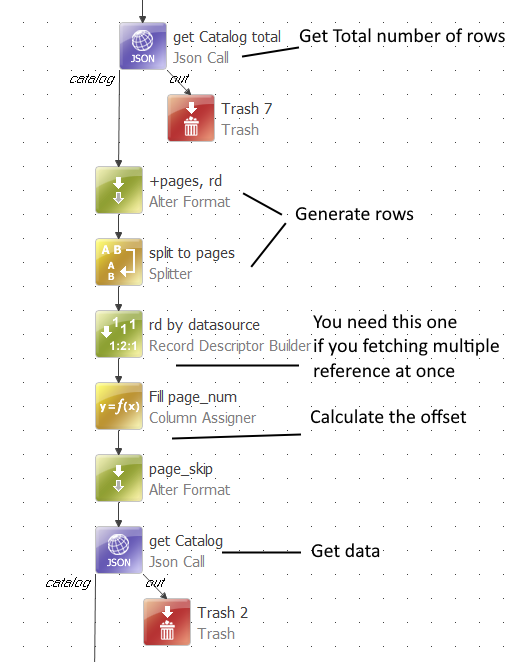
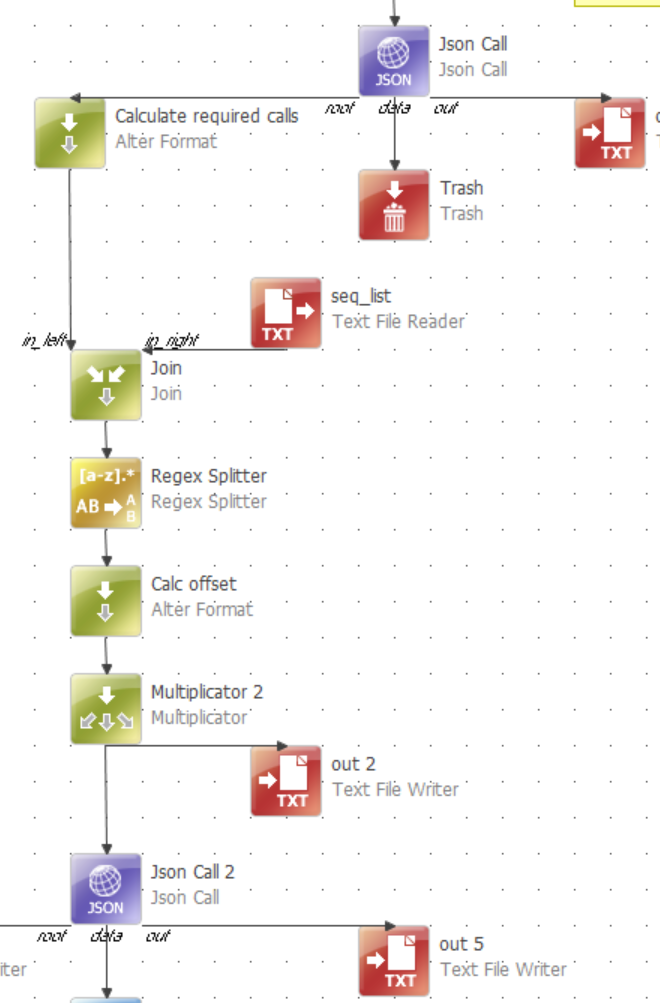
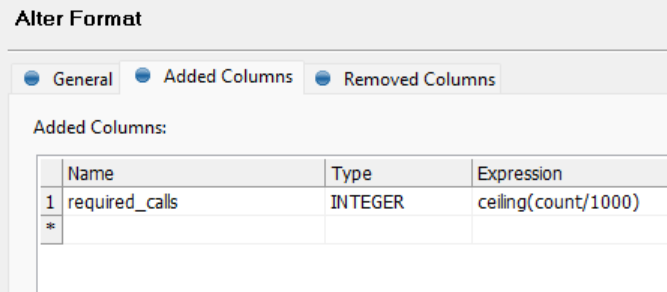
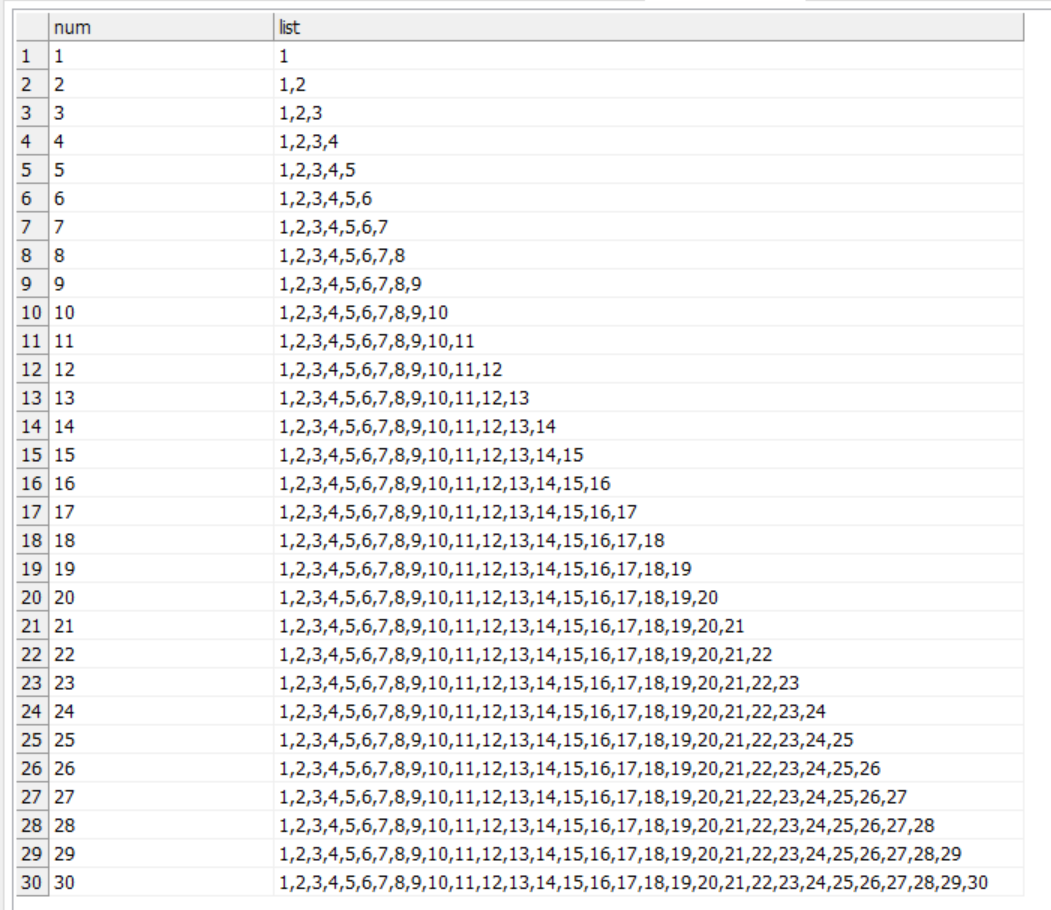
