


1 entity Party→ 2 entities (Person/Organization)
or 1 entity Contact → 2 entities (Phone/Email) etc
Pros
Clean Data Model (on attribute level)
In general, we have only columns that are needed for a particular entity (Person) or (Organization). This means that, for example we do see the company_name attribute on the Person records, etc. So in general we have fewer columns in the tables. This could be especially important for the generated MDM native services format (WSDL in SOAP, or all attributes used in the REST API). The consumers of the web services only see attributes per definition of the given model entity and don’t see any irrelevant attributes (similar to the data hiding/encapsulation principle in the Object-Oriented approach).
This can also help minimize the area of impact in case of a required model change (the impact to online API change can be countered with custom .online services exposed as wrappers to the MDM native services keeping the API stable with a fixed set of attributes in each .online method/service version).
Performance
In theory, having fewer attributes on a given entity leads to better performance since the system (MDM or DB) only works with limited width of the record, reducing the overhead of unused attributes. Positively impacted areas should be all transformation plans (cleansing, matching, aggregation, merging, and validation). For example, during the matching group expansion process, the MDM would hit a specific table having fewer attributes and FEWER RECORDS of the given type (assuming we split e.g. Party to Person and Organization even in the INSTANCE layer). In the case of a common entity at the Instance layer and a dedicated set of entities in the master layer, the described performance benefit would only apply to merging and validation operations.
However, the total processed records would remain the same (Person + Organization data), yet we could process them in parallel (using the nme.consolidation.parallel parameter), and a similar approach could be applied to matching a single Party entity having dedicated Person and Organization partitions (using mduPartitionParallelism parameter).
There are currently no specific performance measurements supporting the above statements.
Another positive effect related to performance is the reduced size of the target DB tables improving DB maintenance and DBA operations experience (backup, restore, indexing, tuning, problem analysis).
MDA simplification (Datasets)
Some customers (using in the model one master entity-Party), use datasets to separate Person & Organizations. Now with separate entities(Person & Organization), it would improve the performance in MDA (list-view, datasets, etc)
Delta Exports
We can consume only the type/entity we need without any filtering, so if we are interested only in companies we do not need any filtering, we just export the organization entity. This will also improve the performance in some way. Additionally, if we have data stored in one common party entity and just define delta export operation with a filter (we add the filter as part of the delta export definition) in that sense it will be filtering the type at the database level (as part of the SQL and it will only scan 2 columns instead of just 1: eng_modified_date + cmo_party_type). So it should be comparable from a performance perspective.
Cons
Can NOT move the record from one entity to the other
If we define in Instance layer two entities for Party (Person & Organization) we simply can’t move the record from Person to Organization entity in case we identify it’s a different type during the cleansing process. We must have the correct type defined in the load plans.
In the Instance layer, it is recommended to have one common entity for multiple similar types (e.g. Contact for Phone, Email, LinkedIn; Party for Person, Organization, Entrepreneur, Prospect). This way we can adjust only the record type in the cleansing logic if needed.
Model Complexity
Having more entities means we have more plans and components to maintain. It is better to have a unified entity and distinguish the type within the common entity.
Furthermore, we need to define all the model relationships twice. For example, Person_has_Contact & Organization_has_Contact etc. This applies to all typical CDI entities like Address, Contact, Document, etc, where you need to define not only the relationships twice, but also copy columns in each of those relationships → more complex models with the same amount of data.
1 complete data set(Party_has_Contact) → 1 large operation(CopyColumns) vs 2 data sets(Person_has_Contact & Organization_has_Contact) → 2 operations(CopyColumns) which ideally should be comparable from performance perspective.
Why shouldn’t we have two entities for various scenarios of splitting the party? Maybe it’s better to have just one ?
Scenarios:
- on Instance layer and Master layer - 2 entities Person & Organization for both Instance & Master layers
- on Master layer only - 2 golden entities Person & Organization
- on Master layer only - 1 golden entity Party & 2 Silver entities Person & Organization
Trying to understand whether the disadvantage (change of party type in cleansing) is a big issue or not.
Is it actually common that we change the party type in cleansing?
-Type of the contact -- for sure, party -- not so sure.
-In Insurance: for party it is more common to change the party type.
