Two records as same correation id and same version number one should process another one should error out how to implement this logic in ataccama

Two records as same correation id and same version number one should process another one should error out how to implement this logic in ataccama
Hi! On ONE app you can create uniqueness rules, these uniqueness rules will point out records that failed due to them having some duplicated ID. Since you mention it will have an ID and a VERSION, I would use an aggregate rule, that way its groups by ID and VERSION so if there's a duplicate of ID + VERSION it will show the failed records. Note, it will show for all duplicates, including the first instance of this tuple combination
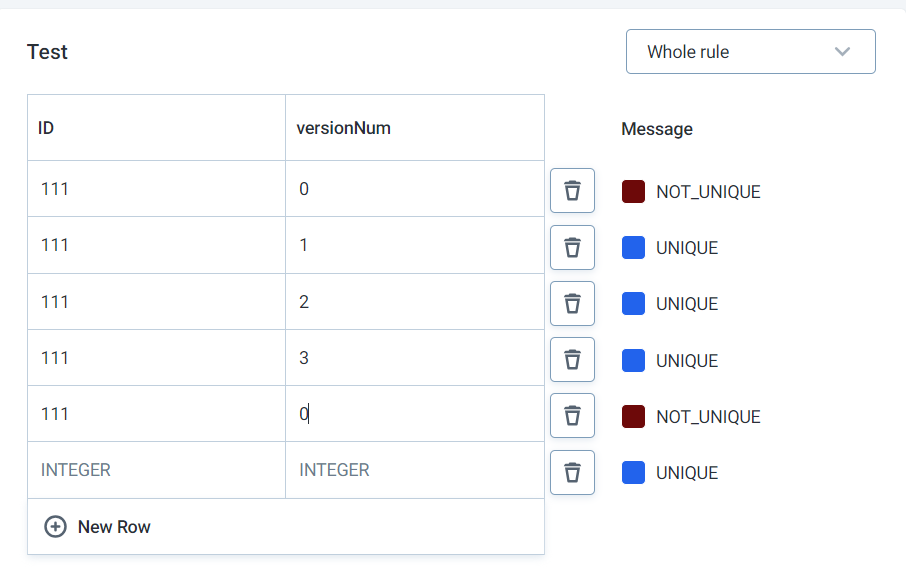
Can you provide some steps on how to configure in Ataccama.
Hi
What you would need to do is:
Once this is completed, you can test it using the test rule button towards the top, you can use the sample image I put in the previous post as a guideline for how it should look
Hope this helps :)
Hi
Hi
If you would like to do something similar to this on one desktop, I reccomend you use a record descriptor builder.
You will have your data file being read in, lets say it will have ID column and versionID column.
When you add in the record descriptor builder, you will make the expression be ID+versionID (this makes it so if both ID and version ID are the same, it is a duplicate), what you will then do is add that descriptor created into a new column called descriptor or whatever you would like to call it. That descriptor