


Hello. i have a general material data csv file, and in that i have to check for duplicates based on material data. Currently i'm trying with the matching step by creating partitions and key rules but still i'm not sure about it. So is there anyone knows about solving this process?? Thanks!

Solved
How to check duplicate records in ONE Desktop, and using fuzzy logic?
- Data Pioneer
Best answer by AKislyakov
Hi Suryakanth,
You can find a tutorial on how to configure the Matching step in the Tutorials project > 09 Match and merge > 09.01 Match and merge.plan.
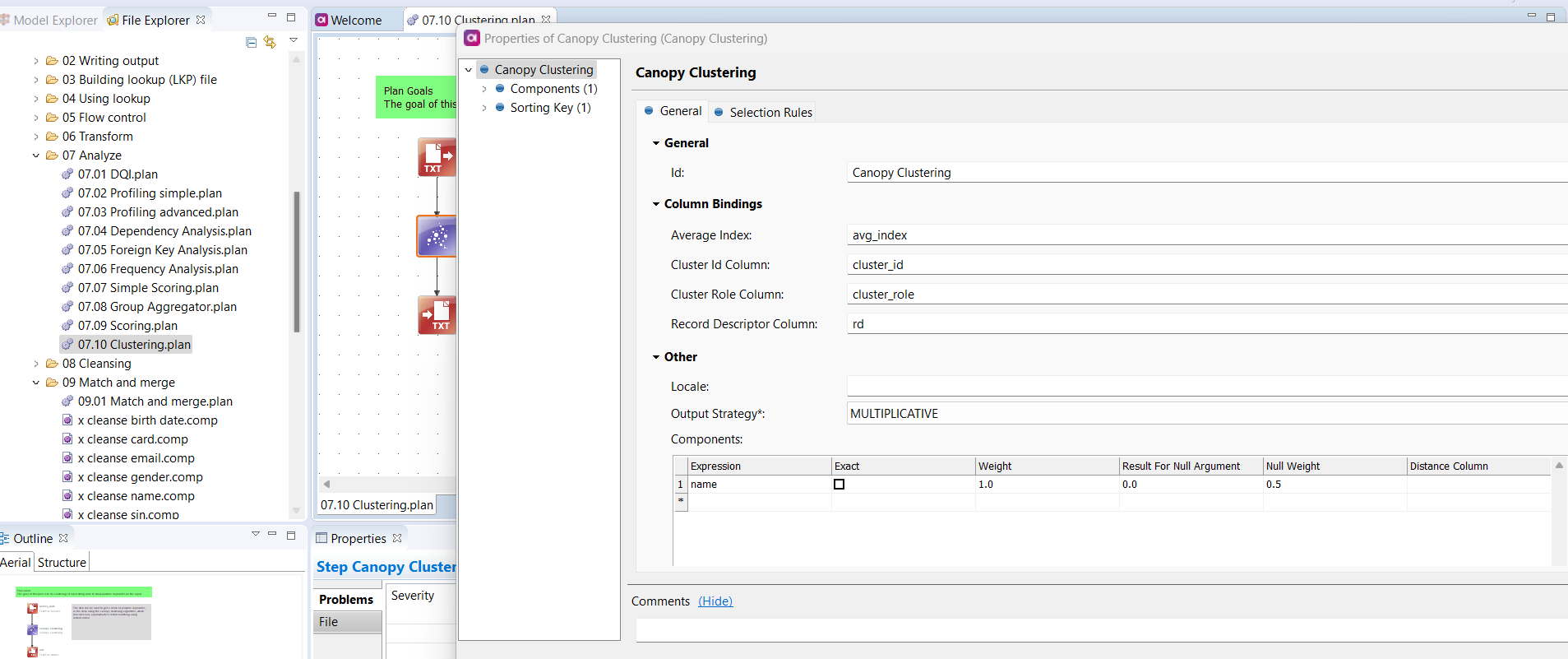
If you're new to this, I suggest trying the Canopy Clustering step first. It requires less configuration and is more user-friendly. You can find an example usage in the Tutorials project > 07 Analyze > 07.10 Clustering.plan.
The Canopy Clustering step allows you to setup components which will be used to search for duplicates, their weights and thresholds when to consider two records belonging to the same group.









Reply
Most Liked this week


Login to the Ataccama Community
No account yet? Create an account
For Ataccama Customers and Partners
or
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.