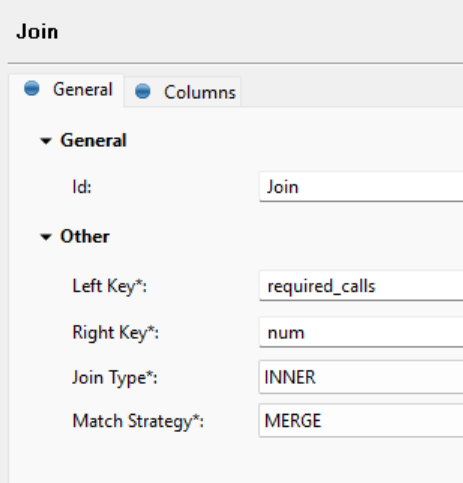
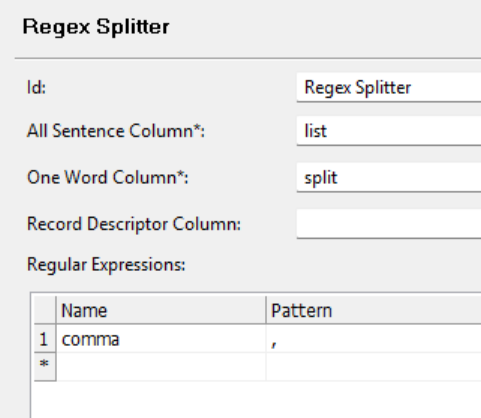
Let’s say I have a table that has 500,000 rows.