column will hold 3 numbers per cell, the first number is just like an ID number for that group (ID+versionID), the second number is the group size, so if theres duplicates with the same ID and versionID the group size will be higher than 1. The last number we can consider it to be like the specific instance in that group. So it will look like this:
| ID | versionID | Descriptor | Duplicate |
|---|---|---|---|
| 1 | 1 | 1:1:1 | FALSE |
| 2 | 1 | 2:2:1 | FALSE |
| 2 | 1 | 2:2:2 | TRUE |
With some additional logic additions we will make, we will get it to say that the 3rd record there is a duplicate
Once your record descriptor configuration looks something like this:
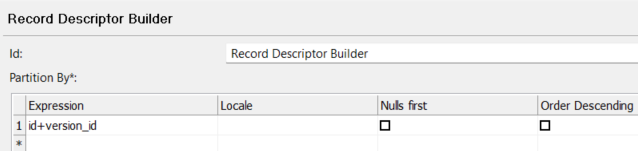
We can now do the final part which is configure the “Duplicate” boolean column. The duplicate column should only display if a record is a duplicate(TRUE) if the rightmost number is larger than 1, and display as unique(FALSE) if the rightmost number is 1. To do this, we will use the lastIndexOf() function, which will look for the last Index of “:” which is what separates the 3 record descriptor numbers. This is the expression:
iif(toInteger(substr(descriptor, lastIndexOf(descriptor, ':')+1)) = 1, FALSE, TRUE)
Its basically checking if that last digit is equal to 1 (the first instance of this ID + versionID) or not, meaning if not then its a duplicate. You will set the “duplicate” boolean column to be equal to that equation. This is a sample of how the final result would look like:


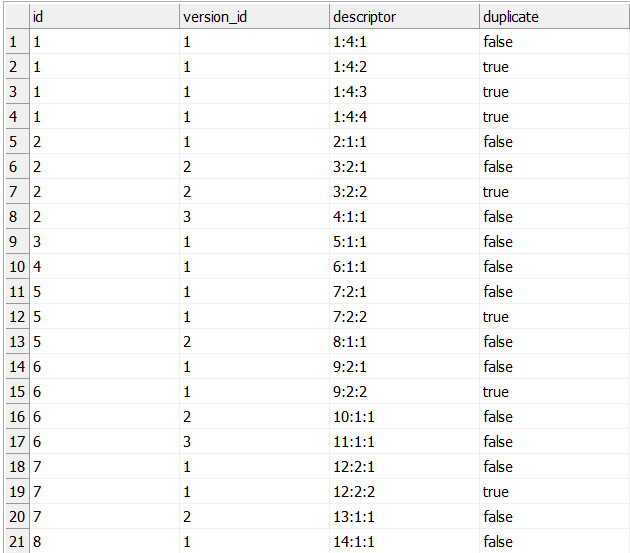
If you have any more questions feel free to ask! :)
