The performance of one of the subject is bad. This what is happening.
A new or existing records loaded and it runs matching against 1000 records (one master and 999 slaves) because they are similar and have same master_id 123. So if we think of overall if 500 records are loaded during an incremental load and each have similar conditions, its ending up touching 500000 records and taking several hours. IS there a way to make the record only try to match against the Master record? or other ways to improve the performance? Please suggest. Thank you.
Partitions are the means to define groups of records that should not be matched together. For example, records in Partition 1, can not be matched to records in Partition 2 or 3 or 4 etc.
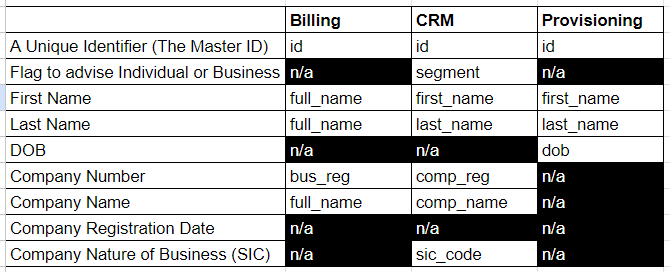
May I ask what business domain the data is that you are trying to match together? Is it Party (Individuals / Business), Address, Contact, Product etc.I see that you use the attribute ‘name’ in your example, so I will assume a party dataset containing individuals or businesses.
We’ll start by understanding the data in the various source systems that are to be matched together.
There are 3 source systems that we need to match data across;
Billing
CRM
Provisioning
Taking a top-down approach, we’ll define the attributes (columns) that we need in the master layer (our final output).
For Individuals
Flag
First Name
Last Name
DOB
For Companies
Flag
Company Number
Company Name
Company Reg Date
Company SIC
We’ll then impact assess our input data from each source system against those output column requirements.
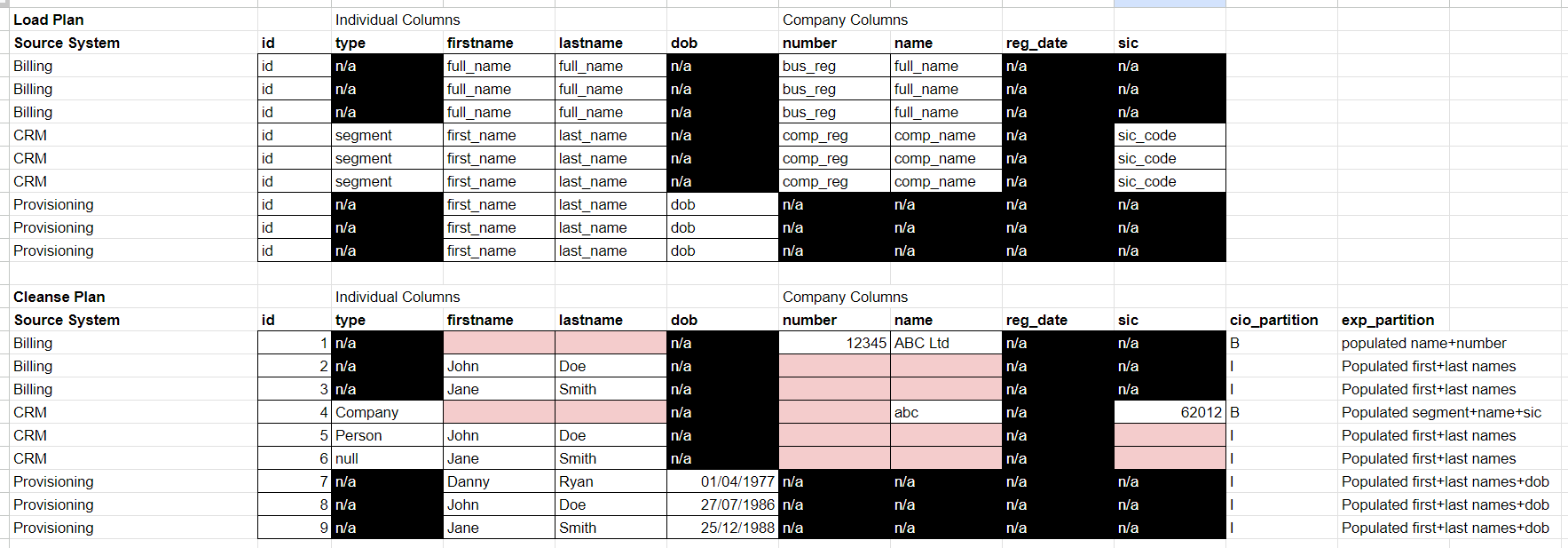
Therefore it make sense for our partitions to be;
Individual
Business
We need to remember that records that are not partitions will never be matched. Therefore one of the goals of mastering the data, is to identify issues at source that can be remediated, then once remediated will be assigned to one of the partitions on a subsequent load.
Skipping over Loading the data, lets cleanse the data (for just the partition)
After some data cleansing, we have some level of confidence that record ids 1 and 4 are business, whilst the rest are individual.
Now we have our partitions define, we can build out the Key Rules, looking at the critical attributes (name, dob, company name, company number). Create a list of rules to match record in order of highest confidence match
partition1 key rules
name
name+dob
partition 2 key rules
company_name
company_name + company_number
After matching key rules, we observe in our data that record ids master_id 1 = records 1 and 4 = ABC Ltd master_id 2 = records 2, 5, and 8 = John Doe master_id 3 = records 3, 6 and 9 = Jane Smith master_id 4 = record 7 only = Danny Ryan
I hope this helps, please do let me know how you get on.
Hi @sgilla Are you able to share any more information about your use case and existing implementation?
