
I’ve been working on a use case recently which I think may be of interest to the community here.
- Some reference data is stored in a single table
DATA_KEY_IDcolumn tells us what reference data set it isDATA_VALcolumn stores the actual reference data in the format of a json array- Goal is to extract the values from the json array, and use it as a lookup item in Ataccama ONE, which in turn is used in Data Quality Validation rules
To start with, you need to have some preview access to the data and understand the schema of the json. For the example in this post, I have very simple “id” and “name” properties for my json. You will need to analyse that data before starting this, so you know what to put into the Json parser, or which values you want to get out from the json object.

Solution 1: Virtual Catalog Item (VCI)
- Bring the reference data table into Ataccama ONE
- Build a VCI, with a Catalog Item Reader of the reference data table
- Use a filter step to filter the exact set I need (it will all be contained within 1 row of source table)
- Use a Json Parser step to parse the json from
DATA_VALcolumn - Link it to the integration output
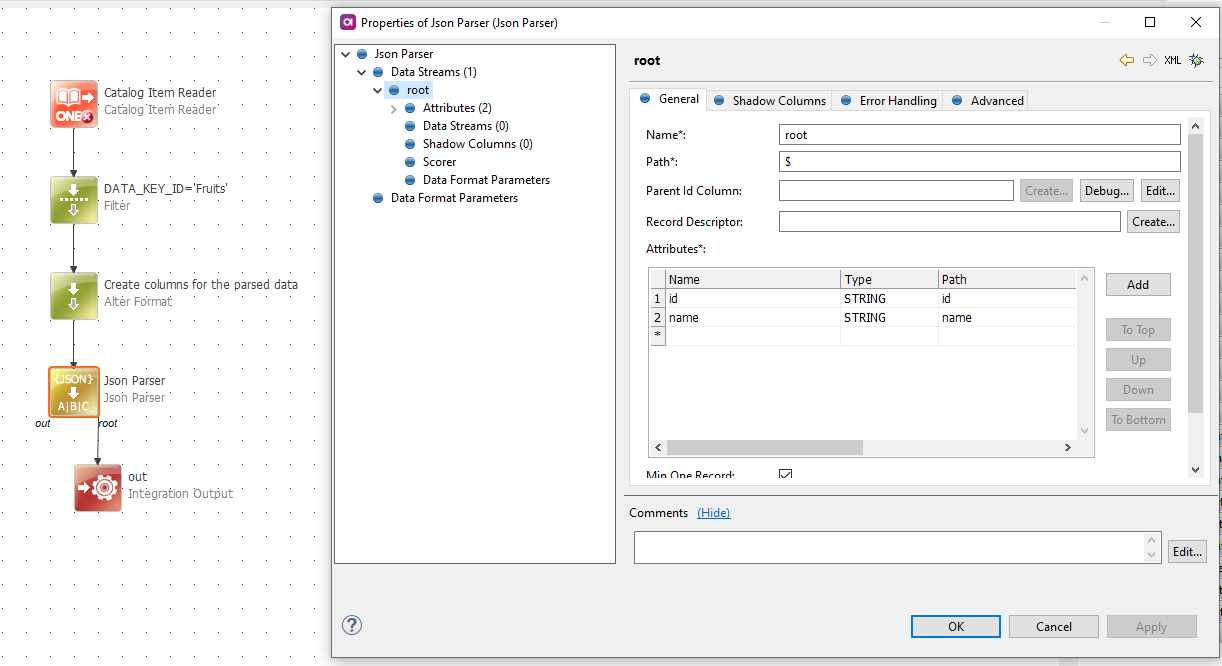
(Please excuse the red x on the Catalog Item Reader as this is just an example…)
- Profile this VCI
- Create a lookup based on the column that we need
- If required, schedule refresh of the lookup item
Pros:
- Universal. You can reuse this with pretty much any underlying technology, because once data enters Ataccama it becomes source and technology agnostic
Cons:
- Creation of VCI takes a few steps
- The Catalog Item structure is just that little bit more complex
- Needs ONE Desktop to access the logic as it won’t be visible in the web application.
Solution 2: SQL CI
Solution 2 is very similar to the above, but instead of VCI, we use an SQL CI.
My customer’s technology is Databricks, so the SQL syntax is specific to Databricks. Other SQL flavours will have their specific syntax to parse json.
