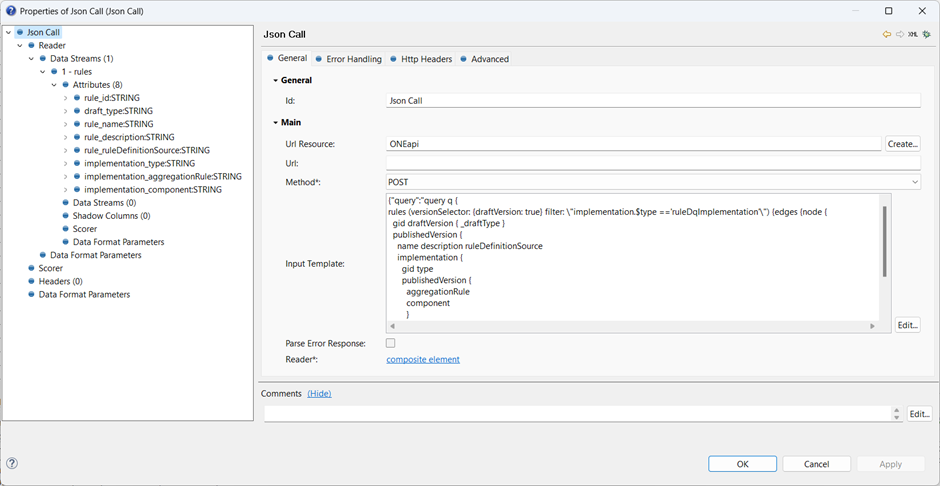
ONE Desktop provides two ways to access the ONE platform data. Usually, it is easiest to use the Metadata Reader step, but sometimes you need a more complex query, or perhaps you are developing a Json API call to be used from another application entirely. In this case, you will want to start from a Json Call step.
The plan I will describe is this:
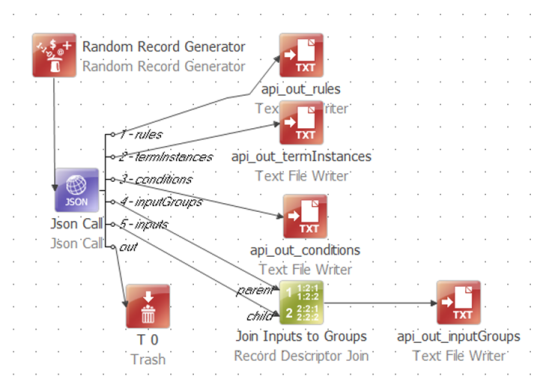
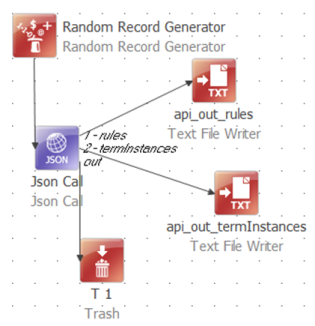
I’ve used a random record generator to “inject” a single row into the data flow to get things started because the Json Call executes once for each row on its input.
The “out” output from the Json Call carries all columns from the input; and can also be used to carry connection error messages. I’ve not set that up, so I just sent all that to Trash.
I’ve named each of the remaining outputs using a sequential numbered prefix. This manipulates the automatic alphanumeric sorting of the output connections so that the ordering is more logical than a list of element names would be. I’ve also set the layout of the step to horizontal so I can read the labels.
Never try to write a plan like this all in one go! You’ll need to start at the top level and work down getting each stage to output the correct data to file. You also need to have an active data source set up as a Generic server:
The objective of this plan is to output a summary of the defined rules and the associated terms; and to list the inputs and conditions for each rule.
Starting at the top level, we need to explore the Rules collection.
Look at the ONE Metadata Explorer, making sure the presentation is set to Metadata Model:
Scroll down to the entry for rule
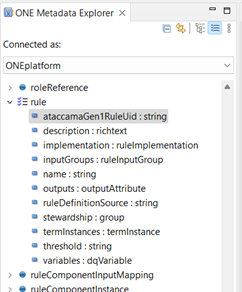
Notice that the entity is “rule” but the metadata holds many of them, so we actually request a collection called “rules.” Each of the attributes is listed with its type. Some have a simple base datatype like string, others refer to different metadata entities.
