




Hi everyone, me again 😊 I work as a professional services consultant in Ataccama and I prepared another article for you, this time about some recommendations for integration with git, mainly for self-managed deployments. Specifically, when you have the DQG suite and you want to integrate your orchestration server. You can probably reuse some of these recommendations for other modules as well.
Before you start reading, please note that I reused some of the already existing articles:
I also recommend checking out this article in our documentation for working with git in our IDE:
https://docs.ataccama.com/one-desktop/latest/projects/git.html#introduction-to-git-and-egit
Also please note, that this article doesn’t cover how to work with git in general, but more on how to work with the Ataccama projects, what files to version, what to look out for etc.
Recommended file structure
Let’s start with the recommended file structure, which is usually already prepared for you during installation. Following is the recommended file structure for the orchestration server:
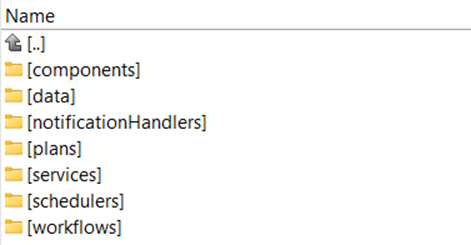
- components contain Ataccama component files (.comp)
- data – usually contains subfolders:
- in (input data)
- out (output data)
- notificationHandlers – contains the definition of notification handlers (.noth files)
- plans – contains Ataccama plan (.plan)
- services – contains definition files for online services (.online files)
- schedulers – holds Ataccama scheduler files (.sch)
- workflows – contains the definition of workflows (.ewf)
These are the basic folders recommended by Ataccama.
Folders for workflows and schedulers are defined inside serverConfig file of the orchestration server as part of the Workflow/Scheduler Component. Make sure you don’t move those folders
As part of the file structure can be the server configuration folder, usually called /etc, that keeps the server configuration files (serverConfig and runtimeConfig).
You can create additional folders based on your needs, for instance for different features (“projects”) you can create subfolders inside the main folders. This helps the different teams to maintain and easily navigate between the different project-specific items. However, since for workflows and schedulers, the path to these files is specified in the serverConfig, in case of multiple project folders it is needed to use different sourceConfigBean definitions in the configuration pointing to different folders with different workflows (see more in the documentation).
What to version
There are several general best practices/recommendations:
- Git shouldn’t keep data files.
- That means the whole /data folders should be put to .gitignore (see below), but keep the .gitkeep file inside to keep the folder structure inside the git repository.
- If you use a git-flow to promote code between environments, make sure you don’t keep the environment-specific configuration files inside these branches (or git in general)
- For Ataccama, this means the serverConfig and runtimeConfig shouldn’t be versioned).
All the other files is good to keep in a git repository.
There are additional recommendations for the git repository.
.gitattributes
The file provides a possibility to control certain operations in the git repository. Especially it is important to keep the line endings (prevents Git from normalizing them) as provided in the Ataccama default Eclipse Project content because:
- Prevents the "The project signature is invalid" issue resulting into a state when you are not able to see/work with the Project at all (entire project tree is not visible).
- Prevents from false reported changes in generated files - when generating files like components, plans, workflows, etc. the line endings should not differ from the remote repo no matter what OS you use to run the ONE Desktop (Eclipse).
The recommended setting is to make sure you follow these steps before you push any Eclipse Project (RDM, MDM, etc.) into the git repo for the first time:
- Create an empty repository and push it to remote (or if you already have an empty remote repository, just clone it to your local computer).
- Create the .gitattributes file with following content: * -text
- Push the file to the remote origin (this is important to do before anybody else will do their first checkout of the repository).
- Now you can add the Eclipse Project to the repository and work normally (push it to the remote origin, i.e. share it , etc.).
Of course, you can skip this procedure if you have the .gitattributes with the mentioned setting already as a part of the content (along with the Ataccama Eclipse Project) being pushed to the repository. Important is that this file becomes part of the repository before anyone else starts working with it (i.e. checking out from the remote origin).
.gitignore
It is recommended to avoid keeping certain project files from the git repository, such as:
- Generated lookups: binary files (diff makes not much sense) which are generated upon request/via orchestration which is typically scheduled on the server where the full solution is running, not your local computer.
- Large source files: can be text files but their size would make git repo to grow excessively; moreover again, as a part of the orchestration, they might be part of some download process on the server.