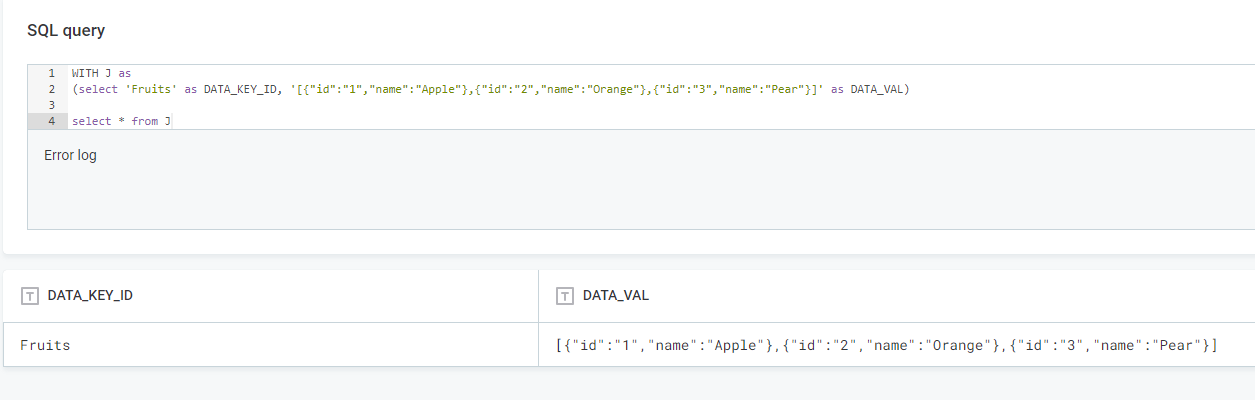
- For the interest of keeping customer data confidential, I’m using a with statement to virtualise my table here.
WITH J as
(select 'Fruits' as DATA_KEY_ID, 'u{"id":"1","name":"Apple"},{"id":"2","name":"Orange"},{"id":"3","name":"Pear"}]' as DATA_VAL)
select * from J
In reality, your starter query might look more like this:
WITH J as
(select DATA_KEY_ID, DATA_VAL from REF_DB.REF_DATA_TABLE where DATA_KEY_ID='Fruits')
select * from J
The query preview in the “Create SQL Catalog Item” screen will look something like this:
- Now we need to convert that
DATA_VALinto an array type, as it is a string at the moment in my source. We use the FROM_JSON function and specify ‘array<string>’ type.
WITH J as
(select 'Fruits' as DATA_KEY_ID, 'l{"id":"1","name":"Apple"},{"id":"2","name":"Orange"},{"id":"3","name":"Pear"}]' as DATA_VAL),
T as
(select FROM_JSON(DATA_VAL,'array<string>') as V from J)
select * from T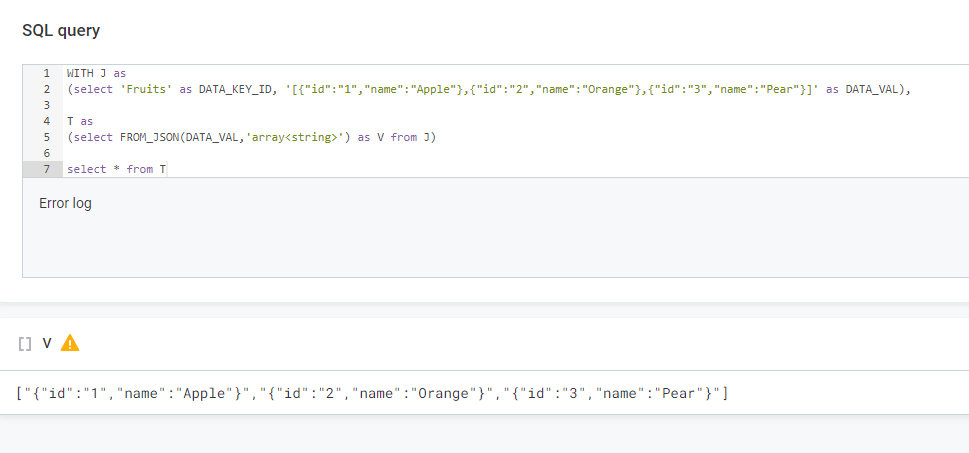
- Next, use the LATERAL VIEW EXPLODE command to split the records
WITH J as
(select 'Fruits' as DATA_KEY_ID, 'l{"id":"1","name":"Apple"},{"id":"2","name":"Orange"},{"id":"3","name":"Pear"}]' as DATA_VAL),
T as
(select FROM_JSON(DATA_VAL,'array<string>') as V from J),
E as
(select * from T lateral view explode (T.V) as B)
select * from E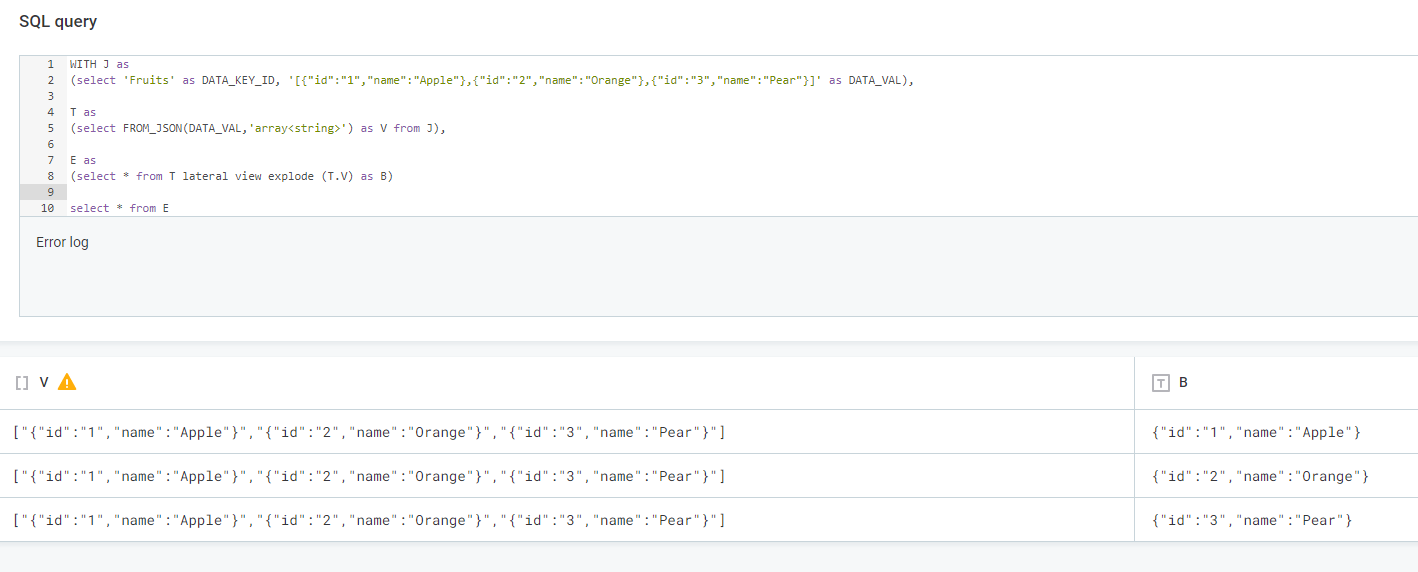
