



Hello everyone, I am Abir 👋. I am a Principal Consultant at Ataccama. I have recently worked on a project where I had to explore how IDs in Ataccama MDM work, what to consider if any customization is required from the default behavior and how to utilize the dedicated ID sequence feature. I will share in this post what I have learned from MDM gurus and from the overall experience when implementing a custom solution for anyone else venturing into the same journey.
Understanding IDs in MDM
MDM generates IDs for columns such as id, master_id, xid, tid, etc. utilizing a database sequence created based on the model definition. When an MDM process creates new records, it fetches the NEXTVAL value from this sequence, multiplies it by 1000, and generates and assigns IDs to the new records. Once the MDM process is completed, using the maximum ID value assigned, the sequence is updated for the next MDM process. The sequence is cached in Java (for performance reasons) during this process, this is why an engine restart sets the NEXTVAL value to the next hundred, for example 4568 → 4600.
Generally, it is strongly not recommended to manipulate the sequence in an MDM database because any misstep can destroy the data integrity and corrupt the database which will lead to all data loss. However, if there is a necessary requirement for IDs to begin with a specific offset value because of external factors, it is possible to change the sequence NEXTVAL value so that the IDs are generated from a specific value.
This can be done by altering the NEXTVAL value of the sequence and setting it to a value of the offset divided by 1000. Alter by running the following SQL command below in the MDM database followed by MDM server restart.
ALTER SEQUENCE <schema_name>.<sequence_name> RESTART WITH <offset_value>;To reiterate again, doing this can be a fatal risk for the entire MDM system. Therefore it is strongly advised to seek consultation from Ataccama Professional Services before and while doing so.
❗The Risk
MDM engine does not check if the sequence value is in line with existing ID values, i.e. it assumes the sequence is set correctly. If the sequence value is manually adjusted and set lower than a currently existing ID, the engine will pick up this lower sequence to generate IDs. When the generated IDs start coinciding with values that already exist in the database, there will not be a failure but existing records will get overwritten by the newly processed records. This will completely compromise related records pointing to overwritten records and consequently corrupt the entire database and cause serious issues.
Common ID Sequence
As mentioned above, MDM utilizes a database sequence to generate IDs. By default, MDM creates a common sequence that is used by all MDM objects. A common sequence is named as <prefix>id_seq and stores the maximum sequence value assigned to any of the records.
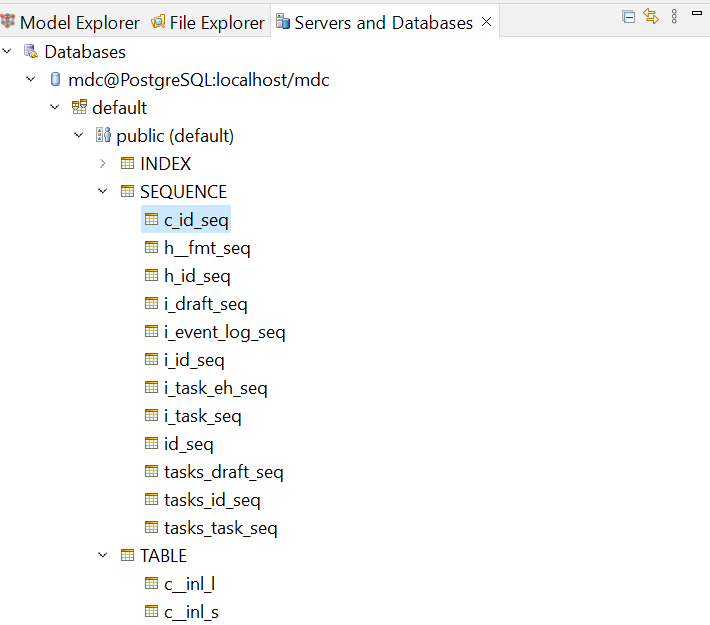
For example, maximum IDs in the database are 89,645, the NEXTVAL value in the sequence would be 90 so that next process can generate IDs from 90,000 and above.
This is why it is perfectly normal to observe gaps in IDs in any one particular entity table. Also, when authoring records on the WebApp the preview uses ID from the sequence but does not commit and thereby creates gaps.
In some cases, a common sequence may cause issues because the IDs will create large gaps and the length of the ID value will also increase quickly and any downstream applications consuming these IDs may have limitations for the length of this value. This is particularly problematic when the sequence is altered to begin with an already large value.
Here are some pros and cons of Common ID Sequence setup.
✅ Pros:
- Resource Efficiency: Common sequence consumes fewer resources as multiple applications or tables can use the same sequence object. This can be beneficial in environments with limited resources.
- Simplified Management: Single sequence object to manage, making administration easier.
- Reduced Storage: Common sequence typically requires less storage space than multiple dedicated sequences.
❎ Cons:
- Performance Bottlenecks: In high-concurrency scenarios, common sequence can become a performance bottleneck as multiple processes contend for the same resource.
- Limited Flexibility: All applications using the common sequence must adhere to the same settings.
- Dependency Risk: If a common sequence experiences an issue, it can impact multiple applications or tables relying on it.