I need to query this table using REST API (because I want to get both published records and records still in edited/waiting for publish states).
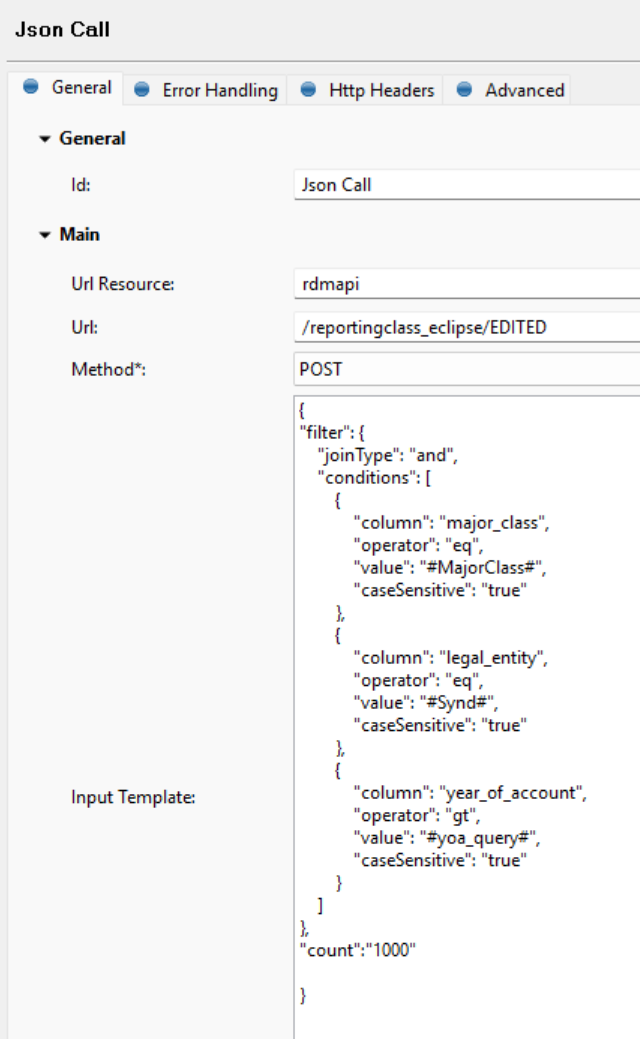
I have some params to filter the data with, but even with params, the result set could be say, 10000.
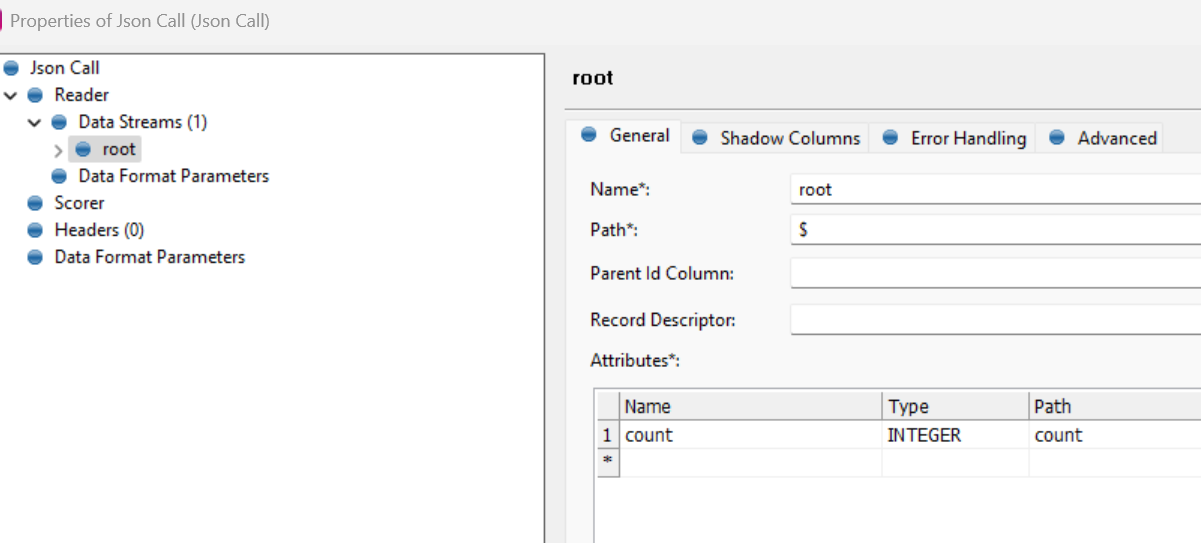
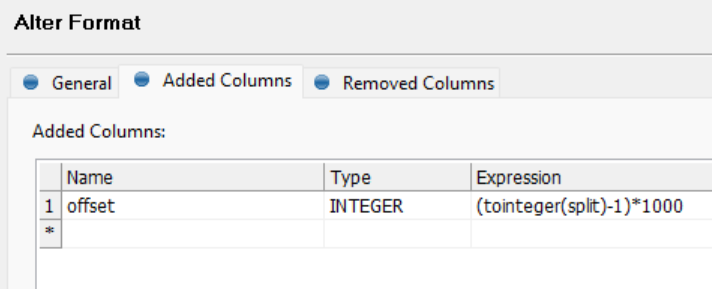