The attribute ataccamaGen1RuleUid is a custom attribute, used for a customer as part of their migration from our Gen 1 product to Gen 2. Any custom attributes defined in this way through the ONE WebApp metadata editor will show up in ONE Desktop.
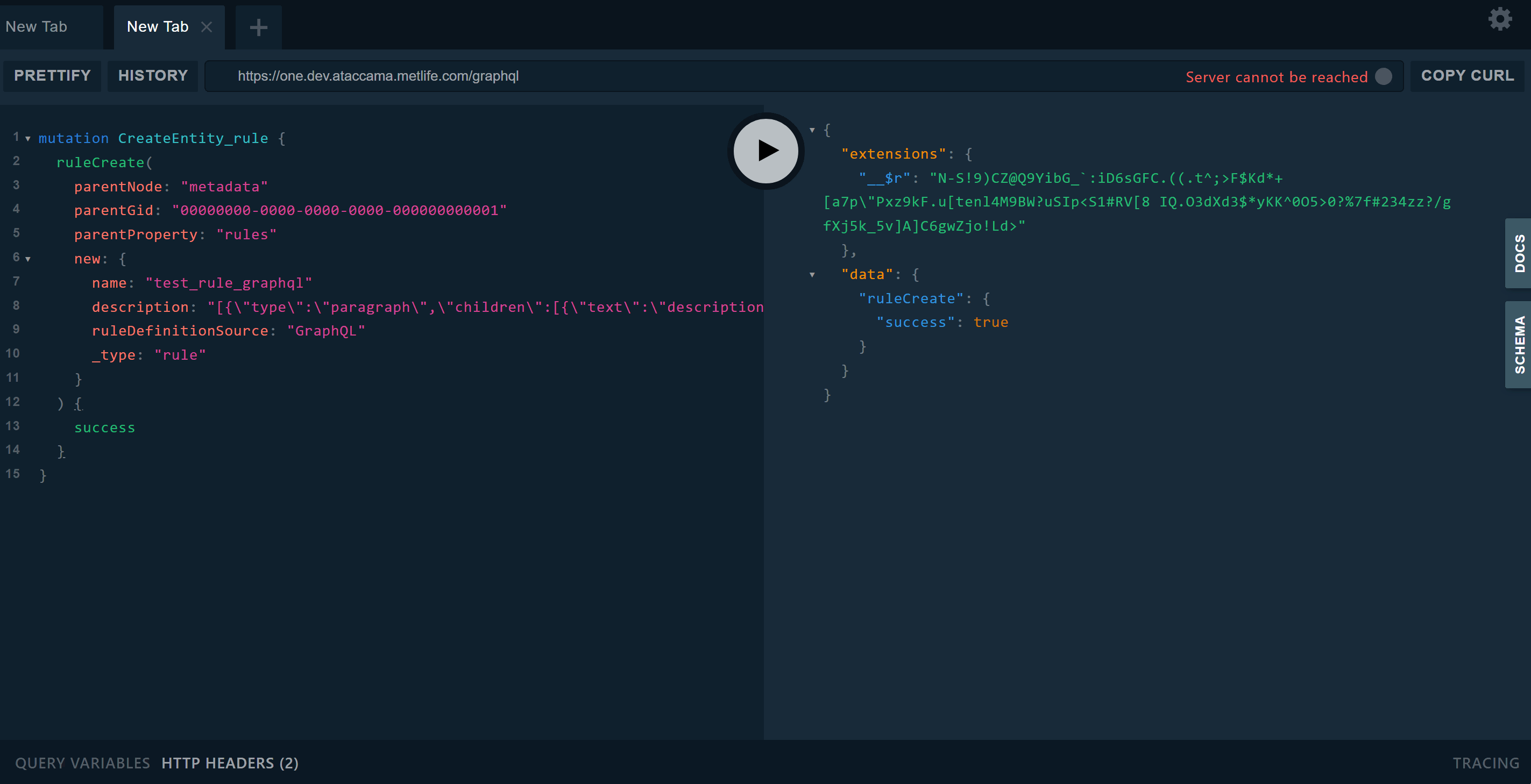
For a first try, we can set the query string in the Json Call to bring back the rules as the top level data stream:
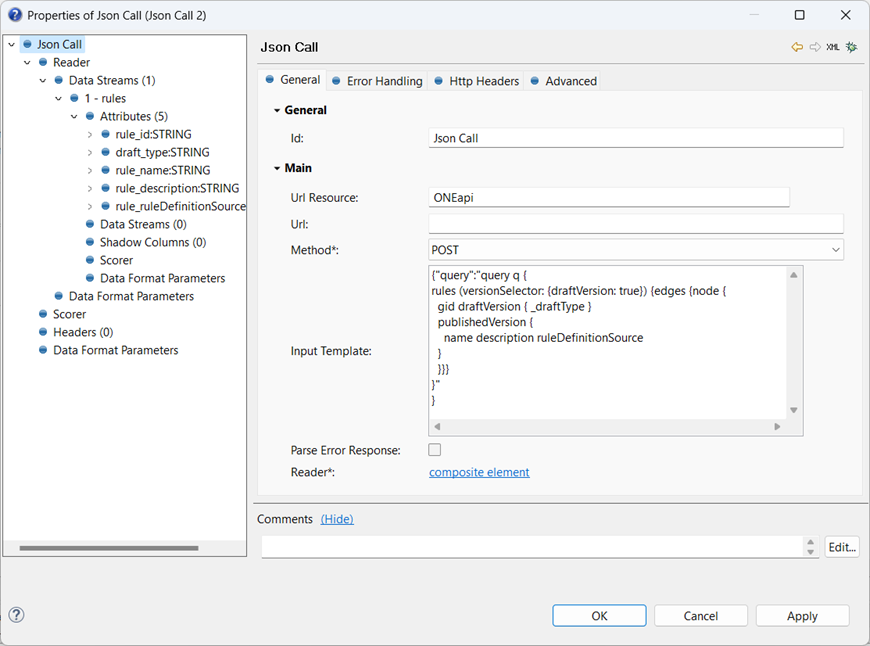
Important: Notice that the Input Template uses a string value that contains the query. As the query gets more complicated it really helps to use proper indentation, but the query string must not include [TAB] characters - the call will simply return no data. Instead, I have used two spaces for each level of indentation. If you prototype the query in Playground then it will insert tab characters automatically, which need to be replaced with spaces.
For this project, I happen to be interested only in the published version of each rule, but I do want to know whether a draft version exists.
The first line of the GraphQL query selects the root entity collection, instructs the engine to include draft versions and sets up the standard specification for an array of values in GraphQL:
edges { node {
Essentially, edges delimits the start of an array, and node marks a row. The structure of the query matches the structure of the result.
Every entity has a unique gid assigned, for use as a primary key.
draftVersion contains all the fields of publishedVersion, but the only value I want is _draftType.
The value of the _draftType field may be:
| CHANGE | Draft proposal to change an existing object. |
| DELETE | Draft proposal to delete an existing object. |
| NEW | Draft proposal to create a new object. |
| RESURRECT | Draft proposal to resurrect already deleted object. |
| VIRTUAL | Placeholder for a non-existent draft. This represents a published version. |
When the _draftType value is VIRTUAL then there is no active draft.
Finally, we have the publishedVersion section, just listing some simple attributes for the rule.
