Hi Ataccama community,
I’m hoping someone with better grip on the Ataccama GraphQL model can shine a light on this.
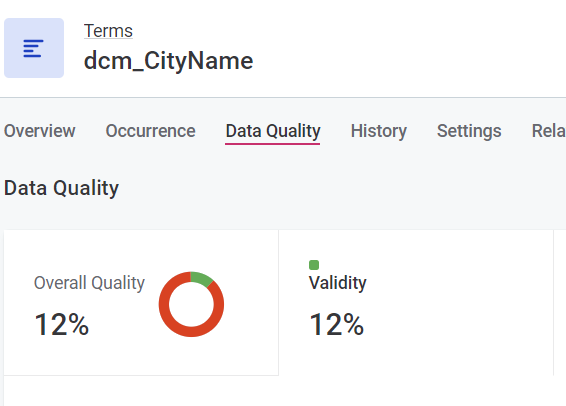
For internal reporting, we are looking to retrieve data quality details via the Ataccama GraphQL API. One of the requests it to produce an overview of the DQ score across the (rule’s) DQ dimensions. This is basically the same as is shown in the web UI when navigating to the ‘Data Quality’ tab for a Term. It shows the score broken down by dimensions, based on how the rules are defined.
What I’m trying to do is retrieve the passed/failed rows at this level, so for each term and each dimension. This would allow me to summarise this into a score per dimension.
However, I am unable to get this out of the API.
I’ve approached this from both the ‘terms’ and ‘rules’ pathway. In both approaches I always end up with the ‘Overall Quality’ score for each term - not the per dimension details.
The ‘rules’ query looks promising, but ultimately only returns the passed/failed records for the overall quality score, not specifically the rule that applies (for example the accuracy rule).
For reference, this is the attempt starting from the (list of) rules:
query listRules {
rules (versionSelector: {draftVersion: true} filter: "implementation.$type =='ruleDqImplementation'") {
edges {
node {
gid
publishedVersion {
name
ruleDefinitionSource
#description
implementation {
gid
#type
publishedVersion {
aggregationRule
component
dqDimension {
publishedVersion {
name
}
}
}
}
termInstances {
edges {
node {
gid
publishedVersion {
displayName
target
{
gid
publishedVersion {
name
dqEvalTermAggr {
storedVersion {
ruleCount
recordCount
invalidCount
validCount
}
}
}
}
}
}
}
}
}
}
}
}
}And this is the attempt starting from the list of term, trying to find out what rules apply and ideally retrieving the scores from there:
query listGlossaryTerms {
terms(versionSelector: { draftVersion: false }) {
edges { # List of terms
node{
gid
publishedVersion { # Individual term
name
dqEvalTermAggr {
storedVersion {
ruleCount
recordCount
invalidCount
validCount
}
}
validationRules {
publishedVersion {
enabled
ruleInstances { #listwrapper (list of rules)
edges {
node { #nodewrapper
gid
nodePath
storedVersion { # individual rule
displayName
}
}
}
}
}
}
stewardship {
gid
nodePath
type
draftVersion {
name
}
}
}
}
}
}
}Does anyone know which route to take to find the scores per dimension? By looking at the page setup there seems to be a dqEvalTermOverview object that contains this, but I don’t know how to access this via GraphQL.