I am trying to use Splitter to transform the string
Example : Input: BeWhoYouAre
Splitter output - ‘e ho ou re’ - skipping the first letter as ‘Upper case’ is the separator
Desired output - ‘Be Who You Are’
How do I achieve this? Also if the string is all lower how to split it?
Example: Input: ‘bewhoyouare’
desired output - ‘Be Who You Are’
Best answer by Lisa Kovalskaia
Hi @sgilla!
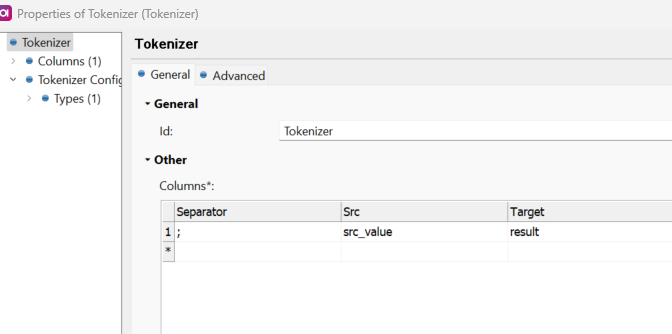
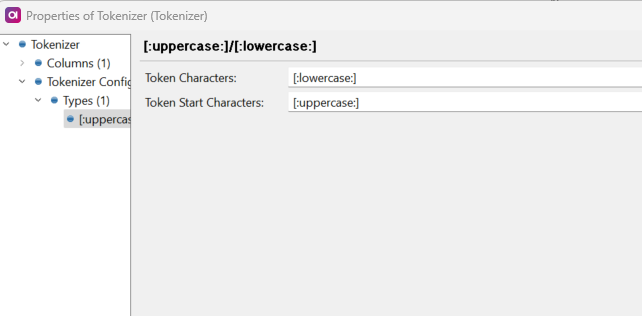
The Tokenizer step works nicely for first use case where you have uppercase letters as delimiters. Here I used ; as the separator but you can leave it blank to have words separated by spaces.
Speaking of strings that don't have any identifiable delimiters, that's going to require additional tools. One of the easier options is using a dictionary / lookup file to provide an interpretation for each concatenation. A step like Apply Replacements would then help transform the source strings into the correct interpretation. If you have a large number of distinct concatenations and no way to predict in advance all possible variation then a dictionary won’t do a perfect job - you may need to work with language model to parse such strings and only then pass the data to Ataccama.
I'll see if I can get any additional tips from the team on the latter - and please let us know if you can share more details on the use case. thanks!
The Tokenizer step works nicely for first use case where you have uppercase letters as delimiters. Here I used ; as the separator but you can leave it blank to have words separated by spaces.
Speaking of strings that don't have any identifiable delimiters, that's going to require additional tools. One of the easier options is using a dictionary / lookup file to provide an interpretation for each concatenation. A step like Apply Replacements would then help transform the source strings into the correct interpretation. If you have a large number of distinct concatenations and no way to predict in advance all possible variation then a dictionary won’t do a perfect job - you may need to work with language model to parse such strings and only then pass the data to Ataccama.
I'll see if I can get any additional tips from the team on the latter - and please let us know if you can share more details on the use case. thanks!
Except when there is a values like ‘USASports’ transforms to ‘U S A Sports’. How do I avoid part of string where letters are all upper case not be split. Like it needs to be ‘USA Sports’. For now I used a lookup but wondering if there is a solution within the tokenizer. Thanks a ton.
I don't think the Tokenizer can handle something like USA Sports example. A lookup is a good solution -- or if you don't know the exact all-capitals elements that may come up but you know the pattern is always similar, e.g. the element is always at the beginning, you might also handle it with some expression after the Tokenizer:
Of course the more variation there is in the source data, the more interesting it gets! :)