-In Banking: Changing it for party if we process leads and prospective customers. E.g. The bank may have a prospect "Alexey Ilyin" who is interested in opening an account but after talking with a prospect it happened that he is an individual entrepreneur and it should be a different party type. On the other hand I do not think it is a big issue if we duplicate records about prospects in this case, and I can not imagine to change party type for a real customer at least in banking industry
-If we speak about banking I think party type should be defined in the source, not by cleansing logic. It is just very different onboarding processes in banks for different party types which are driven by legal requirements like KYC
-You can always do it(change the party type) in the load plan. But if the logic to change type depends heavily on other cleansing rules etc, it will be an ugly workaround of course
-Some source systems in the bank didn't have a party type and we had to derive the type from the attributes, it is better to do it in the cleansing rather than in the load
-We never change party type (at least not pers to org) as it's a legal requirement. Separation of instance layers as Individual Entrepreneurs have all attributes from person. So all person-related cleansing and matching logic should be maintained for both entities
Changing the party type or not, might depend on the quality of source data. You might have sources claiming that a record is a private individual but having a company registration number only. It’s a business decision if we can/have to change the type or not. The question is definitely not WHERE or IF we can do it - we definitely CAN. So if the TYPE cleansing is the only advantage of having it in a single table, then it's not that bad. Other aspects might be:
- matching? Always within the party type? Even manual matching would not be possible.
- Different cleansing logic for the same attributes e.g. first name, last name, etc.,? We can use the same components for that.
- MDA templates? You can't see ALL party records in one table / is that an issue?
- APIs? Requests based on a party type is not a big issue
- Exports from different tables - not a big issue
- ... anything else?
In all cases we may have different answers for different industries.
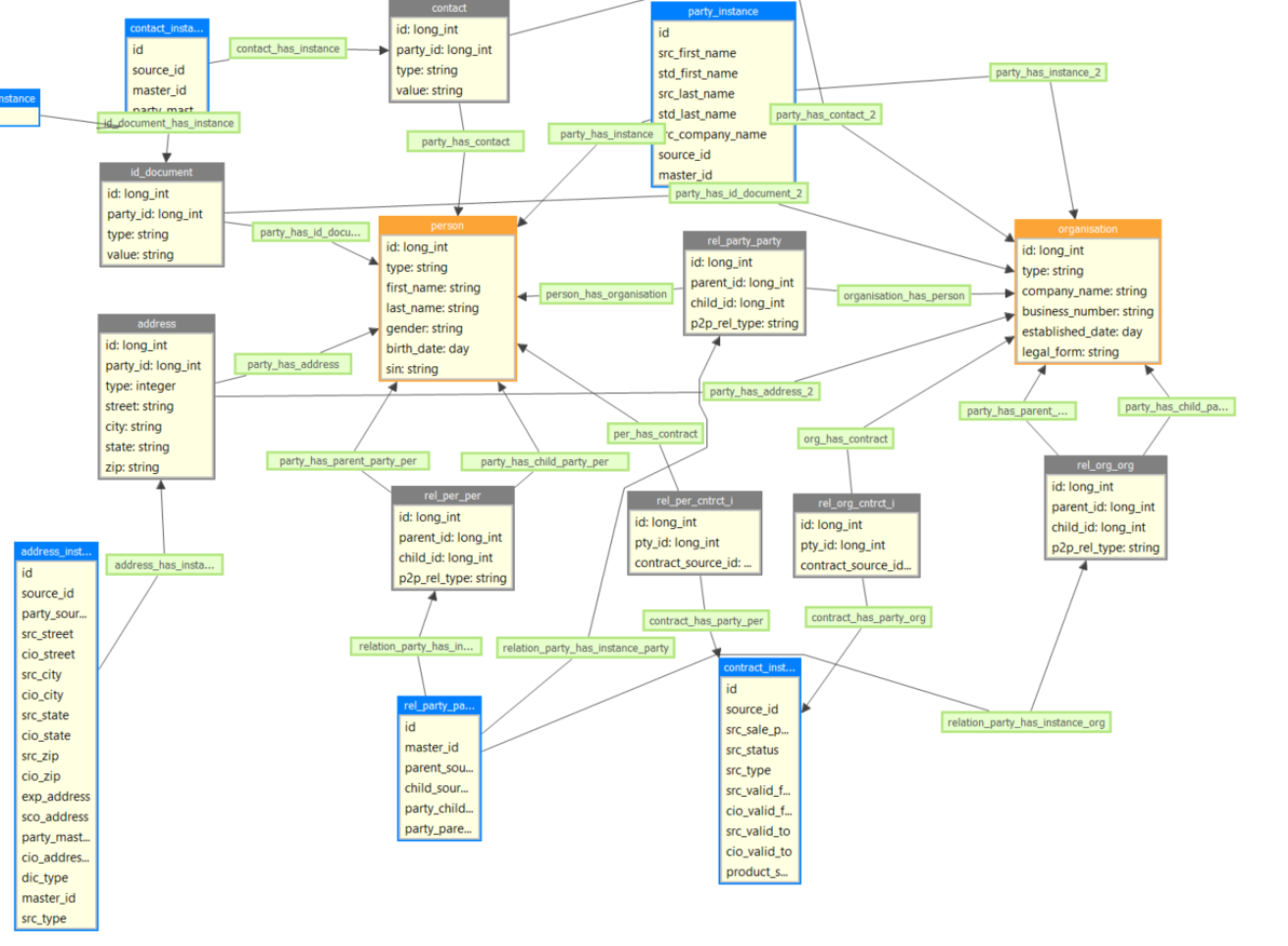
1. On Instance layer and Master layer - 2 entities Person & Organization for BOTH Instance & Master layers
Having separate entities for party or contact entities in Instance entity is definitely not recommended for some of the reasons mentioned above. In the instance layer we need a flexibly simple data model which will capture the Source as Instance and then create our master layer. In master layer is different, there are other reasons(pros/cons) for having it separate.