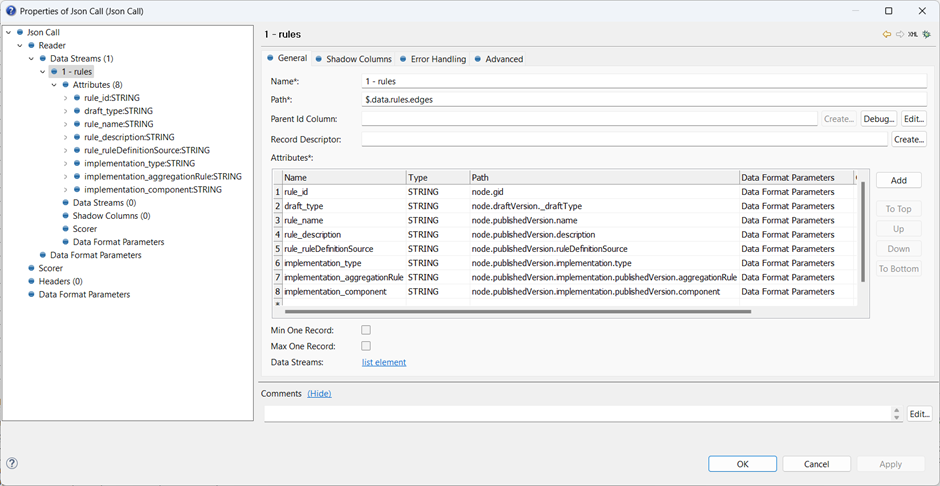
To read the returned Json response, we set up the attributes for the root level data stream, defining the base path for the Data Stream to be $.data.rules.edges. Each Attribute is then populated based on the path relative to that of the stream.
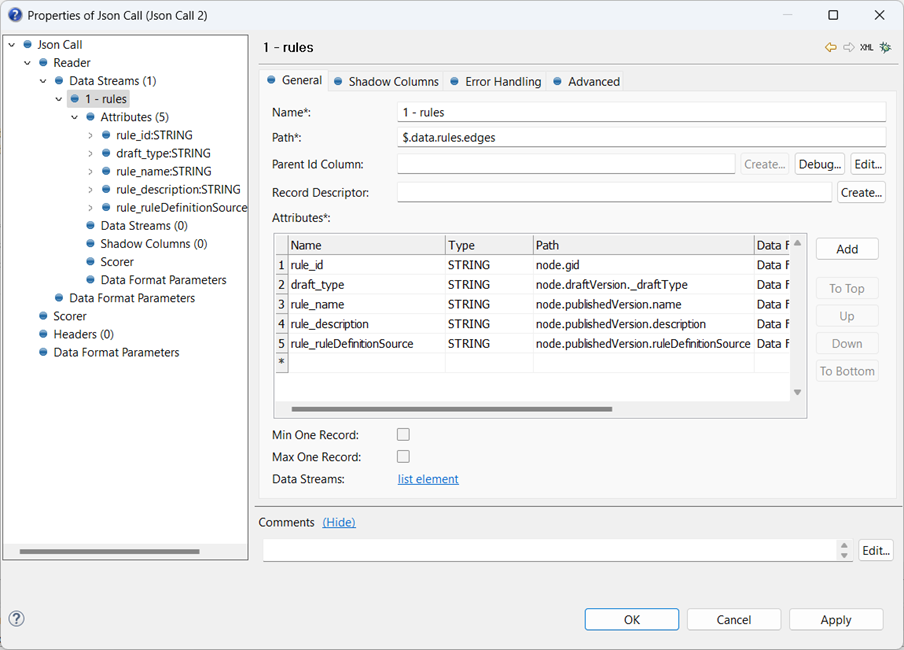
You can use whatever name you like for each attribute column, but as the flow logic gets more complex it’s a good idea to use some sort of prefixing standard, like “rule_” here.
