Term suggestions overwhelming - How to tweak and make it stop.
Hi,
We've loaded 2000+ terms and assigned those with desktop as a migration from a data dictionary. When we now have new catalog items, Ataccama suggests 20+ terms for a CI Attribute. This is not usable.
How we tweak it to:
Limit to only top 5
Stop when a term is already assigned.
And here's an idea: If the column header is the same or can be matched using a simple fuzzy match, that is a better indicator than most AI.
Another: Please skip some of the datatypes, a boolean … probably not a good idea.
Any idea's?
We are also wondering if we can turn it off.
Thank you in advance!
Marnix
Page 1 / 1
Hi!
Thanks for your feedback, I will hand it over the our engineering team.
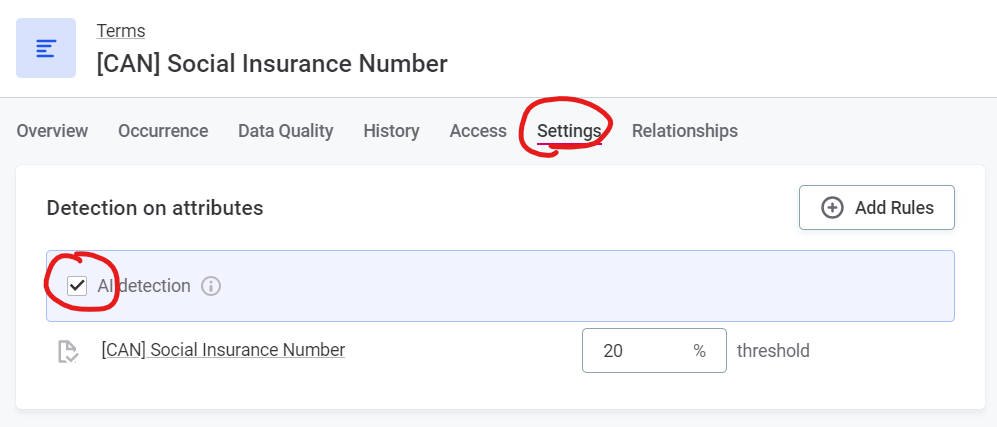
Now, as for the amount - is it all AI or do you also use detection rules? If a detection rule is too general, it can be incorrectly assigned to attributes that don’t contain the desired data. In this case we recommend to remove it or tune it’s configuration (either change the expression or change the threshold, see below printscreen). As you mention, boolean values often cause an issue because they can be found in some lookups we use out of the box, e.g. for cities or names. In these cases AI is usually much better, but it needs to be trained.
Also, if you start rejecting or approving the suggestions, AI will recompute the suggestions and some should disappear (but of course also appear). In general the more you reject, the more conservative the AI should become and start suggesting much less.
AI can be turned off for each term, just uncheck the AI enabled checkbox:
If you want to remove the detection rule, you need to unassign it from the term settings.
Lastly, regarding the headers → this is actually comming is some of the future releases (14.4 I believe), AI will consider additional metadata for terms like attribute names, tables names etc.
Please let me know if you have additional questions.
Kind regards,
Anna
Thank you so much!
Thanks @Marnix Wisselaar for the feedback and questions! @anna.spakova gave already a comprehensive answer, but let me add a few points. I will just emphasize that the AI is designed so that it starts very general and “dumb” and adapts to the particular terms and data of each customer. So it is really important to be not only accepting the correct suggestions, but also removing the incorrect ones in order not to bias the algorithm. It might seem tedious in the beginning but it should adapt fairly quickly and most of the wrong suggestions should disappear. Keep in mind that it learns independently for each term, so even if for one it already works well because a user already accepted and rejected tens of suggestions, for another one it might still not be optimal it the algorithm does not have enough feedback. As @anna.spakova write, the algorithm works also with attribute names and other metadata since version 14.4. However, even in this version it does not take into consideration other terms already assigned to the attribute, this is something we need yet to improve. And last point - in earlier versions the AI algorithm learns also from the terms assigned by manual rules which can be sometimes wrong and this is often the main cause why it delivers obviously wrong suggestions. Since 14.4 this behavior is configurable and disabled by default, so it is learning just from term assigned explicitly by a user.
Hi PetrD,
There is always theory and practice. We migrated over 2000 terms from a data dictionary. We linked those to the CI Attributes. So to me Ataccama has ability to ‘learn’.
Then two other points:
It is too tedious to go through way too many suggestions.
It becomes even more tedious if a user has to keep doing this when there is already a term linked to a CI Attribute.
But we also think we observer AI missing some of the obvious:
An int might be a sequence-number, but it keeps coming up with other ints.
Birthdates and other dates, like loan start date or taxation data, have a certain period (min-max). But it keeps coming up with the idea that ‘a date is a date’.
Is the AI single column or multiple colums? So does it use other columns in a table as context?
I agree with you that the algorithm is far from ideal and I am trying to propose some solutions how to make it work better. One of them is to provide also negative examples together with the positive ones. After the migration it now sees 2000 correctly assigned terms and 0 rejected ones, so it is overly confident in the suggestions and they are often wrong. I suggest to start rejecting the suggestions and after a few rejections you should see most of the false positive suggestions for given term to disappear (after they are recomputed, which might take from minutes to hours depending on the total number of attributes in the catalog - see here).
An int might be a sequence-number, but it keeps coming up with other ints.
Birthdates and other dates, like loan start date or taxation data, have a certain period (min-max). But it keeps coming up with the idea that ‘a date is a date’.
The semantics of numbers is currently not understood by the algorithm, so if does not work well on these cases. However, even here it helps if it has not only positive examples, but also diverse negative examples where the term does not belong.
Is the AI single column or multiple colums? So does it use other columns in a table as context
No, it currently does not use the other columns of metadata from the table, just the data content of a single column. From 14.4 it uses some metadata related to the attribute, catalog item or source where they are located, but still not combining the knowledge from multiple columns.
Can I automate the refusals. I see via the mm-reader there are attributes. But when I delete the suggestion, it seems to come back with the same suggestion. So do I only set the attribute?
Yes, you can. There is a special GraphQL mutation for it: