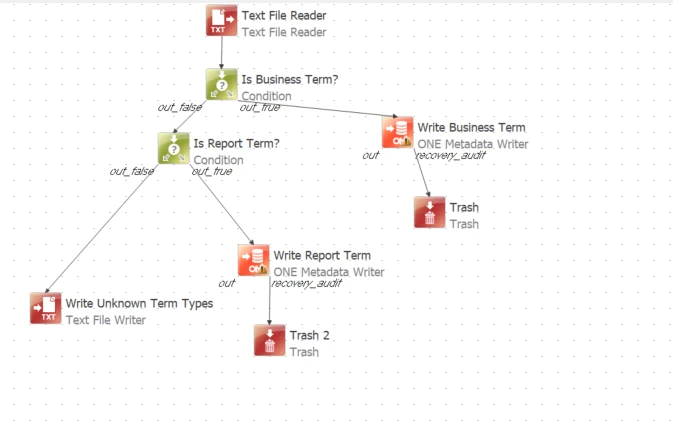
I have a plan that reads a CSV file from my storage and writes the data to the Business Glossary page.
What I Want to Achieve:
I would like to enhance this plan to not only insert new terms, but also check for existing terms and update them if necessary to avoid duplicate
-
If a term already exists and nothing has changed, it should be skipped.
-
If the term exists but the definition (or any attribute) has been modified, it should update the existing entry with the new information.
-
If the term does not exist in the glossary, it should be inserted as a new entry.
Challenge:
I noticed that some solutions in the community reference a unique ID for each term---community chat on bulk term update, but my business glossary terms currently do not have an ID field.
Question:
How can I structure the plan to perform insert, update, and skip logic effectively,
What’s the best practice for comparing and managing term updates in this scenario?
below is a snip of what my current plan that write only new plan looks like --