That is enough to have a working plan:
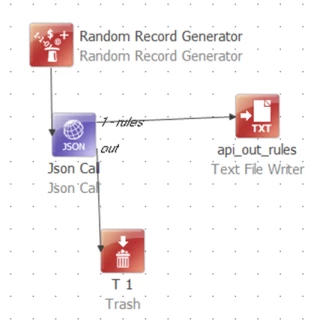
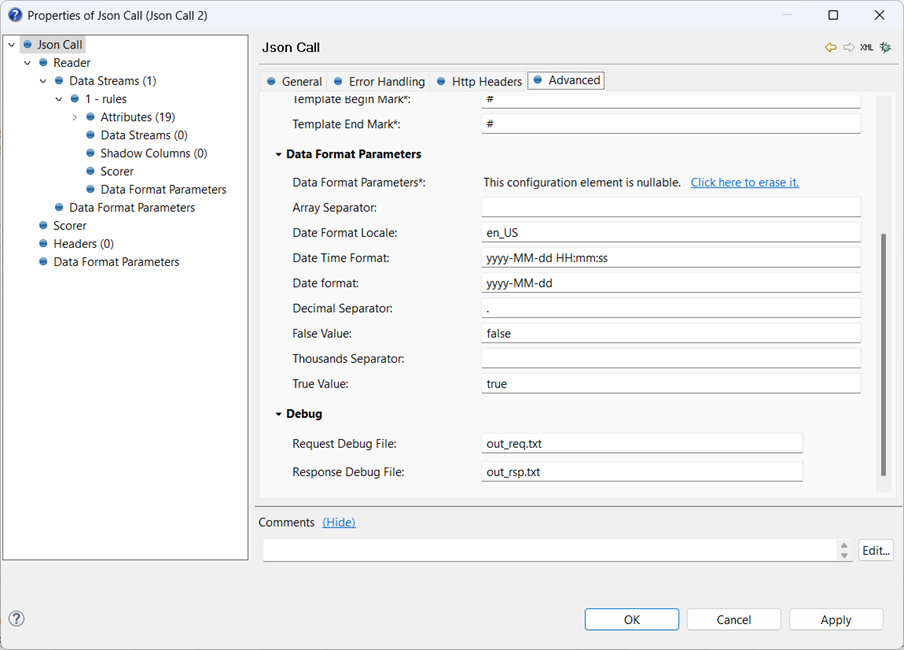
This is a good time to run the plan and make sure the expected output is written to file. If things aren’t working, it’s worth setting up request and response debug files in the Advanced tab:
Next, I want to look into the implementation of each rule. In the Metadata Explorer, rule has an attribute implementation which is of type ruleImplementation.
This is a singular noun – there is only one implementation for any given rule – so we don’t need to iterate through an array of values, and we can include the contents of the implementation in the [1 – rules] output.
The entry for the implementation attribute has a blue rectangle ‘bullet’:

If we look at the ruleImplementation entity, we see this has a set of entries with blue circle bullets:

These are not attributes. Instead, this means that the ruleImplementation may be of any of these types. We can identify the type for each implementation with the type system property, which is present on all entities. We can add a filter to the query to restrict it to return only DQ rules. Type is a system property and is represented in the query syntax as $type. The filter uses quotation marks, which have to be escaped since they have to be contained in a Json string value, and is added to the conditions for the rules element, so that it filters all rules by their implementation type:
{"query":"query q {
rules (versionSelector: {draftVersion: true} filter: \"implementation.$type =='ruleDqImplementation'\")
{...} }"}The attributes for the ruleDqImplementation entity are:

Expanding the Json call to include these changes gives:
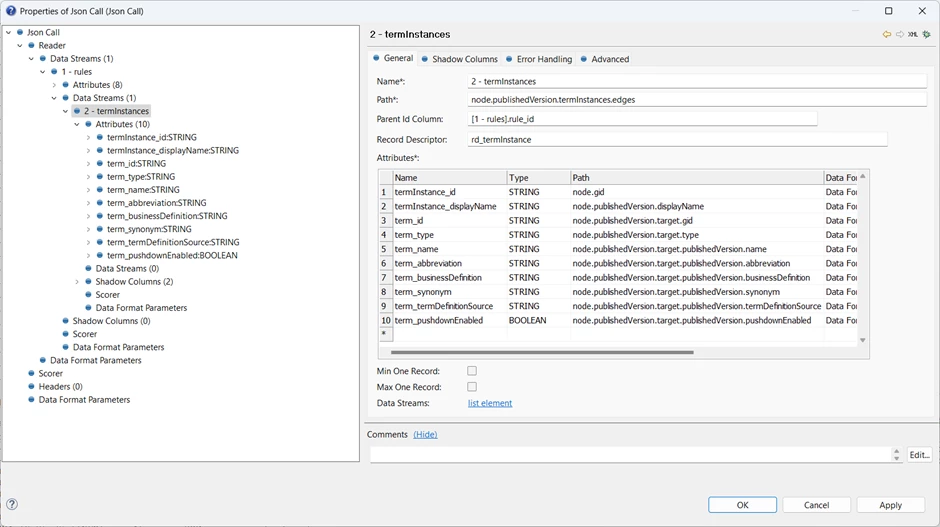
In the ONE Metadata Explorer we can see each rule contains a collection of termInstances. The attribute name is plural so we know it is an array, and the individual rows are of type termInstance.

