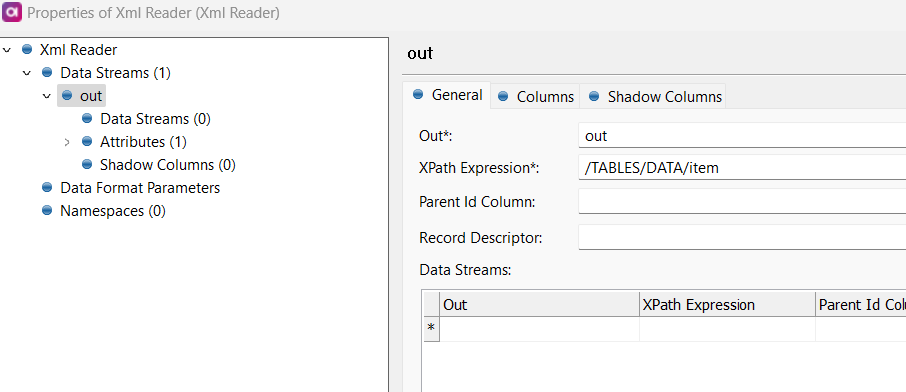
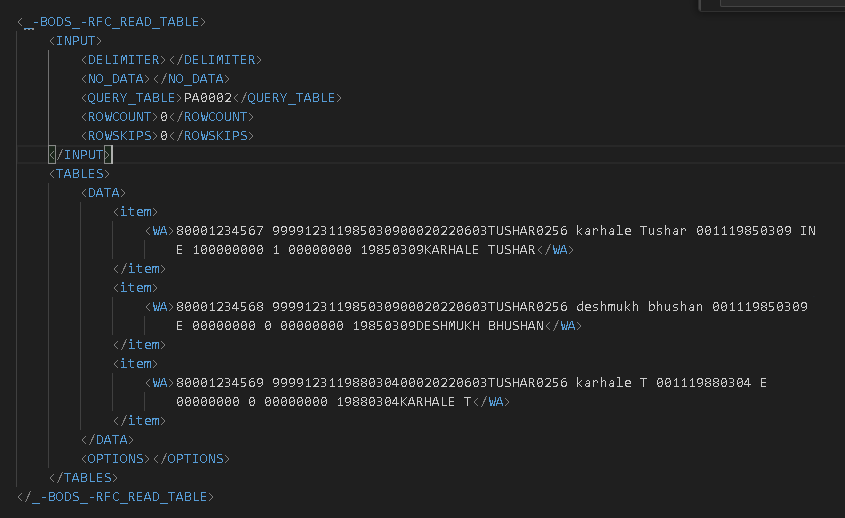
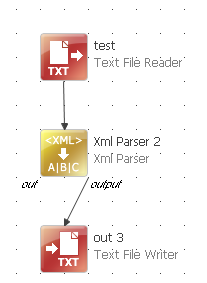
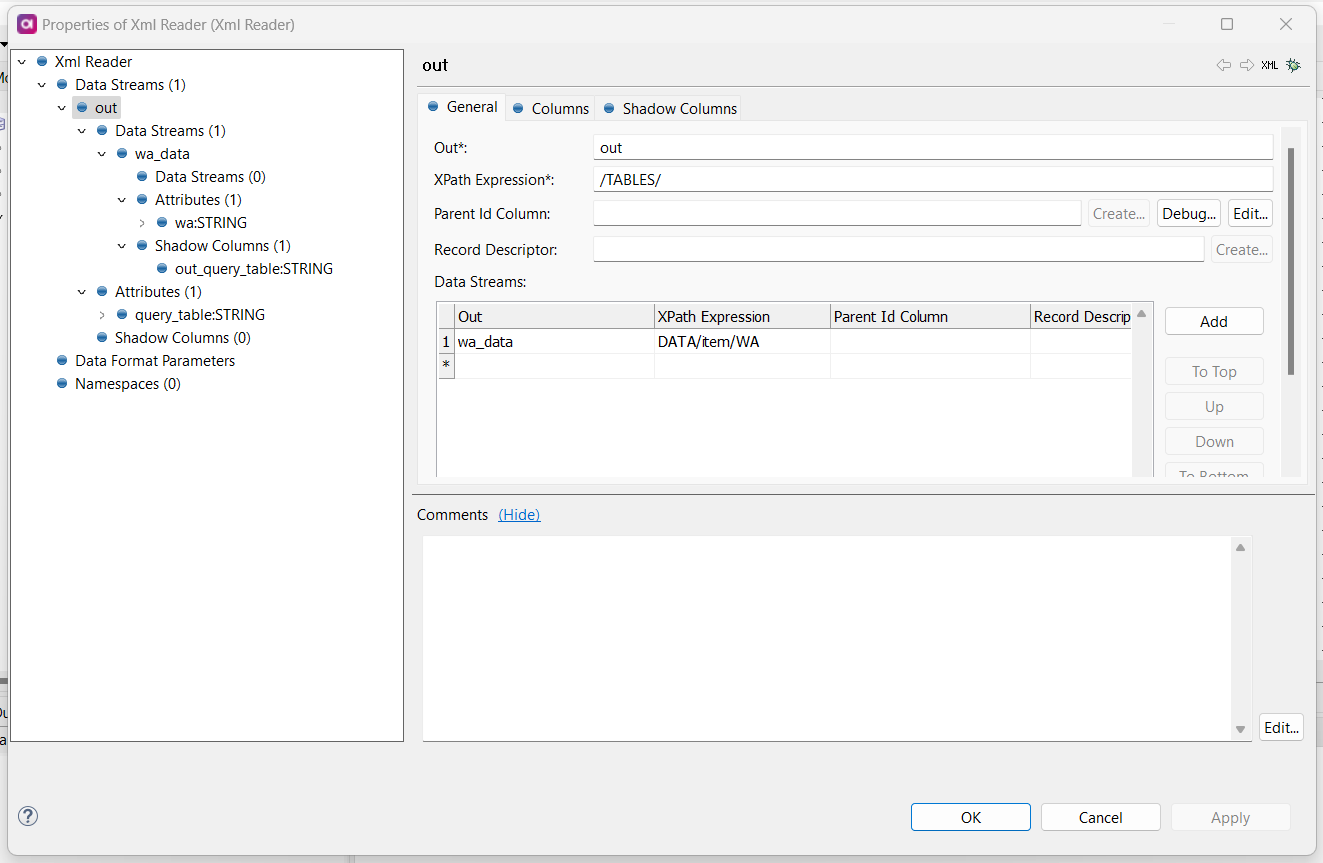
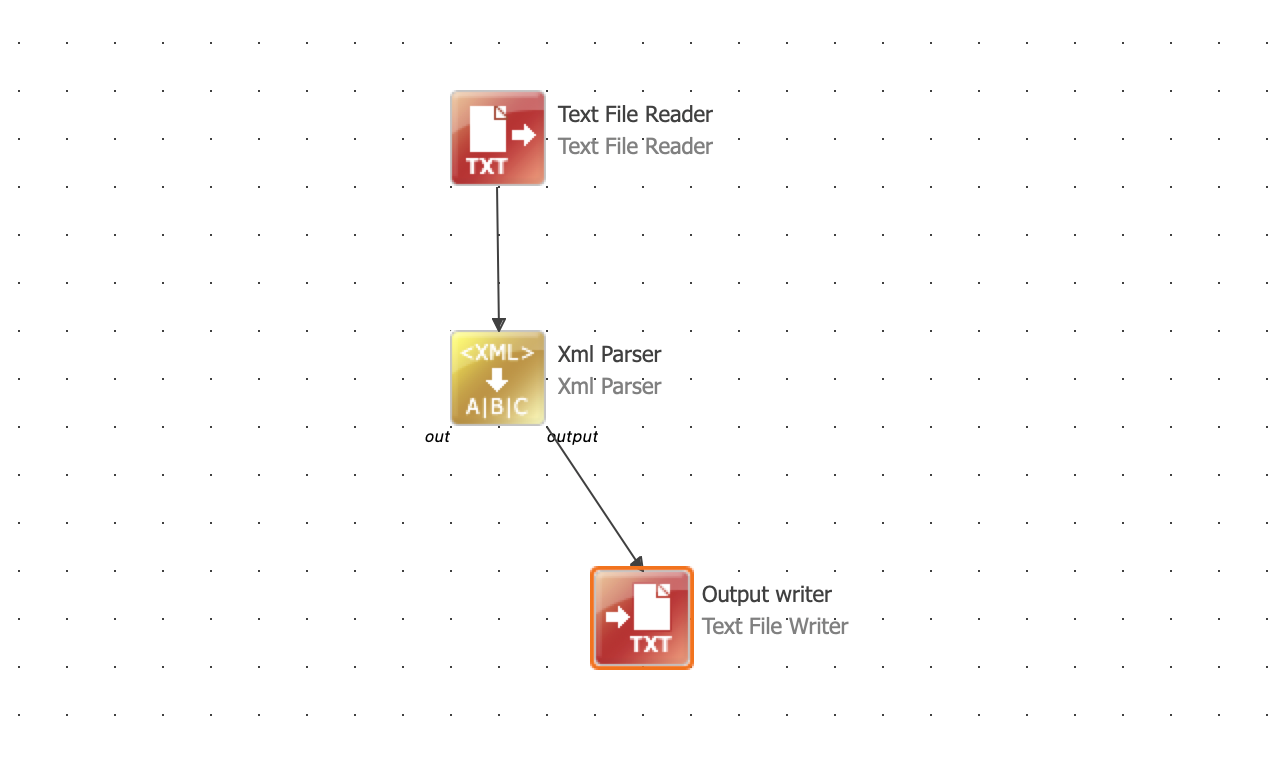
