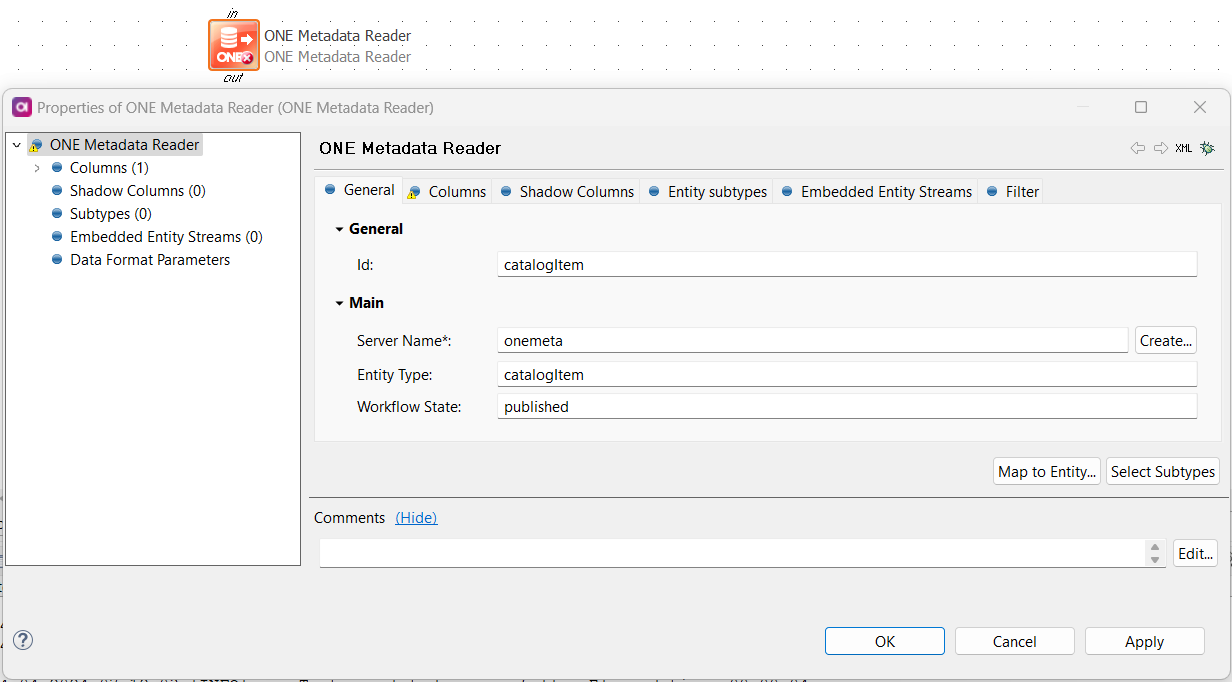
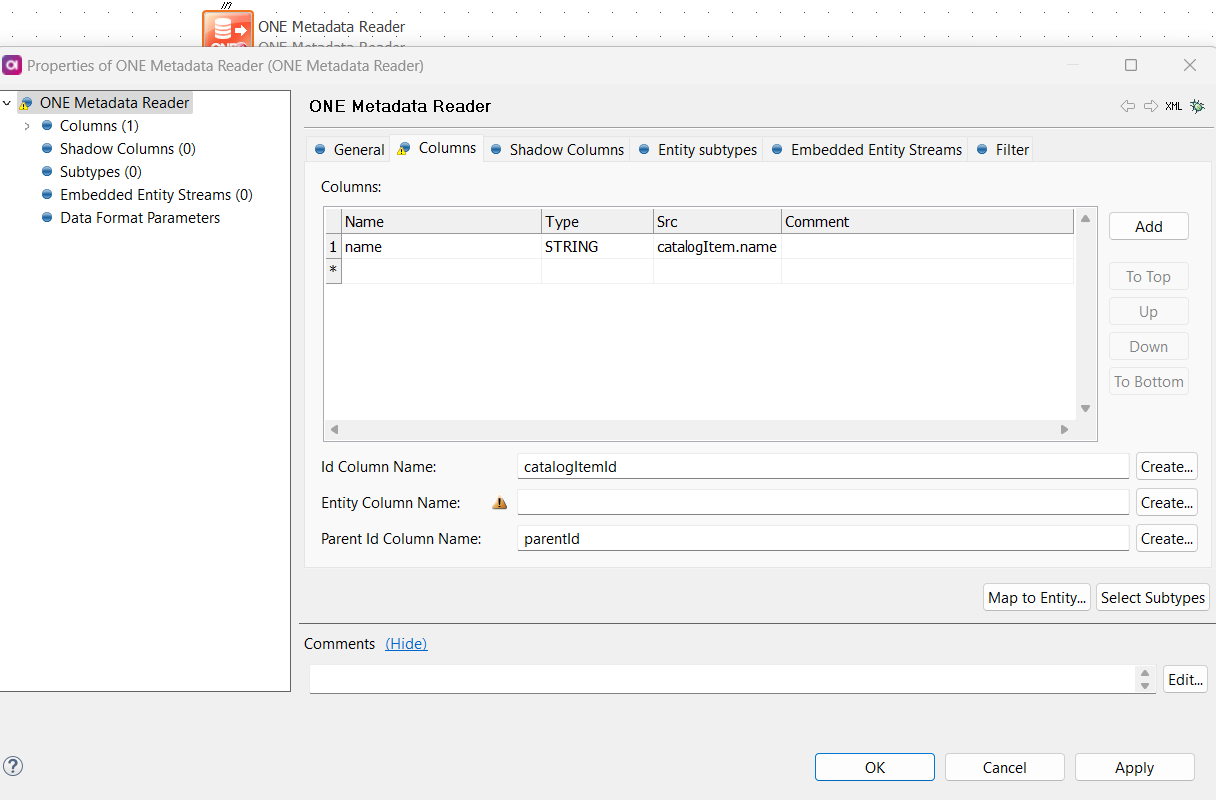
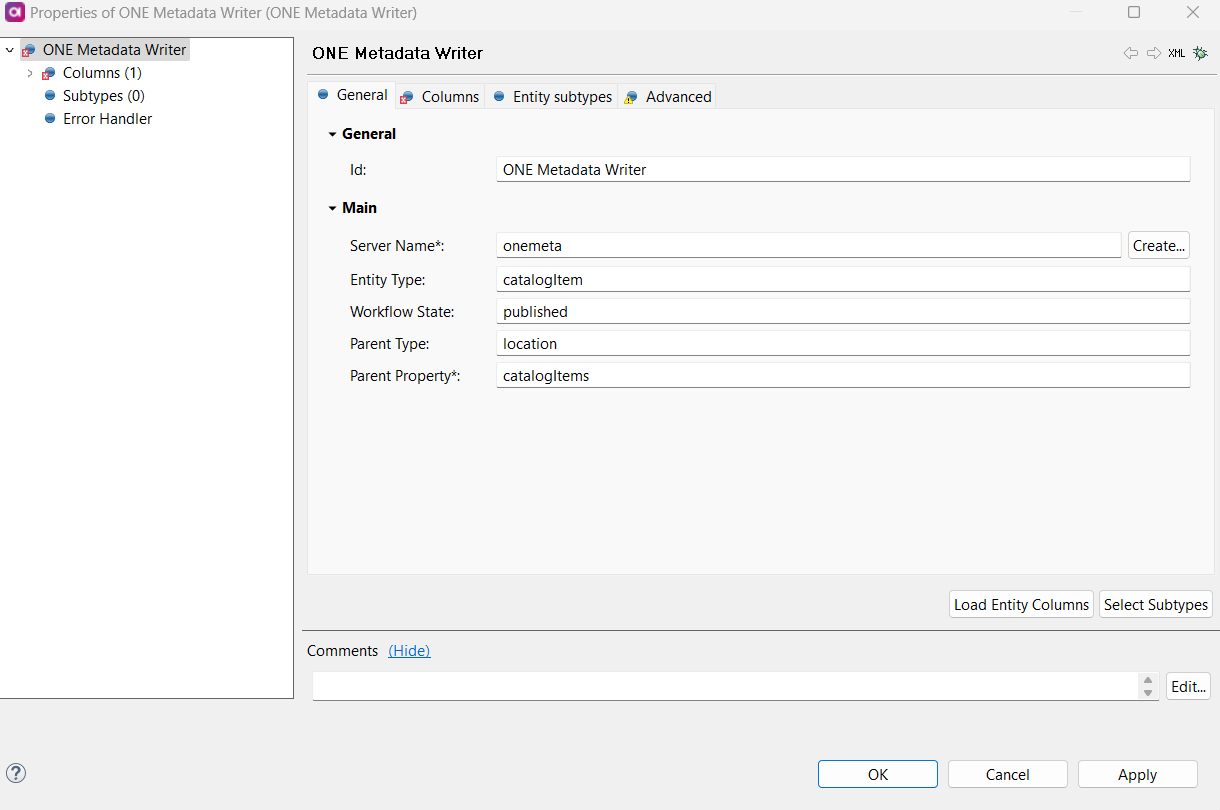
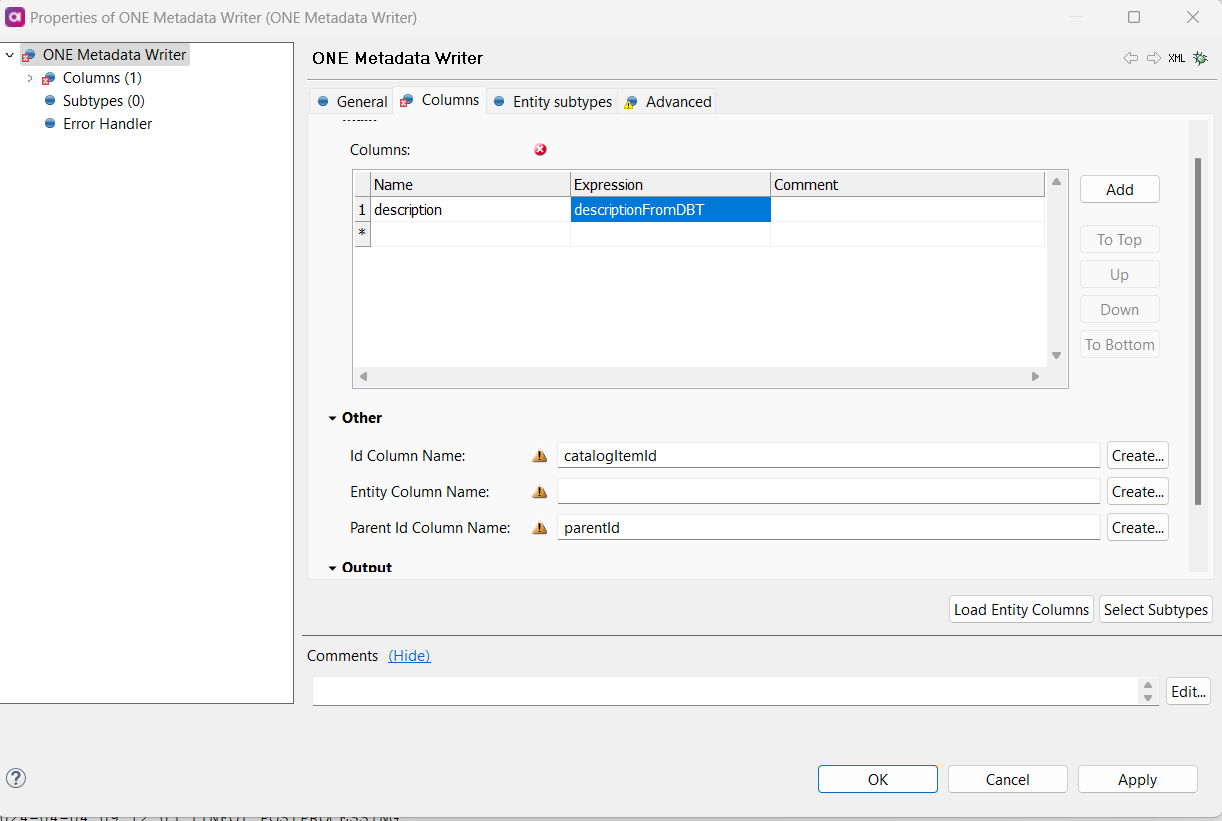
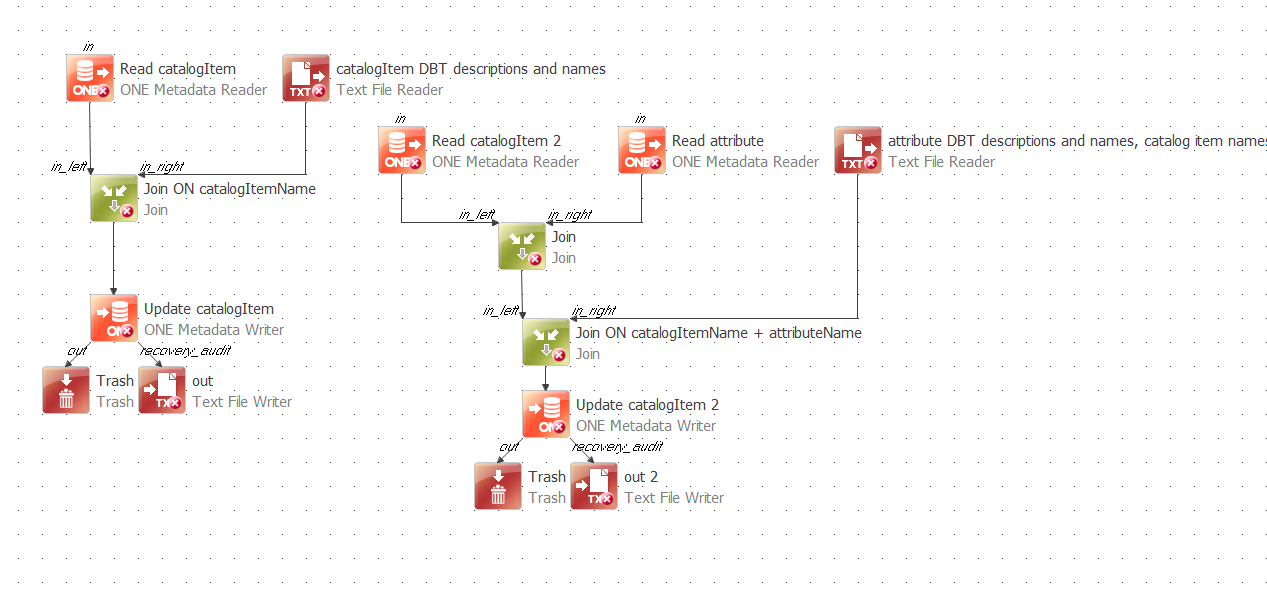
We are using dBT for our data pipelines, and for the tables and fields, there is description maintained in dBT that we would like to export (json) and update Ataccama Data Catalog.
Is there a known, trusted, supported way to automate this?
I already do have a desktop plan i created that can update catalog objects and attributes based on a excel input file. I may be able to modify that if thats the only option. Iam reaching out to the community to see if there is a preferred way to get descriptions and documentation from dBT to Ataccama.