termInstance has several subtypes, but we’re not really interested in those. We just want to link through to the term entity, which is referenced by the attribute target:
The definition for term is:

We can extend the GraphQL query and add a new data stream:
{"query":"query q {
rules (versionSelector: {draftVersion: true} filter: \"implementation.$type =='ruleDqImplementation'\") {edges {node {
gid draftVersion { _draftType }
publishedVersion {
name description ruleDefinitionSource
implementation {
gid type
publishedVersion {
aggregationRule
component
}
}
termInstances {edges {node {
gid
publishedVersion {
displayName
target {
gid type
publishedVersion {
name
abbreviation
synonym
termDefinitionSource
pushdownEnabled
}
}
}
}
}
}}}
}"
}
The attributes for a termInstance are based at each node of the termInstances collection, which in turn are relative to each node of the rules collection.
Now that we have a child data stream for termInstances, we will need to be able to link it back to the corresponding rules. This can be accomplished in three ways – all supported here.
First, we can use a Record Descriptor. This is a standard approach to grouping records in Ataccama solutions. It contains a key value, a count of grouped terms, and an ordinal position in the group, separated by colons. In this case, the key value will be the value referenced in the Parent Id Column field. Since the parent data stream is [1 – rules] and the id field value is stored into the column rule_id, this value is represented as [1 – rules].rule_id. For example, if a particular rule has two termInstances, then the values of rd_termInstance might be,
15bbce34-0000-7000-0000-0000001676a5:2:1
15bbce34-0000-7000-0000-0000001676a5:2:2
There is a dedicated Record Descriptor Join step that can be used to join rows with a record descriptor to their parent rows based on this key value.
The column rd_termInstance is declared in the Shadow Columns tab:
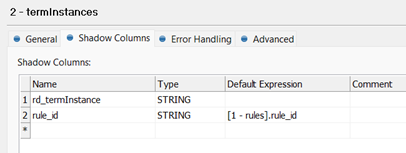
This figure also shows the second join approach: defined here is a rule_id column which is again assigned to the value of the parent key using the same expression, [1 – Rules].rule_id. The two data streams can be joined directly on this key using a Join step.
All Shadow Columns defined for a given data stream will be emitted as columns on that stream output. This technique can be used to reproduce any data from the parent stream onto the child, effectively a third way to perform a join within the Json Call step itself.
