Hello,
I am trying to use MPP step to derive some values from some free text field.
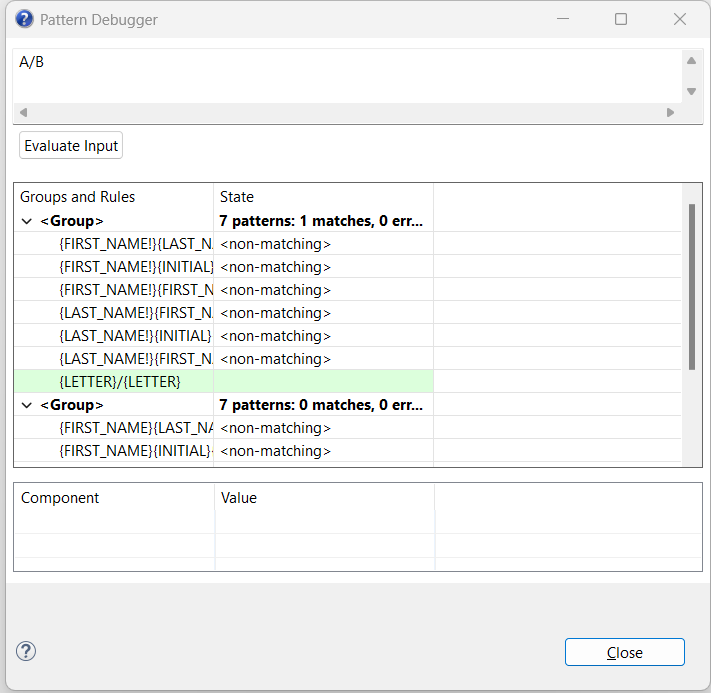
I am struggling to parse any regex pattern for string like “A/B”.
It seems to work but whenever there is / sign it just doesn’t parse it.
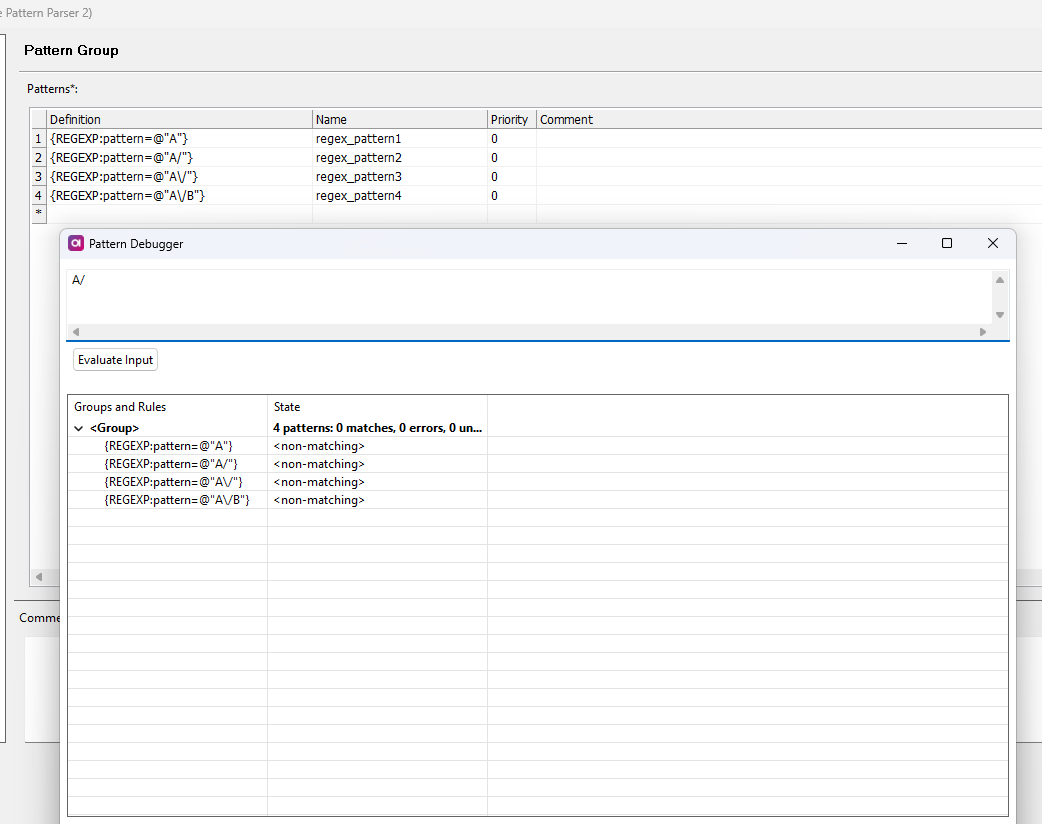
I tried to escape it using \/ and also some other different options but nothing seems to work.