Dedicated ID Sequence
To mitigate issues arising from using a common sequence for IDs in MDM, we can use a feature that allows the MDM engine to create and use dedicated ID sequences for each master entity. This is done by checking the Dedicated Grouping ID Sequence checkbox on the Advanced Settings tab of a master entity.
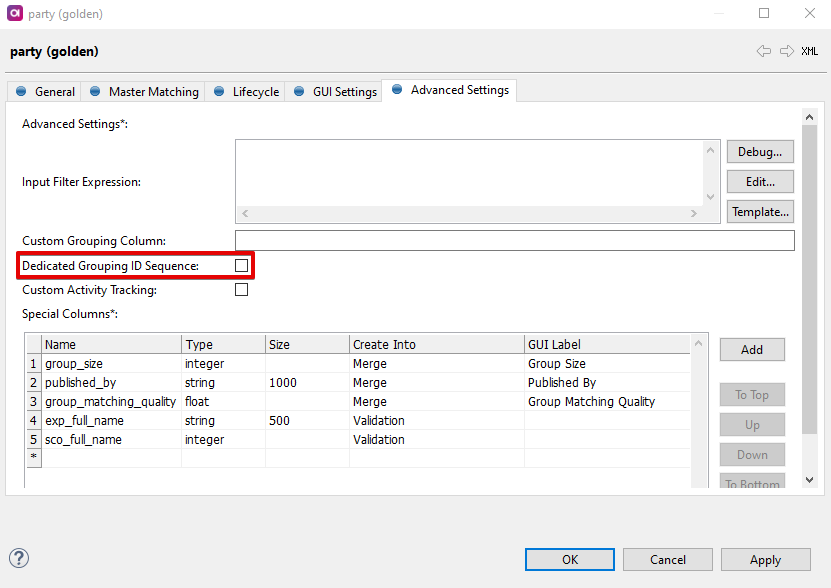
When this feature is used, it will significantly reduce gaps in ID values because ID values are not shared amongst all entities within the MDM model. Note, it will not completely eliminate all gaps between the values because of caching mechanisms and WebApp previews as discussed above.
Each master entity (golden/silver) can be configured individually to enable its own dedicated ID sequence. When one or more dedicated sequences are enabled, they are created in the MDM schema as separate sequences named as <prefix>mid_<master_table_name>_<master_layer_name> in addition to the common sequence.
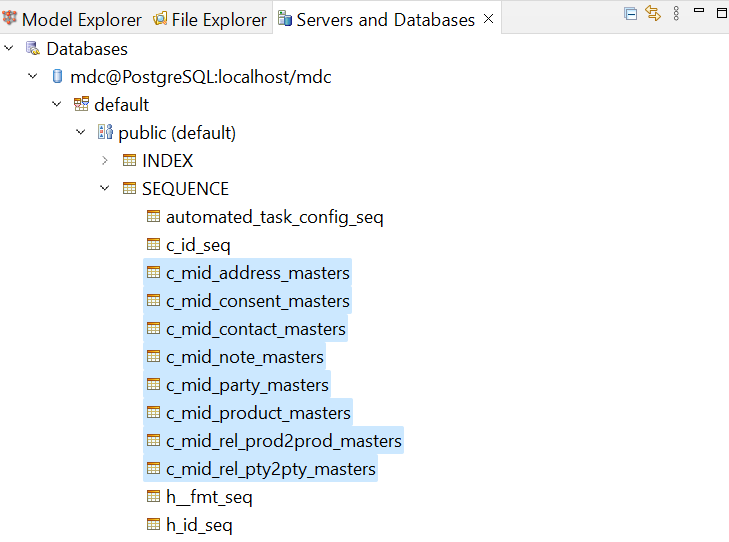
🚩 Important
If the dedicated ID sequence is enabled after there is existing data, we also have to alter the DB sequence to ensure the subsequent IDs are generated in higher values than already used.
📜 Steps for enabling dedicated ID sequences
- Check Dedicated Grouping ID Sequence option for each master entity
- Save, Reload and Generate configuration files
- Deploy configuration files
- Restart MDM server
- Verify new sequences are created
If sequence needs to be offset or there is existing data: - Ensure there is no MDM operation running until all steps are completed
- Stop MDM server (MDM server must be stopped before a database sequence is altered)
- Alter new dedicated sequences to offset value divided by 1000 rounded up (offset value must be greater than existing maximum ID value)
- Restart MDM
- Resume MDM operations
How to Choose between Common and Dedicated Sequence
If it is not clear when to consider using dedicated sequences, see below for some guidelines to consider.
| Common Sequence | Dedicated Sequences |
|
|
💡 Key Considerations
- Database System: The specific database system in use might have optimizations or limitations that influence the performance and behavior of sequences.
- Application Requirements: Carefully consider the specific requirements of the applications regarding performance, concurrency, and fault tolerance.
In conclusion, choosing between a common and dedicated ID sequence depends on factors such as transaction volume, management preferences, and security requirements. While common sequences offer resource efficiency and simplified management, dedicated sequences provide granular control, fault tolerance, and isolation. Careful consideration of database system optimizations and application requirements is crucial in making an informed decision. Keep in mind by default MDM uses common sequence and it is the recommended approach.
For further information on implementing dedicated ID sequences, refer to the documentation page here.
If you have any questions, please let me know in the comments below!
