
Hi community 👋
Curious about what’s new on Data Integration features in v15.1?
We have updates bringing you a streamlined deployment, enhanced customization, and extended capabilities to elevate your data processing experience. Read on to find out more 😎
Self-service deployment in managed Kubernetes
Easily deploy data-processing capabilities to your Kubernetes infrastructure with no manual setup required. Our new entirely self-service update allows you to integrate with the platform's cloud services much more easily. This feature primarily focuses on ease in deployment if you are operating in your own Kubernetes cluster, it also minimizes the amount of data leaving its premises and adding another layer of privacy & security 🔐
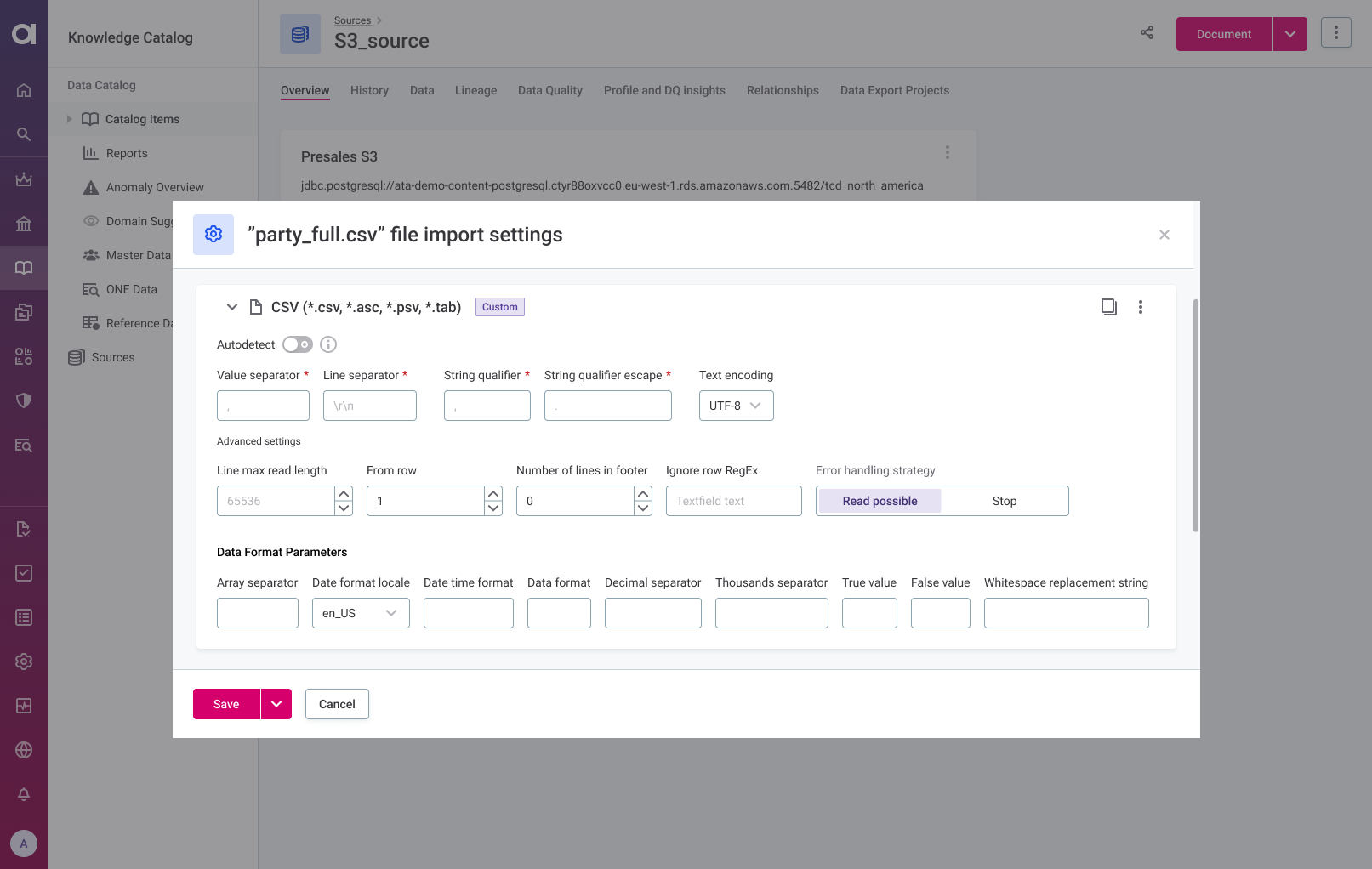
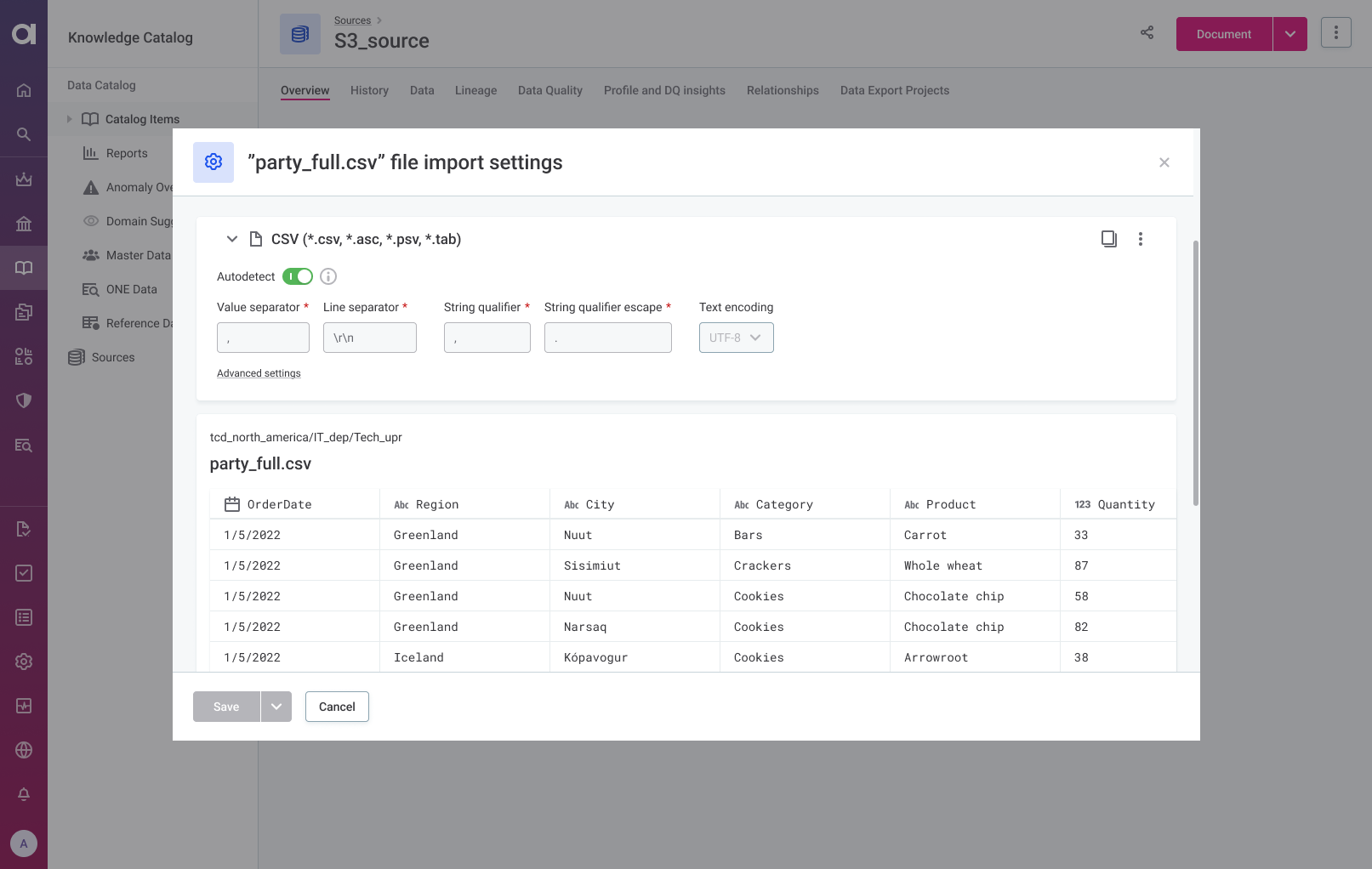
Tailor CSV and Excel file import settings for individual files, folders, or entire connections, providing enhanced flexibility. You can now, populate your Data Catalog with correct metadata or object storage connection and fix the file import options so that every file can be imported and processed correctly each time.
How it works?
Grant access only to the file import settings. Delegate updates and edits on catalog items and the file import settings for the file, any (sub)folder or whole connection. It’s also possible to change the settings for a file while only having the preview of data read with the modified settings.
Orchestration Server updates
We now have more but simplified capabilities for the Portal Orchestration Server enabling additional connectivity to Azure Data Lake Storage 2, Google Cloud Storage, Google Drive, Kafka, and Salesforce.
That’s not all! There is an extended monitoring update with business metrics for workflows, tasks, and plans, including running/max and successful/failed indicators.
Learn more about the improved configurations and file handling and debugging.
Questions? Thoughts? Share them in the comments below 👇