Dear members,
I am struggling with a step that rather reflects query/array logic than the logic of steps available in component editor.
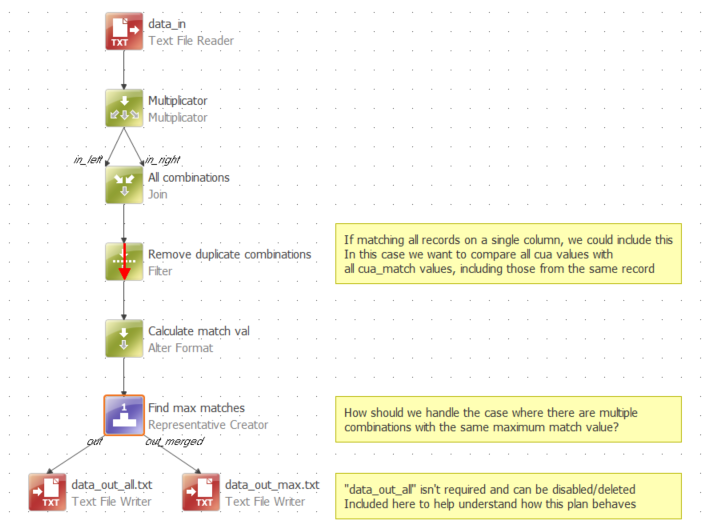
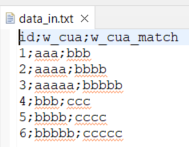
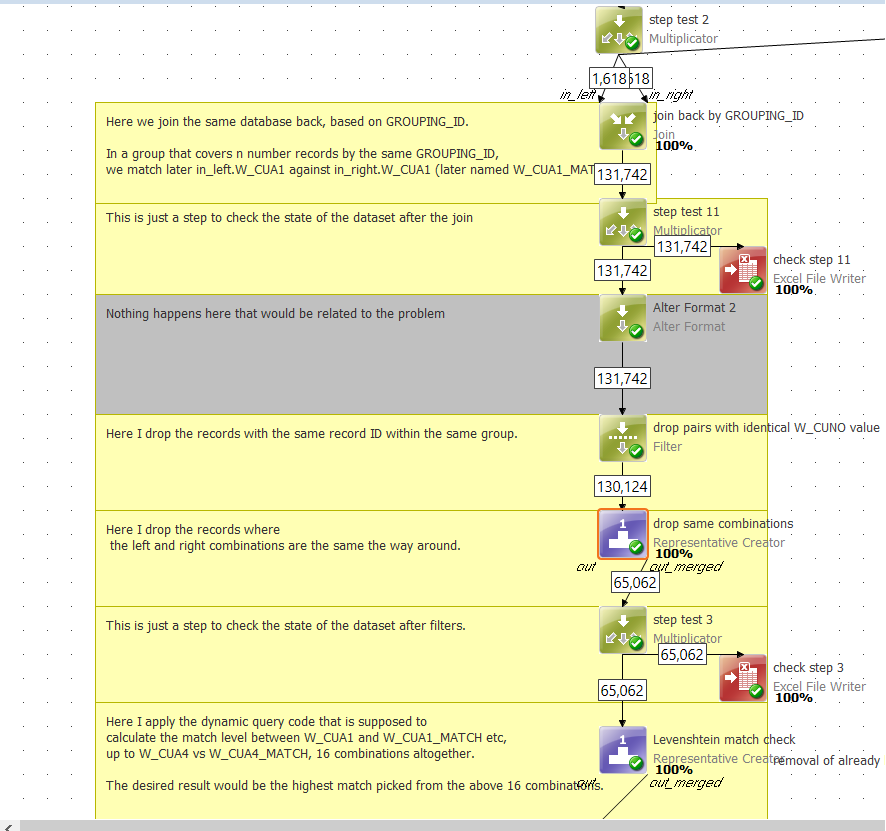
Task is to find the maximum from a range of values. I tried to retrieve it through a dynamic query written in a Representative Creator step, see details below:
L1:= round((1-(levenshtein(W_CUA1,W_CUA1_MATCH)/(max(length(W_CUA1),length(W_CUA1_MATCH)))))*100,0);
L2:= round((1-(levenshtein(W_CUA1,W_CUA2_MATCH)/(max(length(W_CUA1),length(W_CUA2_MATCH)))))*100,0);
L3:= round((1-(levenshtein(W_CUA1,W_CUA3_MATCH)/(max(length(W_CUA1),length(W_CUA3_MATCH)))))*100,0);
L4:= round((1-(levenshtein(W_CUA1,W_CUA4_MATCH)/(max(length(W_CUA1),length(W_CUA4_MATCH)))))*100,0);
L5:= round((1-(levenshtein(W_CUA2,W_CUA1_MATCH)/(max(length(W_CUA2),length(W_CUA1_MATCH)))))*100,0);
L6:= round((1-(levenshtein(W_CUA2,W_CUA2_MATCH)/(max(length(W_CUA2),length(W_CUA2_MATCH)))))*100,0);
L7:= round((1-(levenshtein(W_CUA2,W_CUA3_MATCH)/(max(length(W_CUA2),length(W_CUA3_MATCH)))))*100,0);
L8:= round((1-(levenshtein(W_CUA2,W_CUA4_MATCH)/(max(length(W_CUA2),length(W_CUA4_MATCH)))))*100,0);
L9:= round((1-(levenshtein(W_CUA3,W_CUA1_MATCH)/(max(length(W_CUA3),length(W_CUA1_MATCH)))))*100,0);
L10:= round((1-(levenshtein(W_CUA3,W_CUA2_MATCH)/(max(length(W_CUA3),length(W_CUA2_MATCH)))))*100,0);
L11:= round((1-(levenshtein(W_CUA3,W_CUA3_MATCH)/(max(length(W_CUA3),length(W_CUA3_MATCH)))))*100,0);
L12:= round((1-(levenshtein(W_CUA3,W_CUA4_MATCH)/(max(length(W_CUA3),length(W_CUA4_MATCH)))))*100,0);
L13:= round((1-(levenshtein(W_CUA4,W_CUA1_MATCH)/(max(length(W_CUA4),length(W_CUA1_MATCH)))))*100,0);
L14:= round((1-(levenshtein(W_CUA4,W_CUA2_MATCH)/(max(length(W_CUA4),length(W_CUA2_MATCH)))))*100,0);
L15:= round((1-(levenshtein(W_CUA4,W_CUA3_MATCH)/(max(length(W_CUA4),length(W_CUA3_MATCH)))))*100,0);
L16:= round((1-(levenshtein(W_CUA4,W_CUA4_MATCH)/(max(length(W_CUA4),length(W_CUA4_MATCH)))))*100,0);
max(L1,L2,L3,L4,L5,L6,L7,L8,L9,L10,L11,L12) // and here comes the trouble: Ataccama has no formula to pick maximum from an N number range but from 2 sources at a time.
Independently from above logic, the case can be simplified as below:
L1:= levenshtein(W_CUA1,W_CUA1_MATCH) //everything else is just custom calculation, we can restrict the case to basics
L2:= levenshtein(W_CUA1,W_CUA2_MATCH)
L3:= levenshtein(W_CUA1,W_CUA3_MATCH)
etc.. to L16.
It is already annoying that there is no loop function in code writer function, but having no chance to set a simple rank or choose a maximum NOT from a certain column but across different variables is something I cannot believe.
Could anyone help me out with a solution?
What I want finally is:
- to get the maximum match
- to get the name of two fields that provide the highest match, such as ‘W_CUA3,W_CUA1_MATCH’.
Thank you in advance!