What am I doing wrong?
EDIT:
Tried to parse similar REGEX against Regex Matching step and here it seems to work:
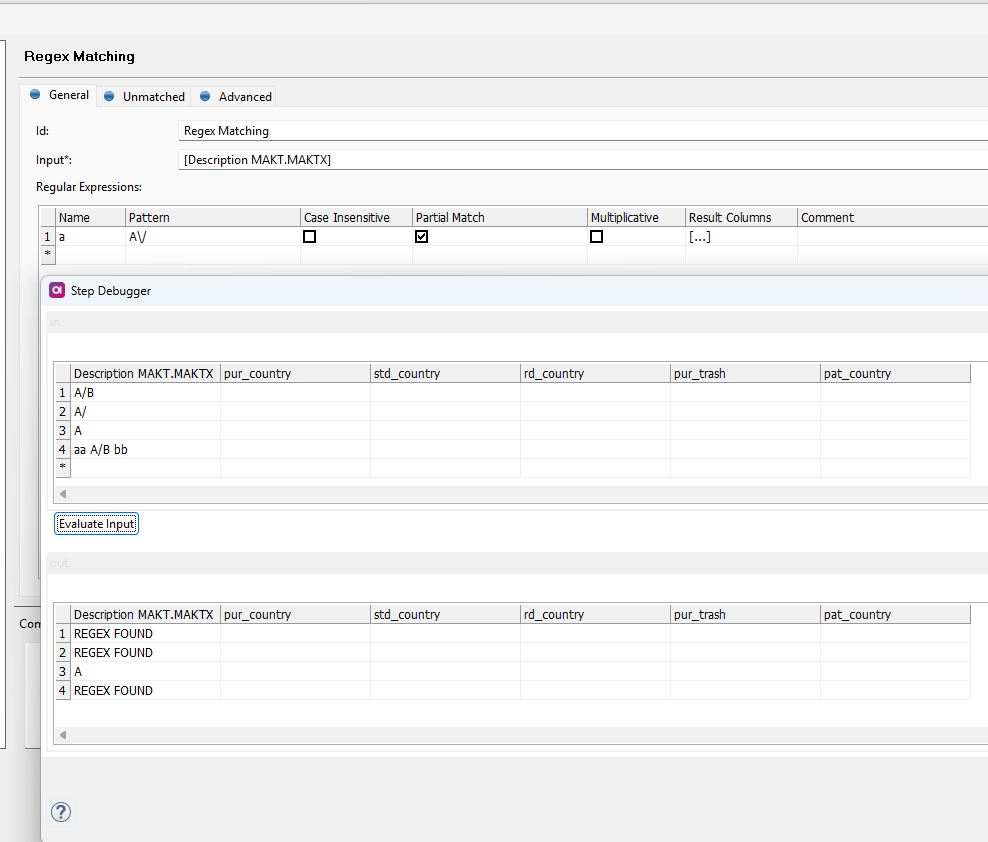
Could it be possible that MPP step is parsing incorrectly?
EDIT 2:
I might have found the issue. I took Tokenizer part from our another component and it started working correctly. However, I still don’t understand exactly how Tokenizer works and the docs aren’t providing with great examples on how to understand it.
Szymek