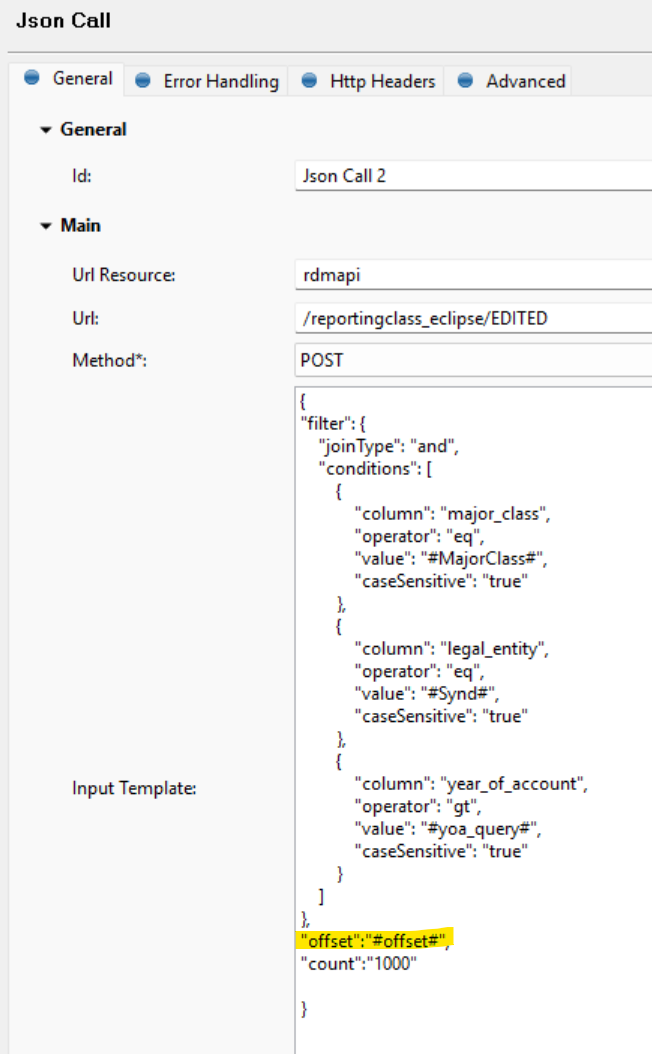
I tried using the REST API using JSON call step in a plan, setting “count” to 10000, and the API says maximum is 1000.
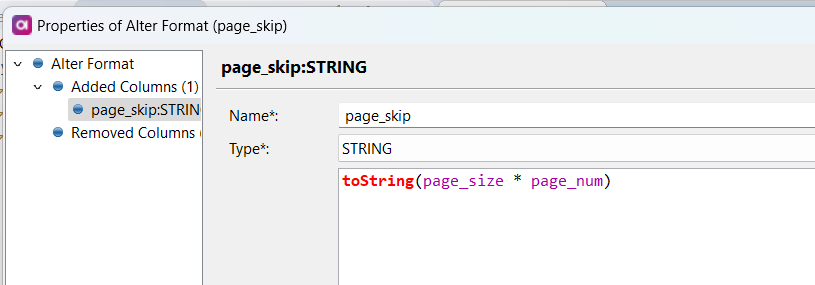
I see that the REST API provides the offset param as well. Is there an example of how I can use that offset param to paginate and query all the records that I will need, but in one plan/component?
