Hi Team,
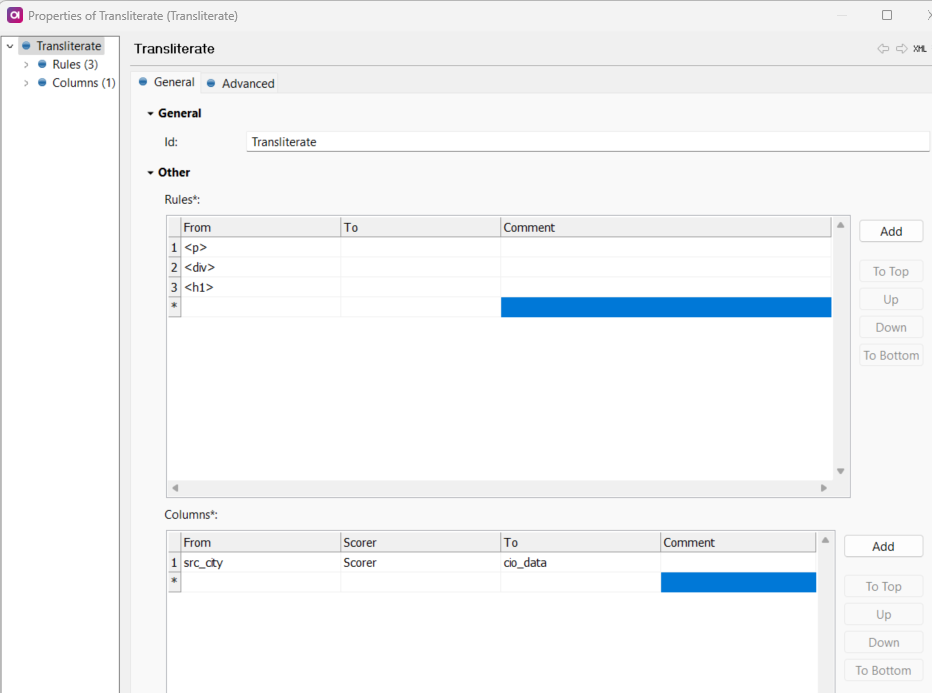
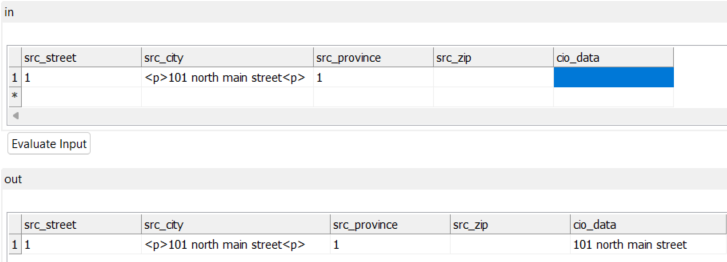
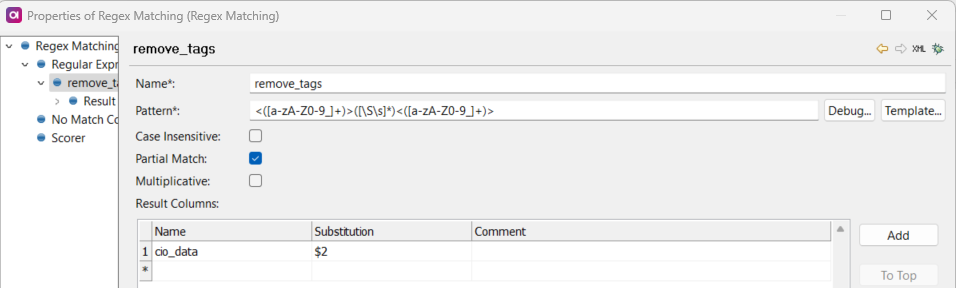
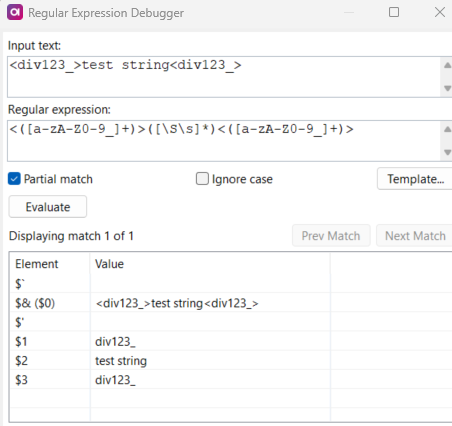
I am reading from collibra using collibra reader, some data has html tags like - <p> , <div> in it. Is there a way where we can filter out the html tags if its present in the data. like strip html tags like that.
Let me know if more information is needed.
Thanks.