Instance layer:
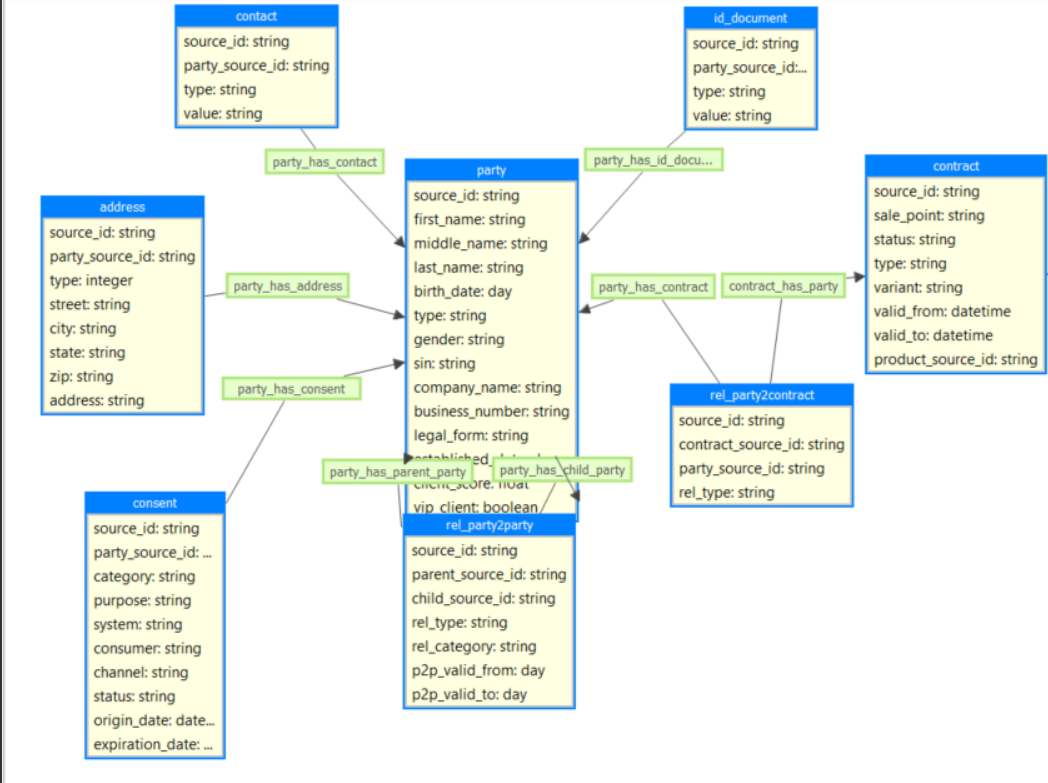
The correct way to do it in master layer dependence on various business/technical requirements such as “Views” in MDA or ways of exporting the data to downstream systems etc. Also it’s dependent on the industry etc.
Below are the 2 possible ways to modify the Master Layer with separate entities.