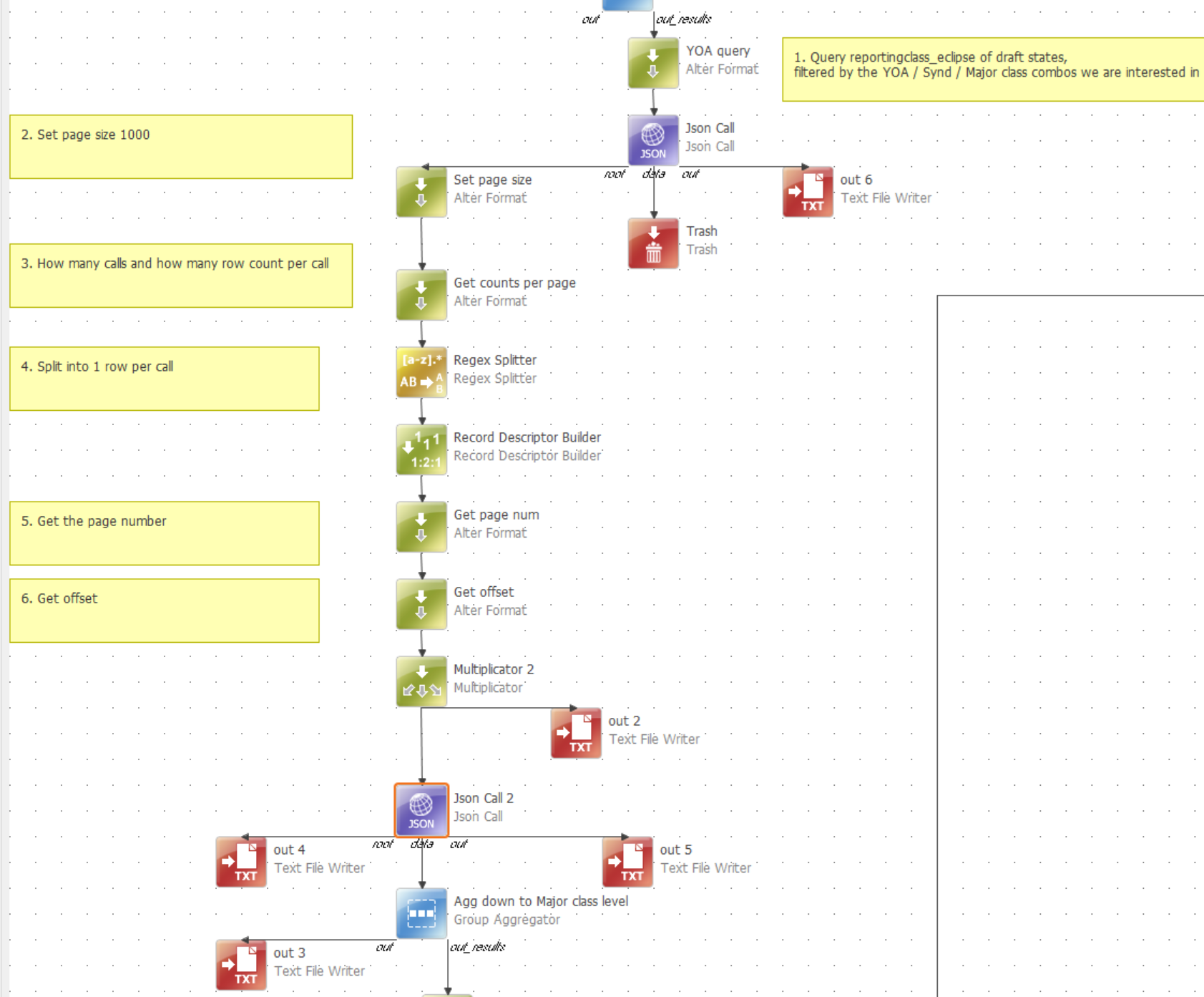
This component will be a part of a complex set of components as a larger operation, and I’d prefer to not have to create an extra .ewf and iterator for it, otherwise this whole thing gets too complicate for anyone else to understand…
Any ideas?