server branches can work, but it makes the history harder to read.
If you are experienced with Git then you may sometimes wish to use Rebase rather than Merge in order to make the history appear cleaner. However, unless you fully understand why rebase is potentially dangerous and when it is appropriate to use it, then always use merge: it’s safer.
This process involves a lot of switching between branches and merging from a shared branch to a personal one and back again. It’s a little more work than having a whole team work in a single branch, but it allows conflicts to be managed by the person affected, who is most knowledgeable about their impact.
The Gitflow diagram for this development project looks something like this:
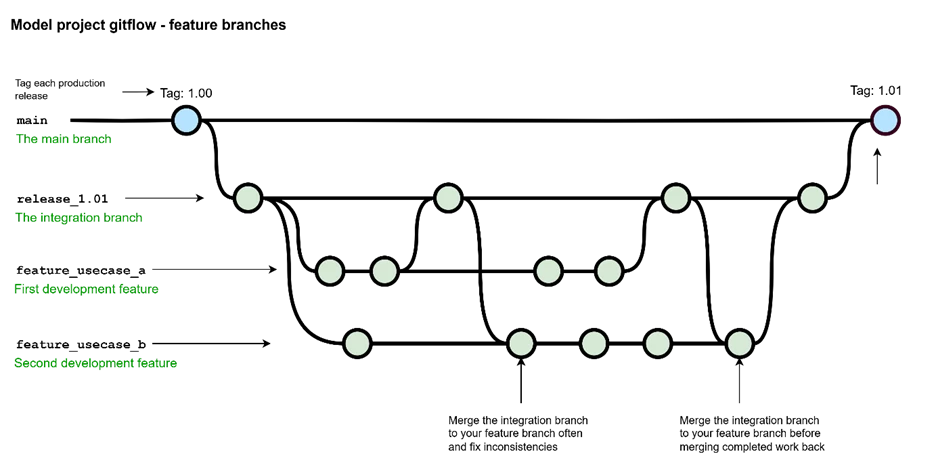
MDM Gitflow Best Practice Summary
- Use an Integration branch
- Create the Integration branch from the Main branch
- Name the branch for the release
- Only have one Integration branch active at a time
- Use Feature branches
- Divide development projects into features
- Create Feature branches from the Integration branch
- Update the Feature branch and resolve conflicts
- Fetch from Origin
- Check out and Pull the Integration branch
- Check out the Feature branch
- Merge the Integration branch
- Resolve git conflicts
- Resolve functional incompatibilities
- Repeat often
- Merge working Feature branch to the Integration branch
- Update the Feature branch and resolve conflicts
- Test MDM localhost server starts
- Check out the Integration branch
- Merge the Feature branch – should be fast forward
- Merge Integration branch to DEV for development testing
- Check out dev branch
- Merge the Integration branch
- Push and deploy the dev branch
- Restart the DEV server
- Merge Integration branch to TEST for integration testing / UAT etc
(not all customers use a TEST environment)- Check out test branch
- Merge the Integration branch
- Push and deploy the test branch
- Restart the TEST server
- Merge Integration branch to main
- Tag this main / integration commit with the release identifier
- Merge main to TEST for final testing
- Merge main to PROD
Finally …
Git best practice is often a matter of opinion. Following the processes in this post will help you maintain your solution, but do you have any experience to share with the community? Any tips?