Also, you can define exceptions here if needed. Example how to ask git to ignore all the lookup files in the lkp directory:
!RDM_lab/Files/data/lkp/
RDM_lab/Files/data/lkp/**/*.lkp
!RDM_lab/Files/data/lkp/___country_preferred_out_language.lkp
Recommended git flows
It is a good practice to have one branch per environment (e.g. test and prod), feature branches for the implementation of the features, and if needed, additional branches (master/hotfix, …).
Depending on your needs, in general, you can choose one of the approaches:
Standard dev to prod promotion
You can develop your code in a test branch, deploy it to dev environment and once tested, merge the code into the prod branch which is being deployed on the production environment.
In this approach, make sure your branches don’t contain the configuration files mentioned in the previous sections. In this case, the configuration files have to be placed elsewhere, or maintained by the system administrators separately. When merging the branches, you would overwrite the configuration of the environments.
In this case, the git flow is quite standard and no special flow is needed than what you are used to from other code development.
Promotion through module branches
You can develop in a branch called e.g. orch-main, once tested on your local environment, you can merge the branch into a test branch. Once tested in test, you can merge the orch-main into prod.
If you choose this approach, the orch-main branch can’t contain the configuration, the configuration is kept purely inside the environment branches (test and prod) and if changes are needed in the configuration, they are done directly inside those branches.
When creating this setup, first, you create the module branch with the file structures (without configuration files stored e.g. in the /etc folder), then you create an empty environment branch (e.g. test), merge the module branch into it, and on top of that, you create the configuration files inside. Like this, you make sure that the configuration never existed inside the module branch and git won’t delete it the next time you merge the module branch into the environment branch.
The regular git-flow can be then described like this):
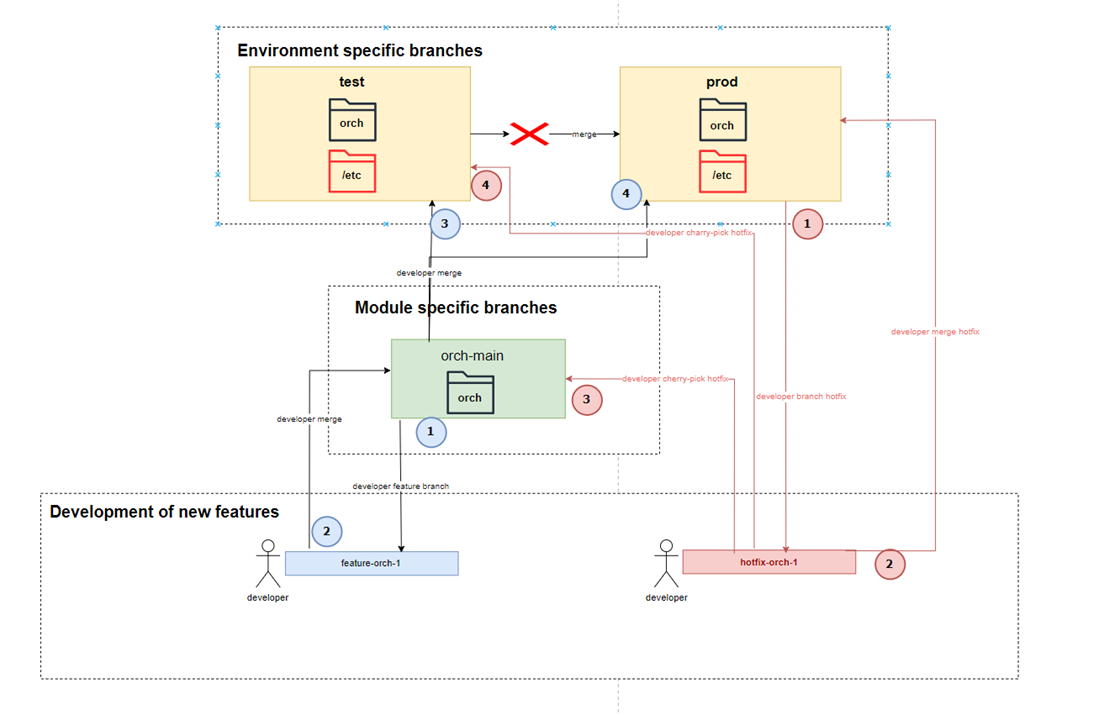
The folder “orch” indicates the versioned files (plans, workflows, …), the /etc folder contains the configuration files.