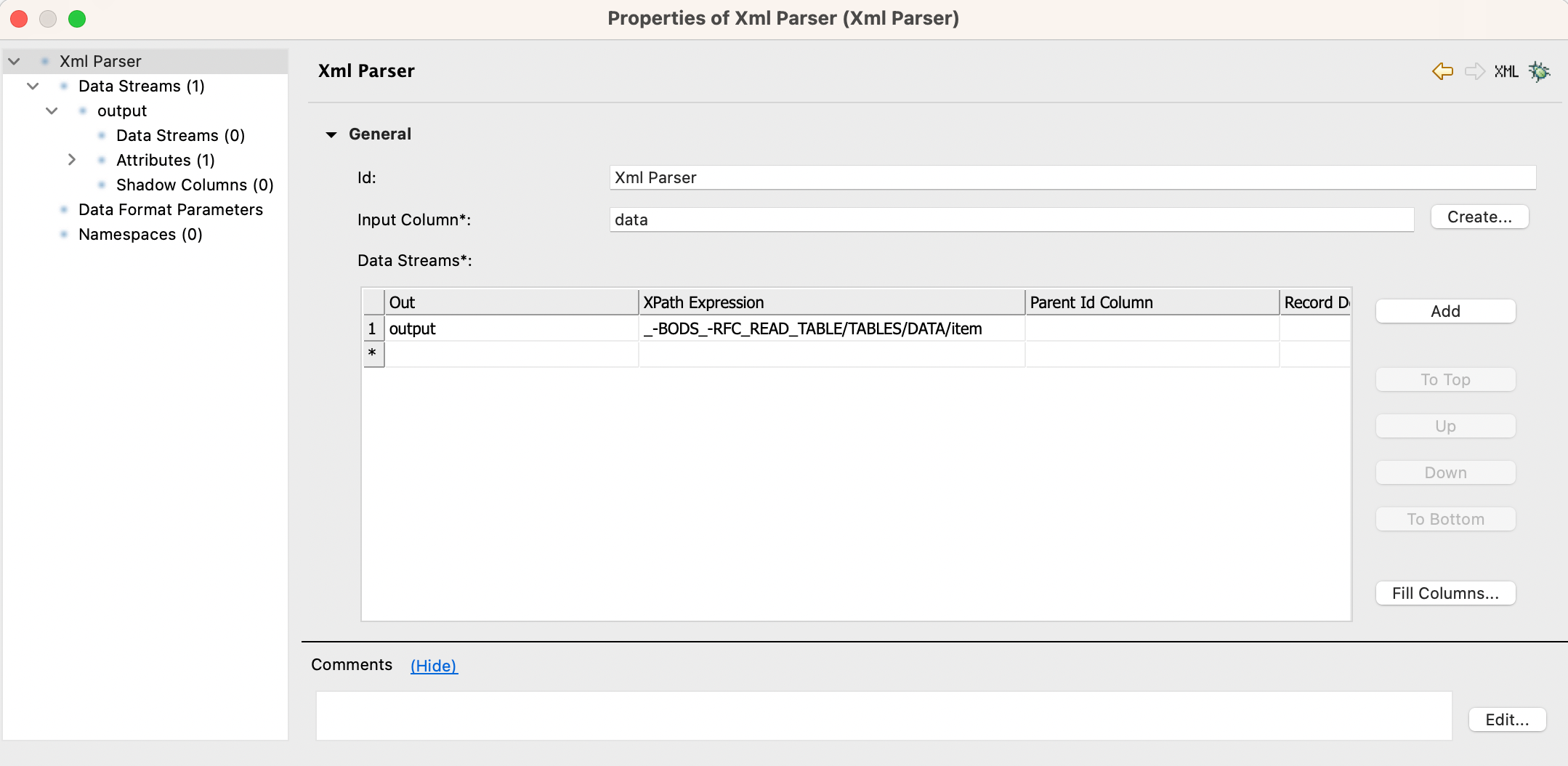
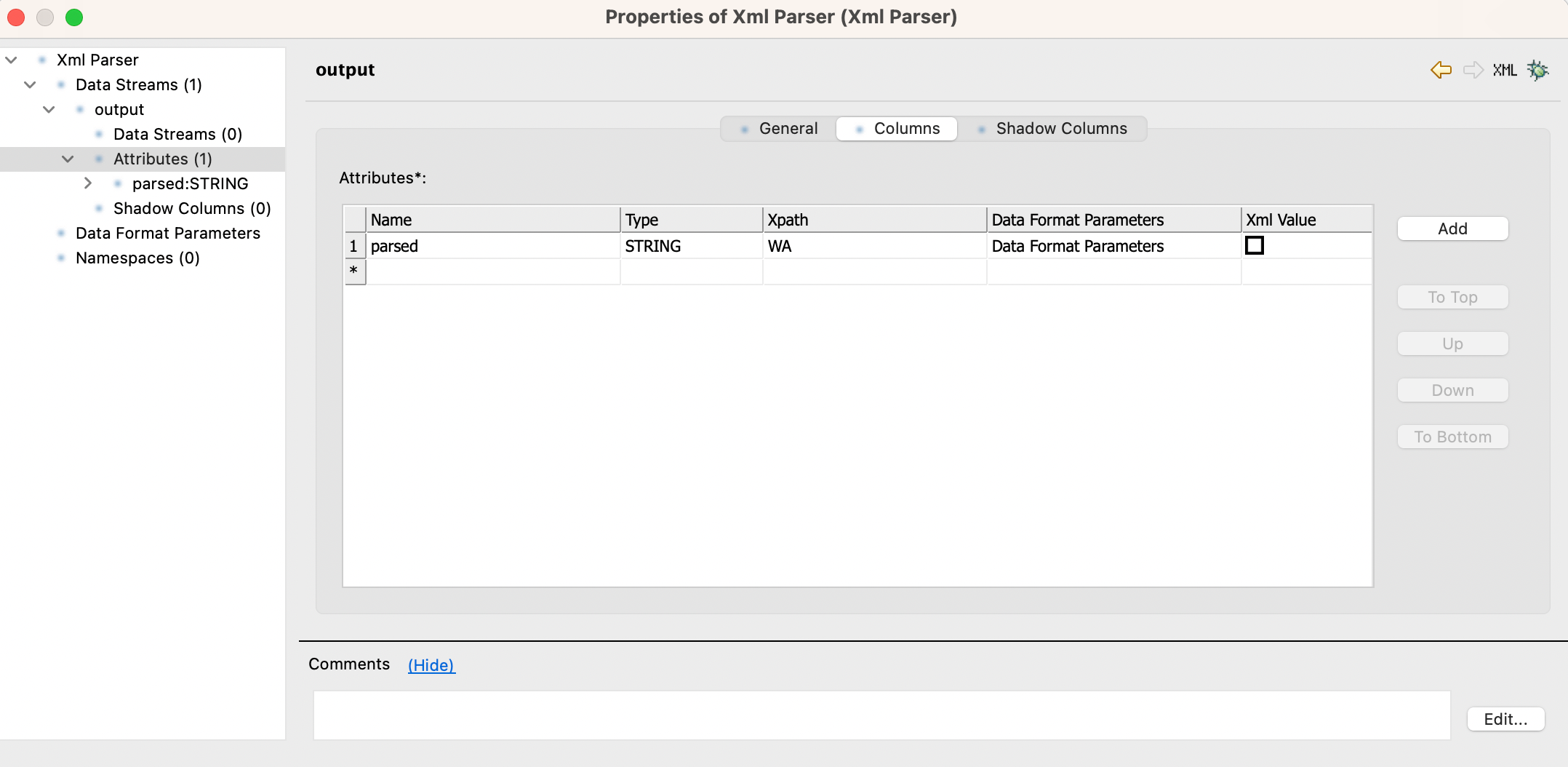
I am trying to parse an XML File that has data related to employees in the following format
<TABLES>
<DATA>
<item>
<WA>Emplyee1No Employee1Name Employee1PhNo Employee1Email</WA>
</item>
<item>
<WA>Emplyee2No Employee2Name Employee2PhNo Employee2Email</WA>
</item>
….
….
</DATA>
</TABLES>
I am using XML parser to parse this but it does not give any result.
I think the issue is with the same tag containing multiple records.
As I am able to parse it when there is just one record i.e. one <WA> and <item> tag.
Can anyone please help me with this?