Is there a way to quickly select only distinct rows in Ataccama One Desktop?
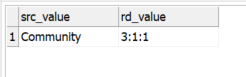
(I now used a record descriptor and filter with Regex find(“.:.:1”, rd_column)

Is there a way to quickly select only distinct rows in Ataccama One Desktop?
(I now used a record descriptor and filter with Regex find(“.:.:1”, rd_column)
Best answer by DannyRyan
Hi
Using the Record Descriptor Builder step is certainly the best practice approach to solve this use case.
An alternative to using the Filter step with Regular Expression is to use the built-in expression function word().
I have attached a quick example using the expression function word().
No account yet? Create an account
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.