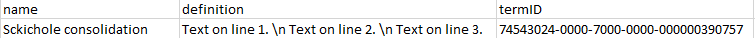The purpose of the follwing scenario is to update multiple term names and definitions. I have created a plan that writes the terms names, definitions and GID to a csv file. In that file I can make updates on the names and definitions. With another plan I read that file and write it back into Ataccama.
That works well, except in the following case. The text in the Definition can be entered on multiple lines by using the Enter button. So OneWeb will show:
Text on line 1. Text on line 2. Text on line 3.
In the export (the csv file) the text will look like this:
"[{""type"":""paragraph"",""children"":[{""text"":""Text on line 1.""}]},{""type"":""paragraph"",""children"":[{""text"":""Text on line 2}]},{""type"":""paragraph"",""children"":[{""text"":""Text on line 3}]}]"
If you import the text like this, the content will not appear on 3 lines, but literally as above and on one line.
How can I import the text so it is on 3 lines again?
Thanks for any suggestion.
Kind regards,
Albert
Best answer by Albert de Ruiter
Hi all,
Also with the aid of Ataccama Support there is no real solution available. Meanwhile I have created a component that I use for instance when exporting glossary details (the business definition field mainly). The component does most of the job, but it isn't flawless. Sometimes still clutter appears, so based on that some further cleaning steps can be defined.
Frankly not all cleansing requirements are straightforward: basically I want to get rid of the json-like formats that are added in the output, but also formatting options like italic/bold text, or bulleting will lead to ‘garbage’ in the export. But then, how can you keep that formatting in an export to either a text file or a database table?
Regarding the component, the approach is quite basic (or ugly, actually), simply replacing unwanted strings by an empty string. I have choses a multi-step approach in order to keep the component understandable, because if you nest all steps the logic becomes quite unreadable.
So if anyone has a better idea, please share 😉
With respect to the attachment, a component file could not be uploaded so I renamed the file extension. Rename back to ‘comp’and you can use it in Desktop again.
Hi @Albert de Ruiter! You can alter term definitions using a Column Assigner step to include the newline character \n to indicate a new line. For example, "Text on line 1. \nText on line 2. \nText on line 3. \n" will separate each sentence onto a newline. Hope this helps!
Thanks for thinking along. Actually I had already tried to use the \n in the input file, as replacement of the "[{""type"":""paragraph"… etc. But then the \n is not recognized as a newline character by the Metadata Writer. Do you have a clue?