The plan now looks like this:
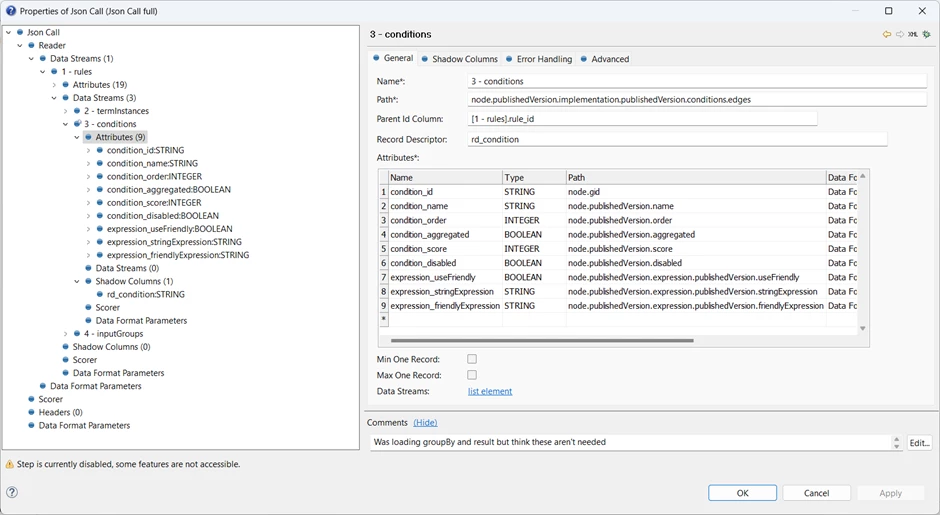
The plan can be extended in the same way to Conditions:
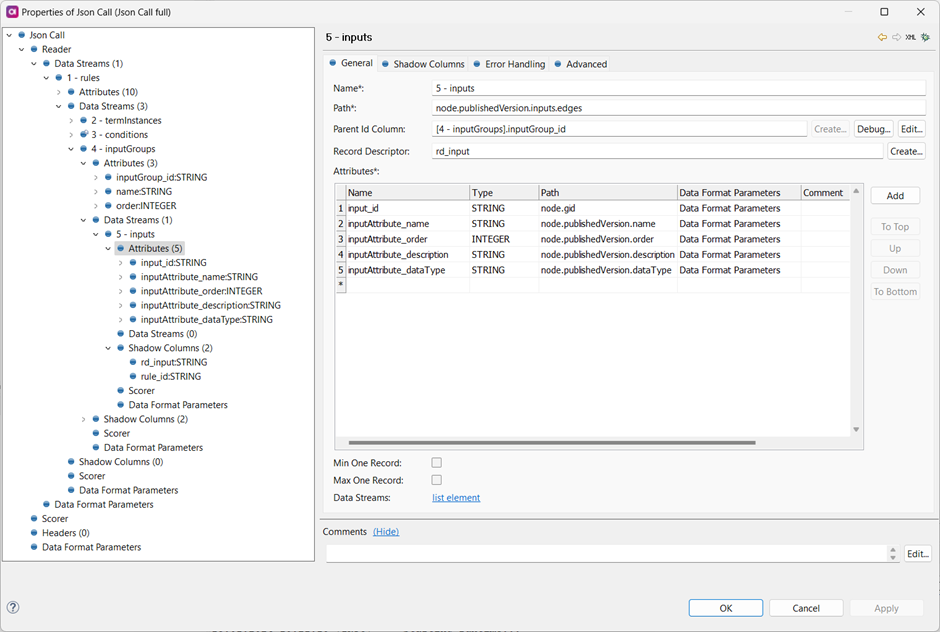
and to inputGroups:
This completes the definition of the output Data Streams, and the full GraphQL query template is below
{"query":"query q {
rules (versionSelector: {draftVersion: true}) {edges {node {
gid draftVersion { _draftType }
publishedVersion {
name description ruleDefinitionSource
implementation {
gid type
publishedVersion {
fallback { publishedVersion {result {gid publishedVersion {name} }} }
aggregationRule
component
conditions {edges {node {
gid type
publishedVersion {
name
order
aggregated
score
disabled
expression {
publishedVersion {
useFriendly
stringExpression
friendlyExpression
}
}
}
}}}
dqDimension {
publishedVersion {
name
}
}
}
}
termInstances {edges {node {
gid
publishedVersion {
displayName
target {
gid type
publishedVersion {
name
abbreviation
synonym
termDefinitionSource
pushdownEnabled
}
}
}
}}}
inputGroups {edges {node {
gid
publishedVersion {
name
order
inputs {edges {node {
gid
publishedVersion {
name
order
description
dataType
}
}}}
}
}}}
}
}}}
}"
}