There are typically 3 levels or principles to matching
Partitions - define the main segregating criteria (for example when performing matching on customer data, we might want to segregate our consumer customers from our business customers). The goal of partitions is to have less groups of records, each group having a large volume of records. Having no partition is OK if there is insufficient or poor quality data to assign the record to a partition.
Key Rules / Clusters - define the main key rules - what are the most important (to your business) attributes in the data set? (for example when matching consumer customer data, we might have PII data (SSN, Passport, Drivers License etc) that given its purpose is the best attributes to match with.
Match Rules - define the low level match rules. For each Partition and Key Rule, define the fuzzy matching logic. For example when matching consumer customer data, I might be able to match SSN+Address, or SSN+FirstName or broader match rules using many columns or partial values from those columns.
Structuring your match rules with the above principles will ensure the data processing is optimised.
To give a walkthrough of the matching process for each level;
If a record does not belong in the first partition, it will be checked to see if it fits into the next partition(s).
This process repeats until the record is assign a partition
Or if not assigned to a partition this record will never be matched, and will be assigned a new master id.
Next the records in each partition are checked against the key rules, to see if the records fits the first partition
This process repeats until the record is either assign to a key rule or all key rules are exhausted.
If record does not fit any key rule, then it is unmatched, given a new master id.
Finally the Matching rules, 1 record is selected as the pivot, and all other records in this matching group as known as candidates records.
Each candidate record is checked against the pivot record to see if the rule is met.
Once all candidate records have been check against the pivot record
A new record is selected as the pivot record, the process repeats until all records have been match or not matched.
We have a page on the Matching step in our online documentation, which does a much better (and more detailed) job of explaining how matching works.
Thank you Danny for the details. The link did not open, may be i do not have rights to.
That said trying to translate what you mentioned.
“Partions” which are equivalent to “Union groups” - I do have few groups setup for records where there are huge groups by name.
Keys - “Union key - keys” are setup
Match rules are setup too. But the performance is bad. And after a bulk load I see the transaction id updated on the master and all the slave records. I cannot change match rules they are tuned well. They keys are fewer and have been setup to the best. Do you think Partitioning the data based on their Name is the best way to improve the performance? If so when partitioned by name, can the record not run through all (matchrole -S) slave records(candidate records) and just match with master record(match role - M) and if it does not match create its own master_id?
Partitions are the means to define groups of records that should not be matched together. For example, records in Partition 1, can not be matched to records in Partition 2 or 3 or 4 etc.
May I ask what business domain the data is that you are trying to match together? Is it Party (Individuals / Business), Address, Contact, Product etc.I see that you use the attribute ‘name’ in your example, so I will assume a party dataset containing individuals or businesses.
We’ll start by understanding the data in the various source systems that are to be matched together.
There are 3 source systems that we need to match data across;
Billing
CRM
Provisioning
Taking a top-down approach, we’ll define the attributes (columns) that we need in the master layer (our final output).
For Individuals
Flag
First Name
Last Name
DOB
For Companies
Flag
Company Number
Company Name
Company Reg Date
Company SIC
We’ll then impact assess our input data from each source system against those output column requirements.
Therefore it make sense for our partitions to be;
Individual
Business
We need to remember that records that are not partitions will never be matched. Therefore one of the goals of mastering the data, is to identify issues at source that can be remediated, then once remediated will be assigned to one of the partitions on a subsequent load.
Skipping over Loading the data, lets cleanse the data (for just the partition)
After some data cleansing, we have some level of confidence that record ids 1 and 4 are business, whilst the rest are individual.
Now we have our partitions define, we can build out the Key Rules, looking at the critical attributes (name, dob, company name, company number). Create a list of rules to match record in order of highest confidence match
partition1 key rules
name
name+dob
partition 2 key rules
company_name
company_name + company_number
After matching key rules, we observe in our data that record ids master_id 1 = records 1 and 4 = ABC Ltd master_id 2 = records 2, 5, and 8 = John Doe master_id 3 = records 3, 6 and 9 = Jane Smith master_id 4 = record 7 only = Danny Ryan
I hope this helps, please do let me know how you get on.
Hi @sgilla, we hope you found the answer you’re looking for, I’m marking this question solved for now but please feel free to reply here or create a new post if you have any other questions 👋
Thank you @DannyRyan , for the detailed example. I am working with the subject ‘Provider Practice’/’Site. In your example if we can consider the company ‘ABC’ which occurs twice. My scenario is it occurs 200 times already on the system. Assuming there are 200 records with different combination of
Name
Name+Address
NPI
All falling under one master_id. There is no trouble when reprocessing the subjects but the issue is with the incremental load when a new record loads in. I have the records partitioned to select Name = ‘ABC’ or NPI = 123456789
Now this partition is where the new record would fall into, and go through the group keys and match rules to match. This process is slow, everytime 1 new record comes in to mtach with the existing partition, at the end I see all the records 200 + the new record are updated on the instance table with the transaction id, meaning the record is touched may be because the name or name&address or NPI are same. And mastered record looks good. All the matching rules look good… My problem is
The matching process is very slow for 500 records it takes 1-2 hours and total processed results counts on measures is more than 2-3k because of huge groups of similar data.
So if I keep adding partitions would this cause more performance issues in future. Should partitions really matter because the size of a partition is less than 300 records.
During matching can the interaction between the Omnihealthdata tables and repo tables be playing key role in the performance?
A big thank you for your time on this. Truly appreciate it.
We use 3 different kinds of cookies. You can choose which cookies you want to accept. We need basic cookies to make this site work, therefore these are the minimum you can select. Learn more about our cookies.