I am reading from collibra using collibra reader, some data has html tags like - <p> , <div> in it. Is there a way where we can filter out the html tags if its present in the data. like strip html tags like that.
Let me know if more information is needed.
Thanks.
Best answer by Samuel Muvdi
Hi!
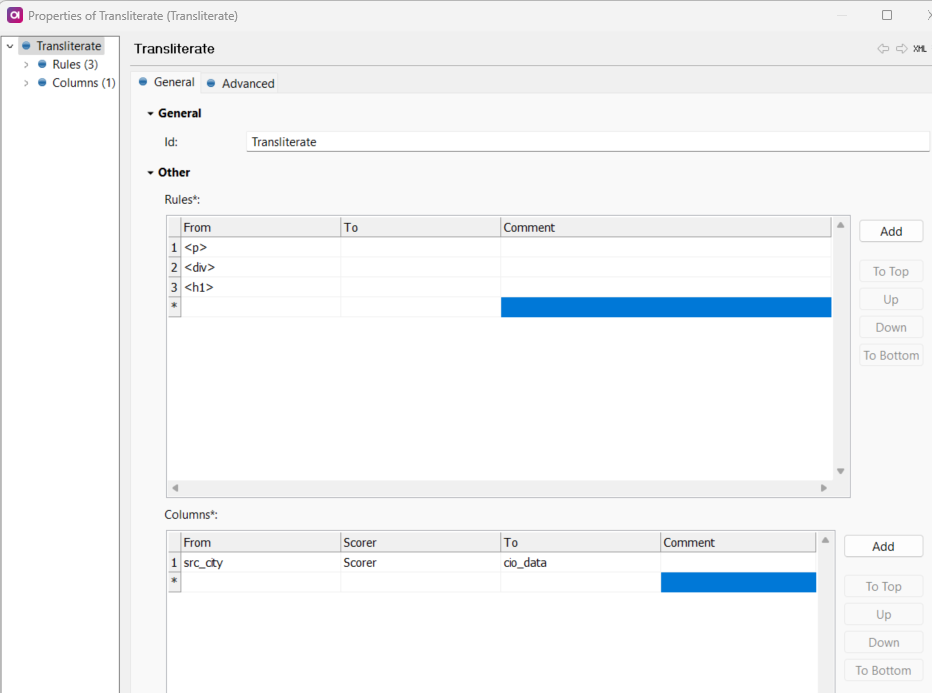
For removing html tags, I would recommend using either a transliterate step or a regex matching step.
Using the transliterate step you can do something like this:
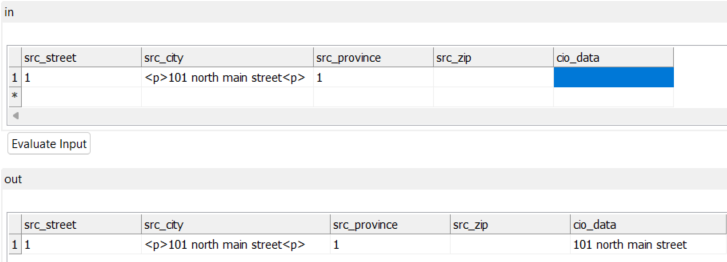
And then when you test this out you should see that we removed the <p><p> tags in the cio_data column
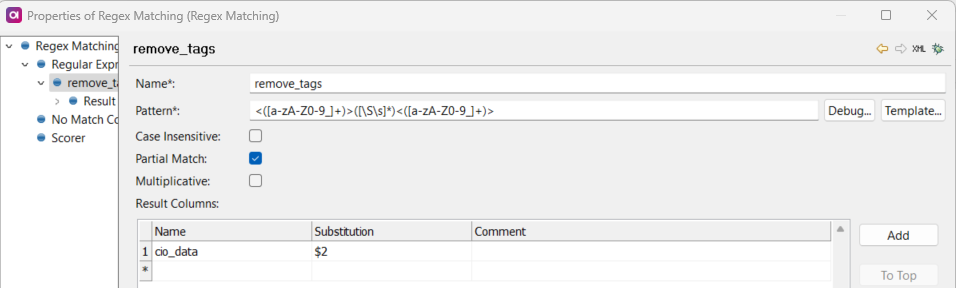
The other way you can achieve this (I think the faster method) would be to use the regex matching step like so
When testing this out, we can see that it gives us just the data between the tags and no tags
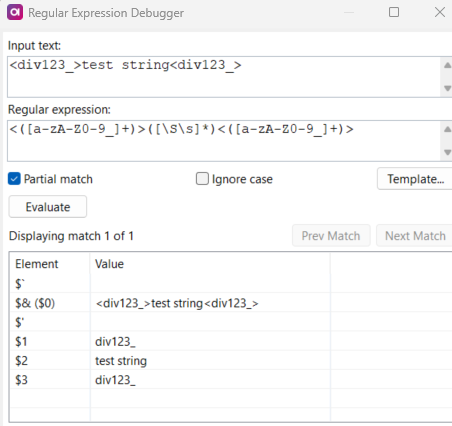
<([a-zA-Z0-9_]+)>([\S\s]*)<([a-zA-Z0-9_]+)>
We can then see that $2 takes in our data without tags :)
Hi @Karthikeyan, I’m closing this thread for now. If you have any follow-up questions please feel free to share them in the comments or create a new post 🙋♀️
We use 3 different kinds of cookies. You can choose which cookies you want to accept. We need basic cookies to make this site work, therefore these are the minimum you can select. Learn more about our cookies.