I use replace(AttributeDescription, "\l\n"," ") in a similar case where I needed to delete the CR/LF from an attribute discription. After that the csv could properly be imported
Hi Daan, actually the idea is to keep the linefeeds in the Definition field of the term!
So the question is, when I use a csv file as input in a desktop plan as follows
and using a Metadata Writer to import the data back into Ataccama
in OneWeb how do I get the definition to show on 3 lines separately, like
But with ‘Text on line 1. \n Text on line 2. \n Text on line 3.’ in the csv file in OneWeb the definition content remains the same, so again ‘Text on line 1. \n Text on line 2. \n Text on line 3.'.
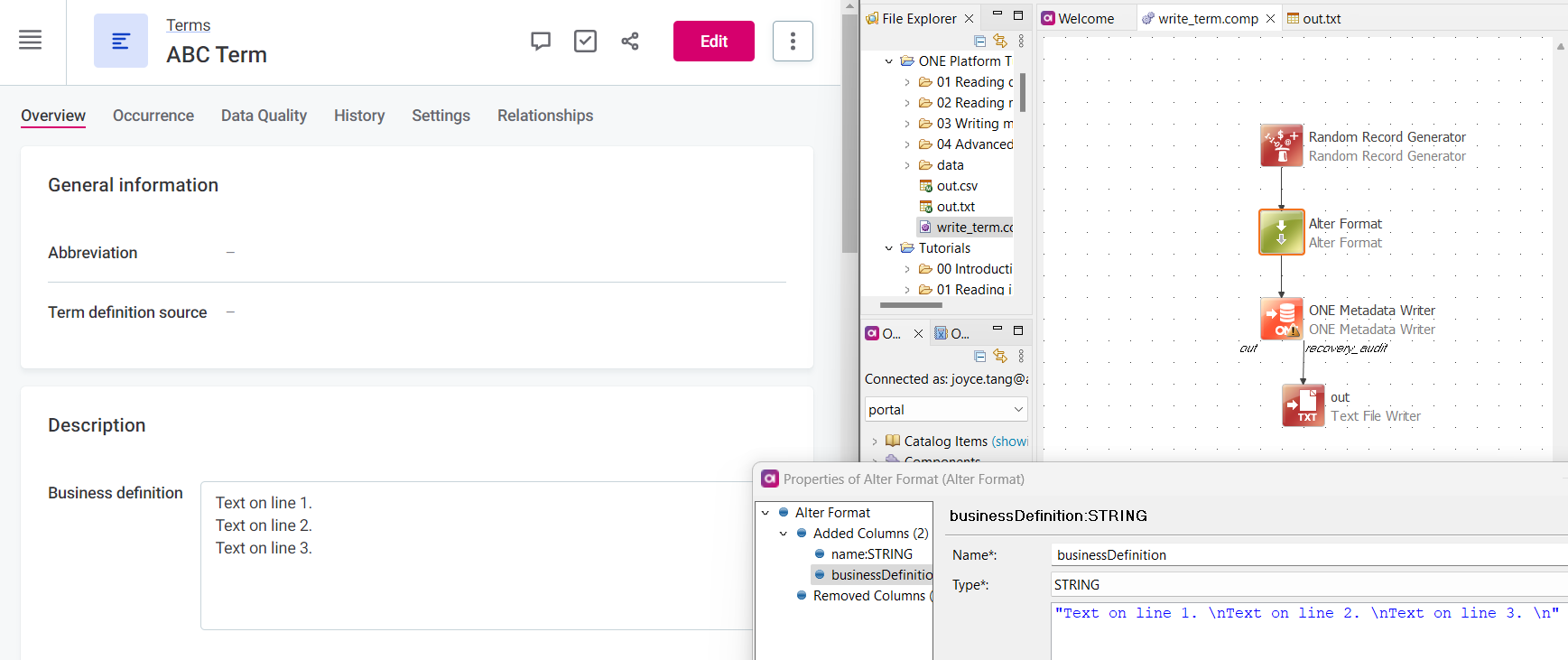
Hi @Albert de Ruiter, I’ve created a plan which imports ABC Term and a description with newlines. In the ONE Web App, each description line populates onto a newline.
If this doesn’t work for you, could you verify that the description is correct (with the proper newline characters) before the ONE Metadata Writer step? Along with a screenshot of the ONE Web App term description that’s populated after the plan is run? Thanks!
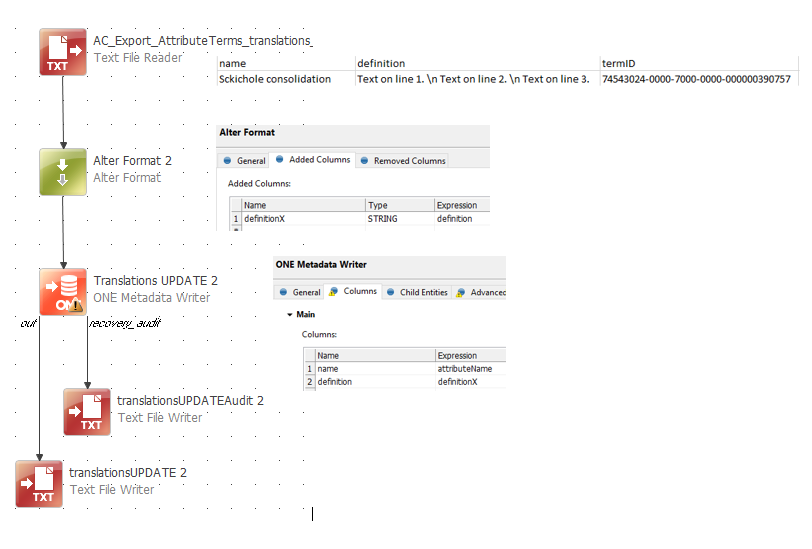
Hi @joyce, thanks for your example. I can recreate this successfully on my side, but my scenario is a bit different with respect to the input of data. As input for the plan I have a csv file that contains many updates to be executed via the Metadata writer step. In your example the data input is manually in the Alter format, so that approach won't work for me. I have tried to include your setup in my scenario as follows, but unfortunately the definition content is still on 1 line.
Also with the aid of Ataccama Support there is no real solution available. Meanwhile I have created a component that I use for instance when exporting glossary details (the business definition field mainly). The component does most of the job, but it isn't flawless. Sometimes still clutter appears, so based on that some further cleaning steps can be defined.
Frankly not all cleansing requirements are straightforward: basically I want to get rid of the json-like formats that are added in the output, but also formatting options like italic/bold text, or bulleting will lead to ‘garbage’ in the export. But then, how can you keep that formatting in an export to either a text file or a database table?
Regarding the component, the approach is quite basic (or ugly, actually), simply replacing unwanted strings by an empty string. I have choses a multi-step approach in order to keep the component understandable, because if you nest all steps the logic becomes quite unreadable.
So if anyone has a better idea, please share 😉
With respect to the attachment, a component file could not be uploaded so I renamed the file extension. Rename back to ‘comp’and you can use it in Desktop again.