The blue numbered black lines represent the standard flow during development, and the red lines and numbers represent the flow for handling hotfixes on the production branch.
Regular Development
It is necessary to differentiate between two scenarios:
- Project development
- Update of the runtime folders
Project development
The flow can be simply described as such:
- A developer creates a new feature branch for the module that he is planning to develop (e.g. for orch-main, he creates a branch feature-orch-1).
- Once the feature is finished, it is merged back into the main module branch (e.g. orch-main) and merged into the test environment branch for testing.
- Once tested, the orch-main is merged into prod.
It is expected that in case multiple developers work on the same module in different feature branches, they will handle any potential conflicts before merging their feature into the module main branch as a standard practice. One recommendation is to do a regular rebase from the main module branch during development in the feature branch to avoid massive conflicts before the final merge.
In case only one developer works on the module, the development can be done directly inside the module branch (without the necessity to use feature branches). This should be considered by each developer.
It is FORBIDDEN to do merge directly between test and prod branches (due to different content inside the configuration files) !!
Update of runtime properties
As configuration files are present only in the environment branch and because it is expected that changes in these files will be minimal, the changes should be done directly inside the environment branches. The simple flow is then:
- Check out the specific environment branch that requires changes in the runtime properties.
- Do the changes locally.
- Push the changes into the remote and restart the necessary server(s).
As stated above, do NOT merge the changes between dev, test, and prod!
Hotfixes
Hotfixes are a special case in which the following flow needs to be respected to ensure that the fix is propagated quickly back into PROD but at the same time, the fix will get propagated to the specific module branch(es) as well as into DEV (and TEST).
Refer to the diagram above, the red lines indicate a flow for resolving hotfixes.
Apply fix on production
The fix the issue on production, the following flow is recommended:
- Fork a branch from the current production to fix the issue, e.g. hotfix-orch-1.
- Once the issue is fixed, merge the hotfix branch back to production.
In this case the hotfix branch contains the configuration files (as well as all the module branches if applicable)!
Propagate the fix to other branches
When propagating the fix back, users have to be cautious as the hotfix branch is a clone of production and cannot be directly merged to the module branch. It is recommended to use cherry-pick to grab only the specific commit:
- Cherry-pick the fix commit from the hotfix branch into the relevant module branch (it is expected that the issue is occurring only in one specific module).
- Cherry-pick the fix commit into test branch (you cannot merge it from prod or the hotfix branch as the versions of the code in these environments will most likely differ from production).
How to integrate the git repository with the server
In case the first git-flow approach is chosen, it is recommended to clone the git repository on the server elsewhere than the target files that the server is reading from. The reason is the configuration, which is part of the folder structure (the /etc folder).
As part of the deployment pipeline, a script would be prepared that would:
- Pull from the git the latest changes.
- Stop the server.
- Synchronize (or copy) the changes (you can also back up the old configuration) to the target destination.
- Restart the server[1].
For synchronizing the changes, you can also use the rsync command with –-delete to only grab the changes (and remove deleted files).
In the second scenario (with the module and environment branches), your server could read directly from the git workspace à in this case, it is important to keep in mind that even without restarting the server, most of the changes to the files (e.g. plans and workflows) are grabbed instantly by the server!
Pre-test and post-test
There are a few tests you can run on the changed files to ensure the server will start:
- The XML of the configuration files (inside /etc) is valid
- All path variables and file paths defined in both files are valid (folder exists on the server)
Additional tests can be done after the server starts:
- Check the server status to see if it’s running.
- Check that all workflows, schedulers and online services are visible and in the state “OK”.
From the functional perspective, unless the workflows are triggered and run on the server, it is not possible to verify there is no issue (a plan can be valid and successfully tested on the local environment, but can have issues running from the server (networking problems, …).
Resources
- https://docs.ataccama.com/runtime-server/14.5.x/one-runtime-server.html
- https://docs.ataccama.com/runtime-server/14.5.x/server-components.html
- https://docs.ataccama.com/runtime-server/14.5.x/runtime-config-component.html
- https://www.atlassian.com/git/tutorials/comparing-workflows/gitflow-workflow
[1] The restart of the server is not always necessary (e.g. changes of the components are reflected immediately), but it is recommended to do it always not to distinguish between different types of changes.