- Now we can extract the actual “id” and “name” from the json. We use the json path to retrieve our values. We don’t need to select the array anymore as we are only interested in the scalar values.
WITH J as
(select 'Fruits' as DATA_KEY_ID, ' {"id":"1","name":"Apple"},{"id":"2","name":"Orange"},{"id":"3","name":"Pear"}]' as DATA_VAL),
T as
(select FROM_JSON(DATA_VAL,'array<string>') as V from J),
E as
(select * from T lateral view explode (T.V) as B)
select
E.B:id,
E.B:name
from E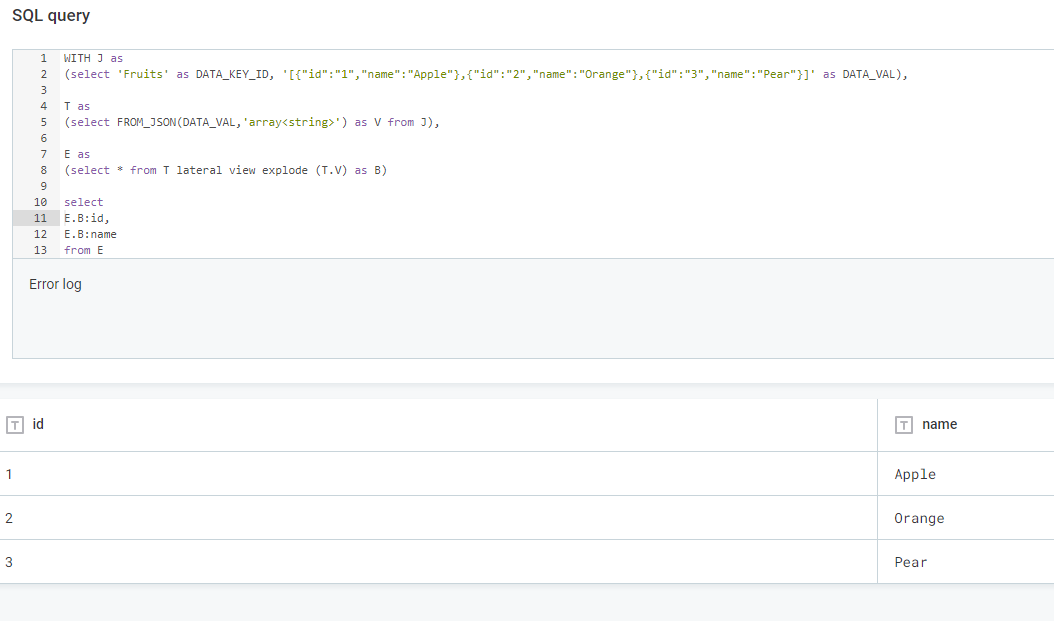
Pros:
- No need to do a VCI. SQL CI is a catalog item wholly maintained in ONE web application
Cons:
- Specific SQL flavour syntax required
There we have it! We used Databricks SQL to parse a json array and put into individual records.
Once you have profiled this SQL CI, you can then create a lookup on the web application based on the column that you want, and optionally you can put a time schedule to refresh the lookup in case it updates.
Please feel free to share json parsers of other SQL flavours you have here!
Final thought:
I spent a fair few hours in the evening Googling to get to the above conclusion, and one of the articles that provided a most useful hint was this one, which compares json parsing syntaxes between various flavours of SQL (Synapse, Big Query, Databricks and Snowflake). If you are reading this article chances are you may be trying to do the same thing but not the exact same SQL tech, it’s worth a read.