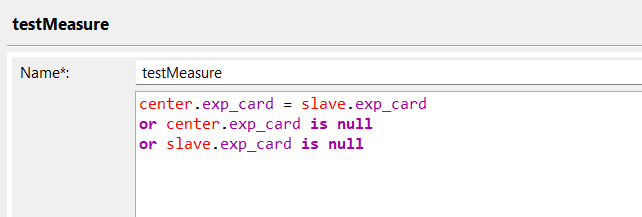
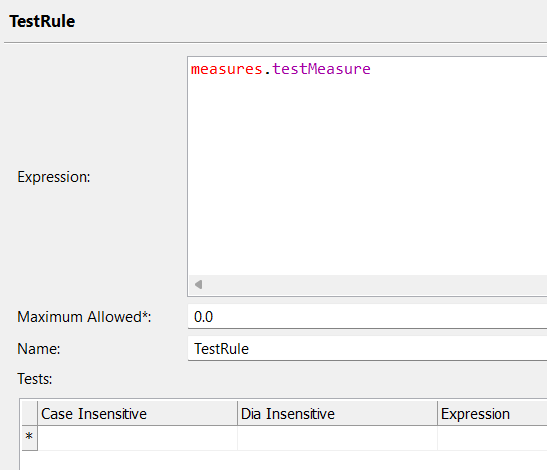
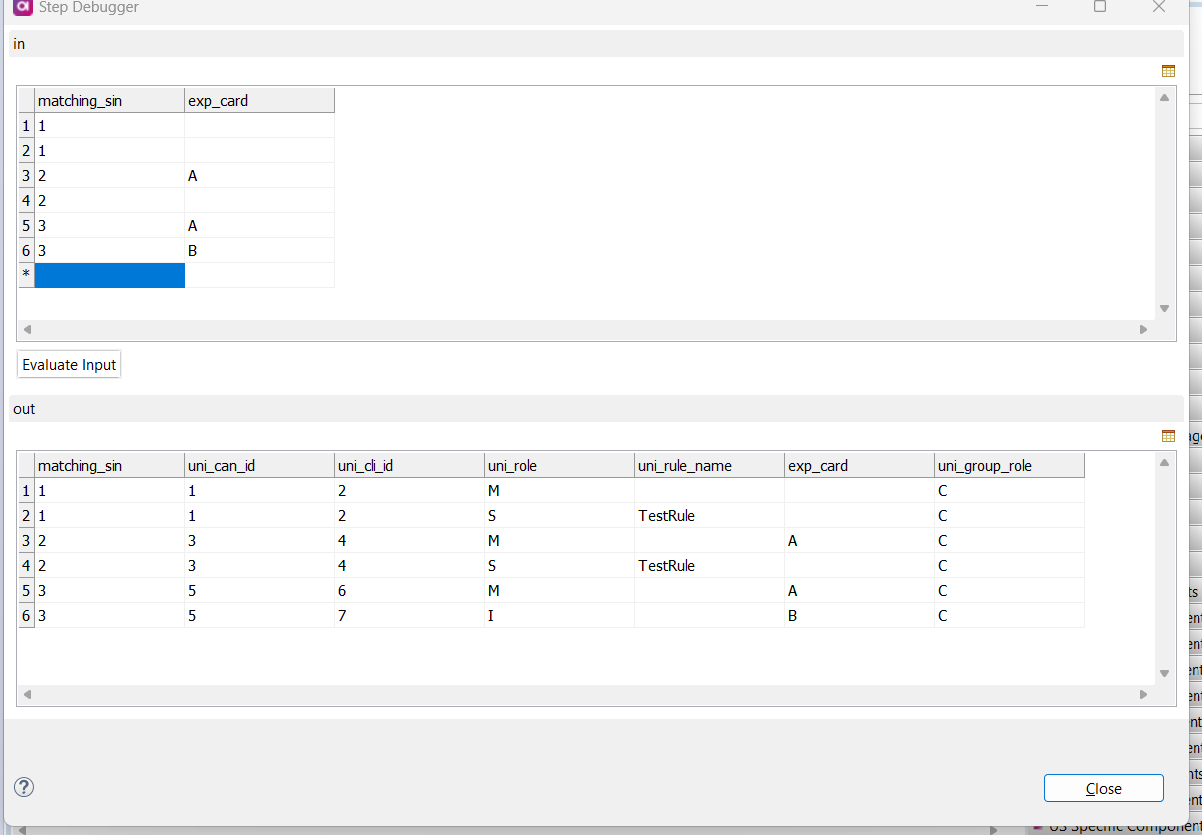
How are NULL’s considered? I have a case statement which gives the right value matching measure -used debug to test. But when it comes to matching rules, it skips the rule.
Example:
Name NPI
Ramona 12345678
NULL 12345678
the 2nd row should match the 1st on NPI value and considering on of them is null.
Even the scenario
Name NPI
NULL 12345678
NULL 12345678
these two should match together based on NPI. I do not see a special character. If I replace NULL with a value ‘A’ , they match with rule Matching on NPI. but does not work for NULL.
Any thoughts or suggestions appreciated.