


DQS matching component results are not reflected when bundle is deployed and the entity is re-processed. I did re-build the repo with the new Extended unifier but no effect. What could be a reason?

Solved
DQS matching component results
- Data Pioneer
- 36 replies
Best answer by Ales
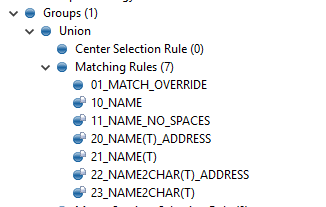
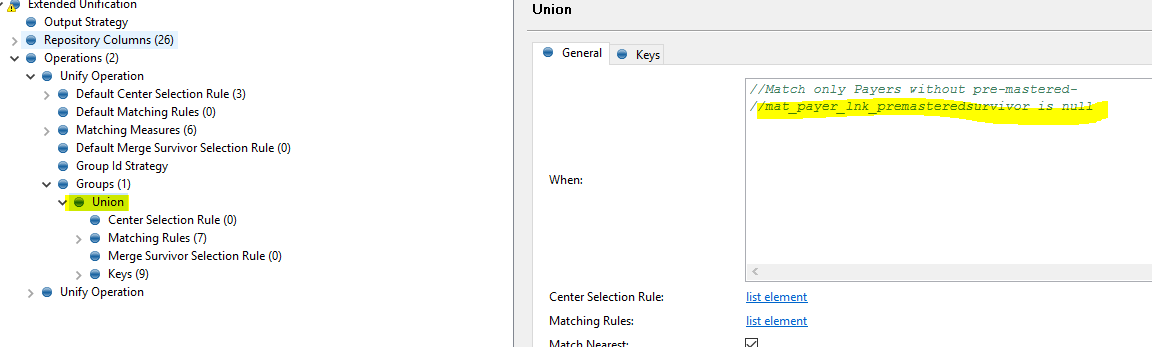
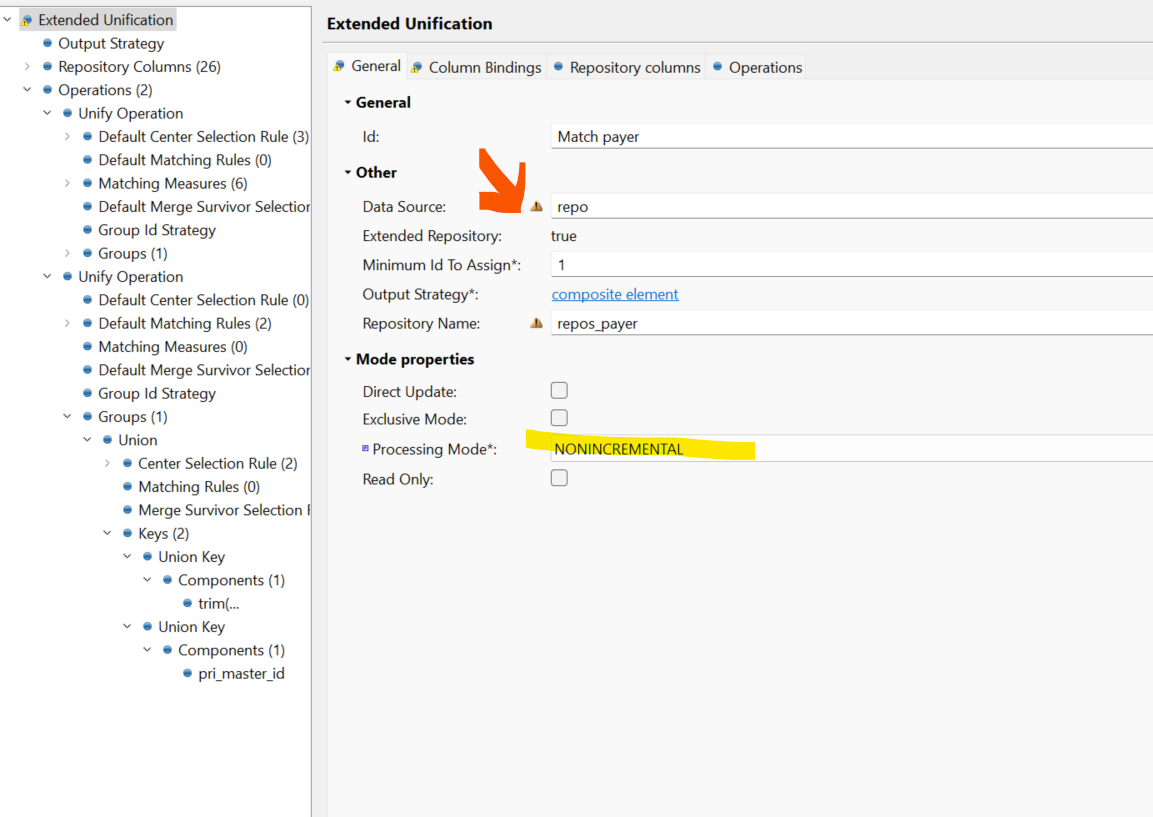
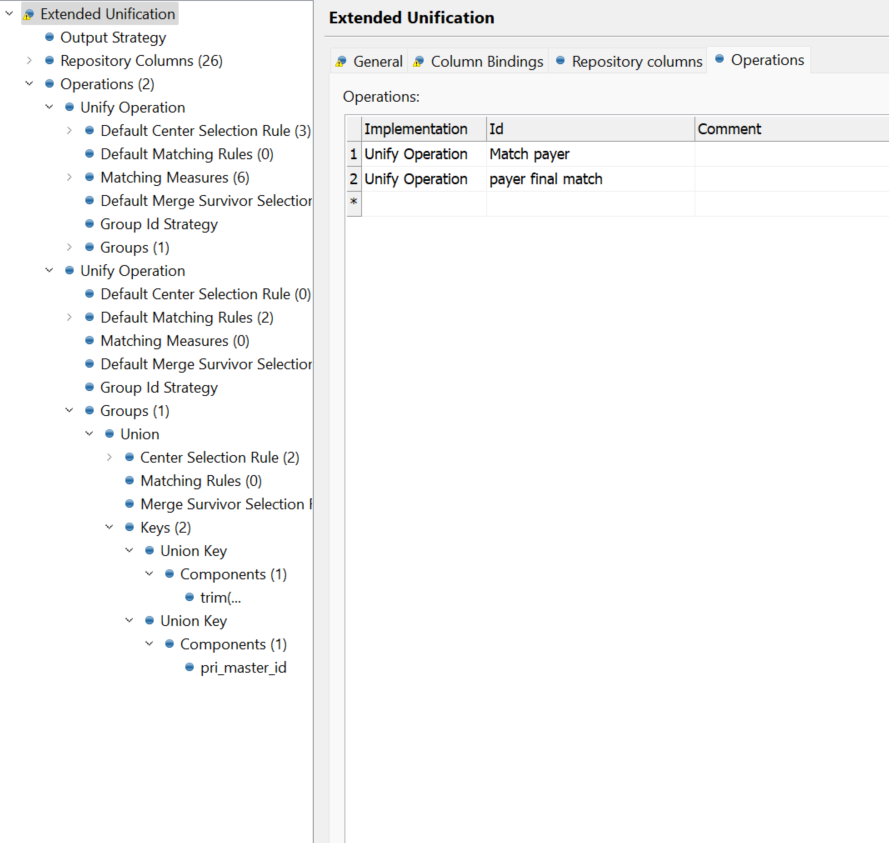
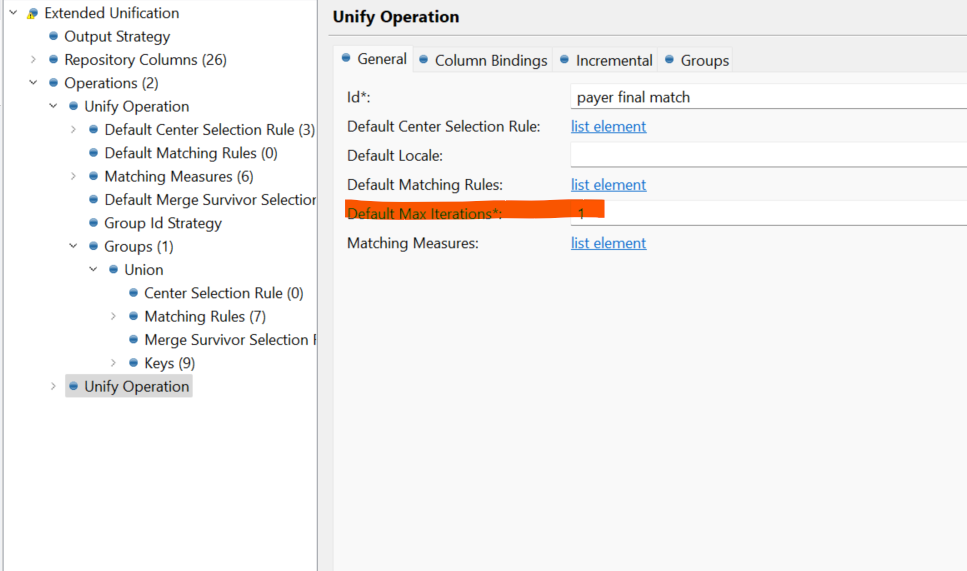
I’m not sure I follow now. If you are getting R roles that means you have bigger MATCH_CAN group than the number of MAX ITERATIONS in that Unify operation. i.e. you can actually have some records grouped together and some not because they were rejected as Renegates.
Seems like you are getting Renegates already from the first Matching operation. Isn’t that you have much bigger groups than before? Could you please do the profile/frequency count on the pri_match_can_id?





Reply
Most Liked this week
Login to the Ataccama Community
No account yet? Create an account
For Ataccama Customers and Partners
or
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.