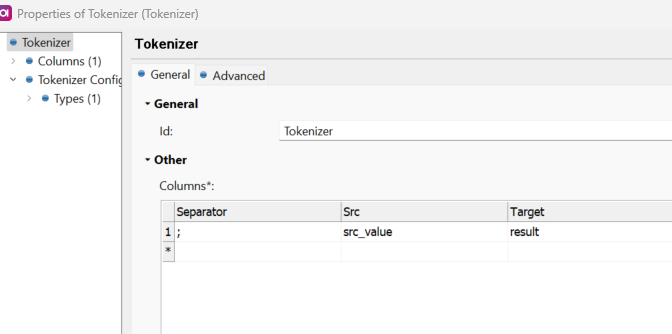
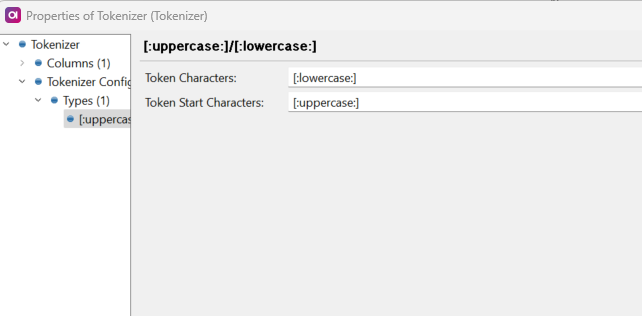
I am trying to use Splitter to transform the string
Example : Input: BeWhoYouAre
Splitter output - ‘e ho ou re’ - skipping the first letter as ‘Upper case’ is the separator
Desired output - ‘Be Who You Are’
How do I achieve this? Also if the string is all lower how to split it?
Example: Input: ‘bewhoyouare’
desired output - ‘Be Who You Are’