2. On Master layer ONLY - 2 golden entities Person & Organization
master layer:
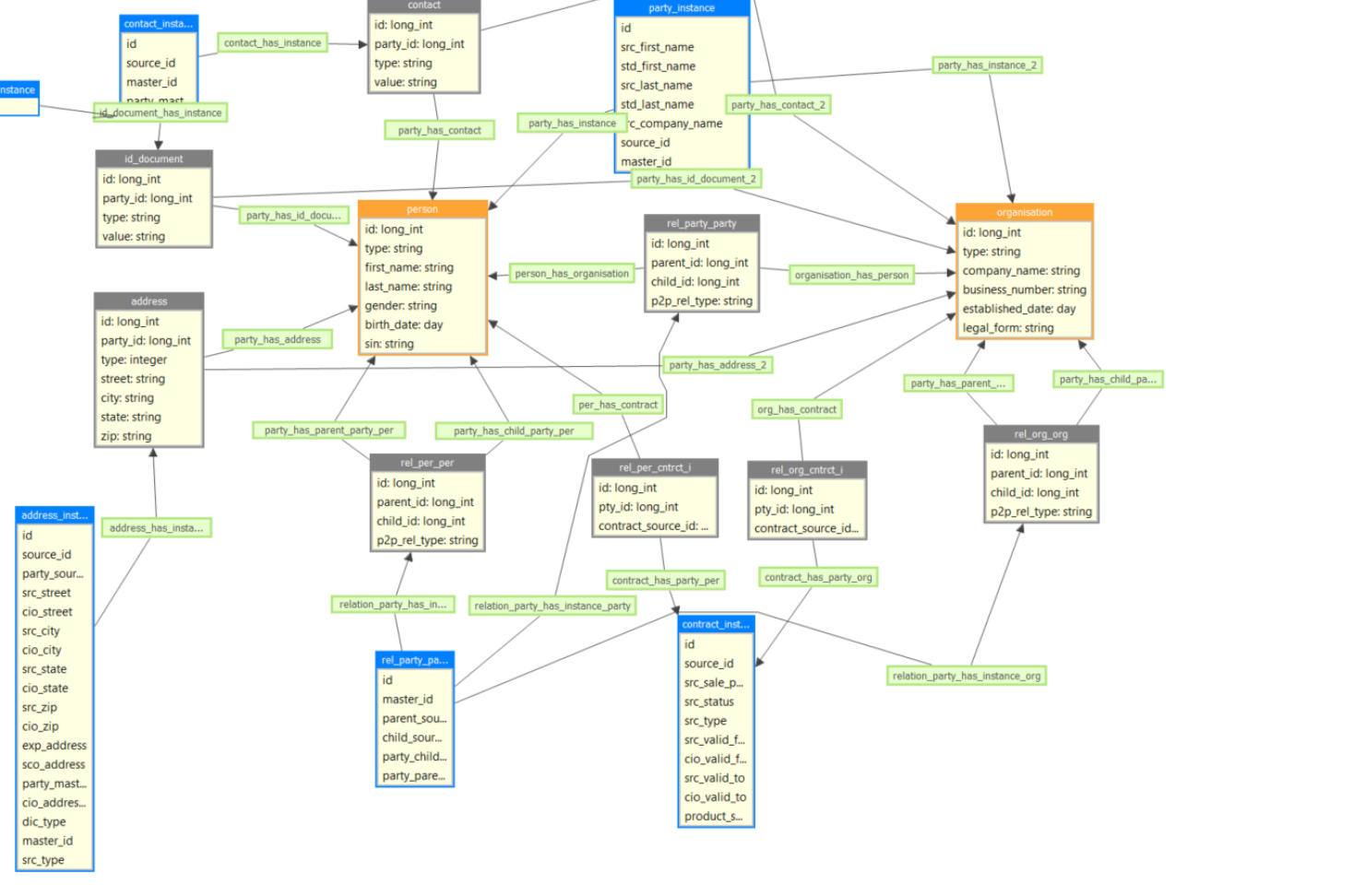
In Instance layer and in Party Instance entity for Consolidation: we keep 1 Party entity in Instance and use CopyColumns to related entities for the matching etc. Then we create the master record(per or org) based on the type. One of the biggest disadvantages as mentioned above is that we can’t change the person record to organization record.
Also manual matching would not be possible.