Hi
Thats great! Im glad to be of help :)
Hi
Hi, in the case of streaming it will be a bit different. Since streaming is usually 1 by 1, and in this case lets say its batches of 10,000 streamed records per batch, there could be chances that the duplicate record can come in a couple of batches down the line and it wont be picked up as the record descriptors will be made unique per batch. The best workaround I would say is to send the batches to a database table that has a compound key constraint on ID+VersionID so that the jdbc writer will throw the error regarding “duplicate key constraint”
Hi
Could you help me with how to implement logic in Atacama ONE Desktop to include '+' signs, numbers, space, 'X', ‘x’ and '-' in phone numbers while excluding all other special characters and letters? The ready-made clean component does not support this.
Hi
remove accents
remove repeated chars
squeeze whitespaces
uppercase
substitutions
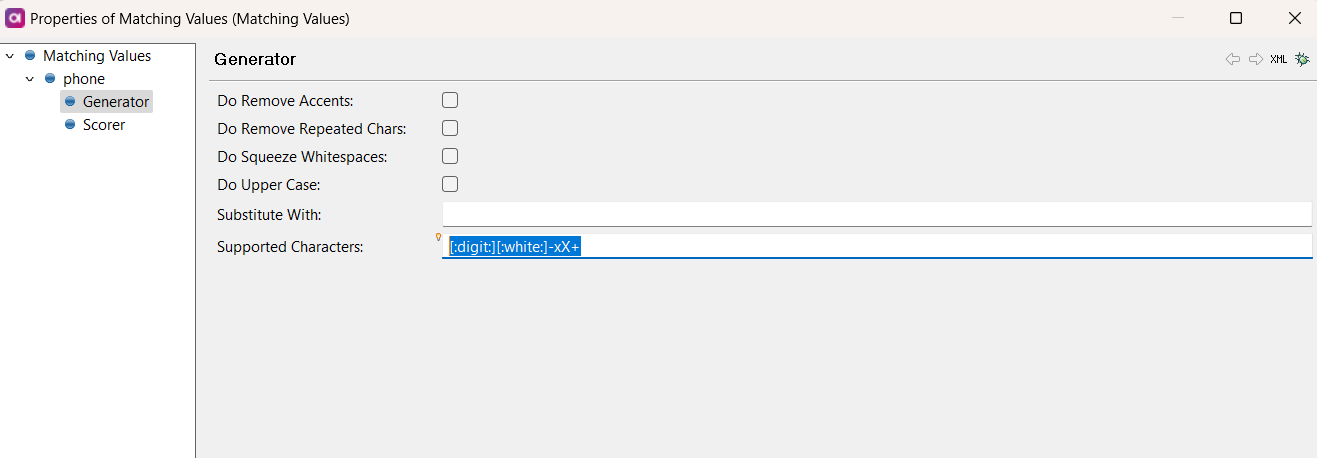
supported characters
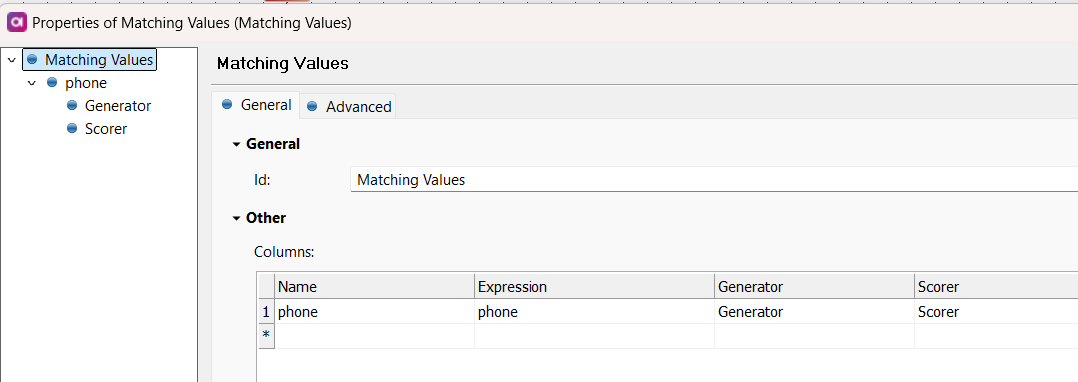
For your specific task, I recommend using the supported characters box to fill out which characters will be supported in your use case. For your specific use case i recommend doing �:digit:]::white:]-xX+
This will ensure only digits, white space (space) - x X or + are characters showing in your phone columns.
I will attach below an example of how this works:
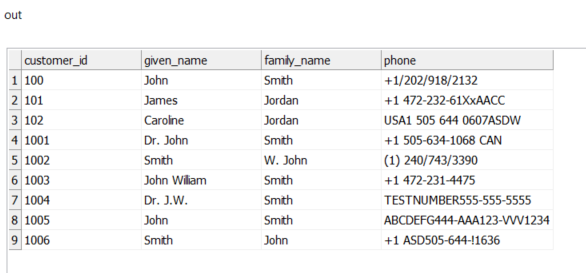
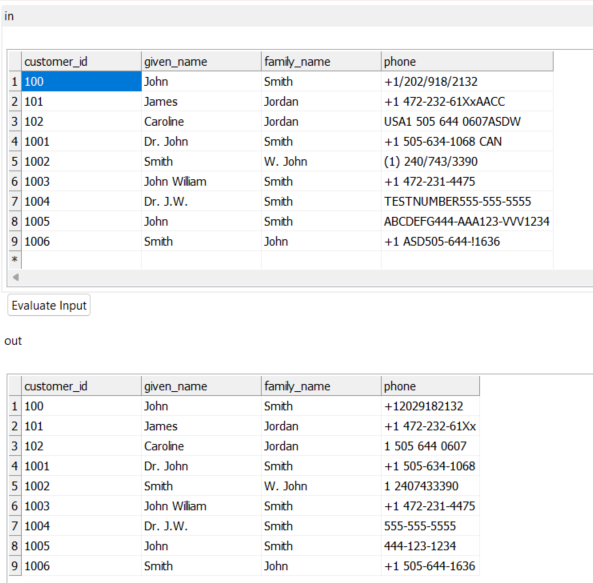
Hope this helps!
Hi
No account yet? Create an account
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.