3. On Master layer ONLY - 1 golden entity Party & 2 Silver entities Person & Organization
master layer:
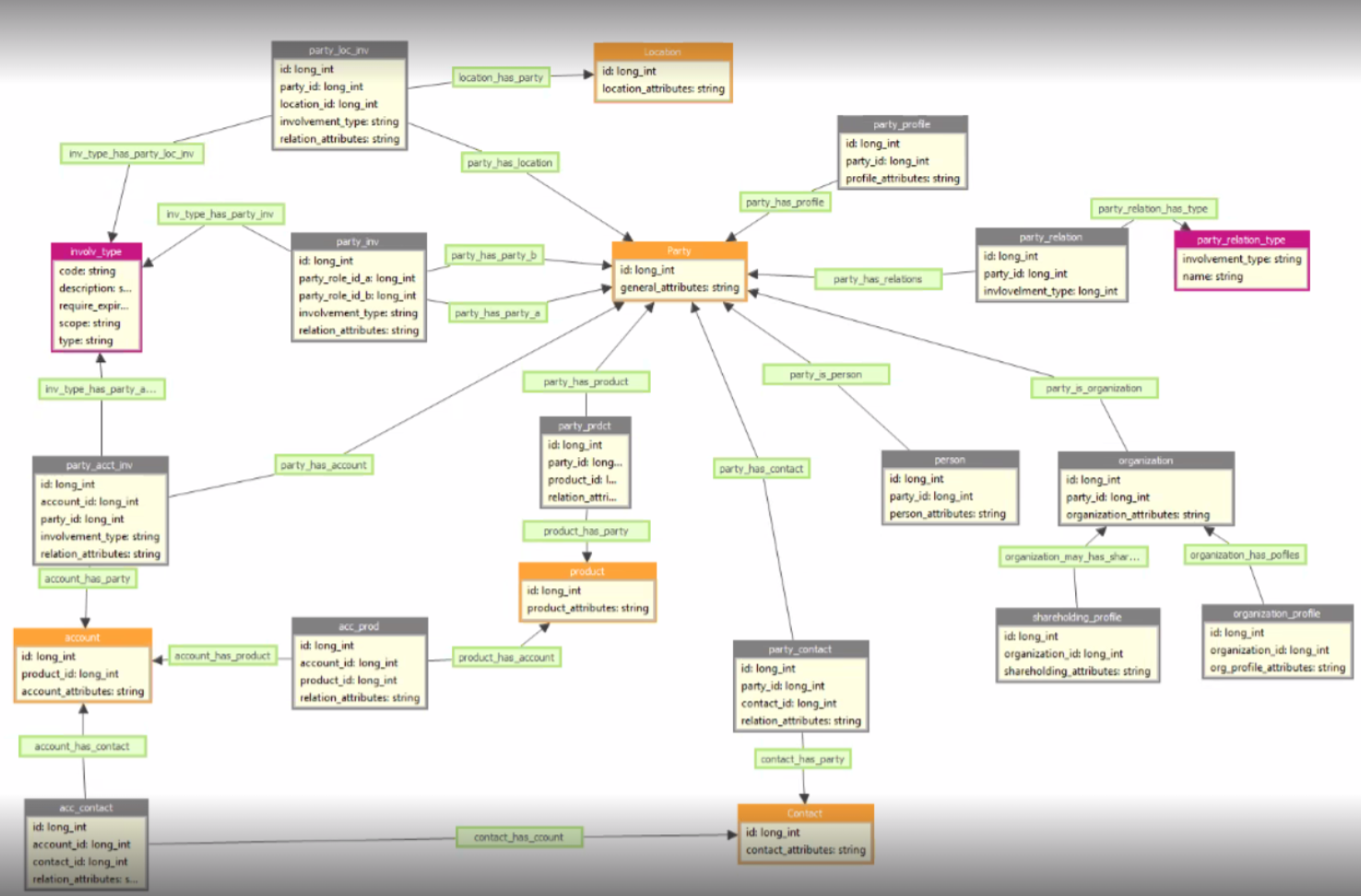
Similar with above, we keep 1 Party entity in Instance and then in master we create Master Party entity.
We have 3 entities in master: Party(as a generic parent) and using inheritance for the Person & Organization entities where we have only person related attributes in Person entity, only organization related attributes in Organization entity. In Instance we have only 1 Party entity. All 3 entities are using the same master_id from instance layer.
Not obvious benefits of having the party split in 2 entities because of difficulties when you do merges or splits. From mdm context it doesn’t make much sense.
In mixed style, In Master entity for matching: using copy columns from party_profile to organization is not possible(example model above, model complexity)
Conclusion
Questions need to be considered before making the final decision for the model:
How to work with the records in mdc?
How will we have it in MDM web application ?
