Would there be a way in Ataccama Desktop to select records from for instance entity term that have been inserted/updated/deleted from a certain datetime, like the Published on datetime in the History tab? My intention is to use the metadatareader to read the details from term and then use this mutation datetime in the filter in the metadatareader.
Kind regards,
Albert
Page 1 / 1
Hello @Albert de Ruiter,
Ataccama is internally working with history change number (HCN) instead of the timestamps, so you can use that for the filter. How to get the HCN for your specific date is explained in this article, which could give you also some idea of how to work with the delta changes in general:
Let me know if the article helps or if you have more questions.
Kind regards,
Anna
Hi @anna.spakova, thanks for the article. Will need some time to consume it, but it looks exactly what I am looking for. Thanks!
Kind regards,
Albert
Hi @anna.spakova , I (finally) had some time to dive into this. Very convenient that the article also provided sample plans!
Your article describes how to use the hcn number/datetime as filter in a metadata reader. My use case is a bit broader, starting with the filtering in the metadatareader based on the hcn, but then in addition I want to write the records including the record's hcn timestamp.
Based on what I found in the metadata model I see it involves mmdHcnTimestamp, system, mmd and mmdNode and did some experimenting with it, but without results (apart from hanging the plan's execution).
Do you have an idea on how to implement the requirement of adding the hcn timestamp to the records?
Kind regards,
Albert
Hello Albert,
I believe that the hcn number is created automatically the moment you create the record (as it is a change from ONE perspective). Why would you want to write some custom hcn number? I think that could cause some inconsistency in the database as this is handled by the system itself.
Kind regards,
Anna
Hi Anna (@anna.spakova),
Apologies for not being clear about my usecase, especially about the ‘writing'-part. The usecase would have the following high-over steps:
With a metadatawriter read terms, with the filtering based on hcn number/timestamp as described in the article.
Retrieving the hcn datetime of the read terms and adding these to the term details of previous step
Final step is writing the term details with a jdbc-writer to a database, with the hcn timestamp as mutation date.
I hope this makes my usecase more clear.
Kind regards,
Albert
Hello @Albert de Ruiter , so it’s just about having the timestamp in the output?
If so, a simple “trick” is to join the output from the JSON call to your terms output - the JSON call response should be just 1 row, so a simple join with “1=1” as a condition should do the trick without multiplying the records.
It’s true that the metadata reader won’t let the previous columns continue in the flow, so you have to always do some joins in these cases.
Plan attached → I didn’t test it but I think it should work. Let me know if not :)
I hope this helps.
Kind regards,
Anna
Hi @anna.spakova ,
But that one hcn timestamp that is used for filtering (select all term mutations from that timestamp on) will then be shown as mutation date for each term, which is not the same.
In other words each term mutation has it own hcn mutation date. Although I am always in for simple tricks, I'm afraid this one won't do ;-)
Kind regards,
Albert
Hi @Albert de Ruiter , I get you now Sorry, took me a while to understand the request. So the query returns all terms that changed since some timestamp, and you want the timestamp of the LAST change of each of the term? (let’s say some will change multiple times during the period of time you are querying).
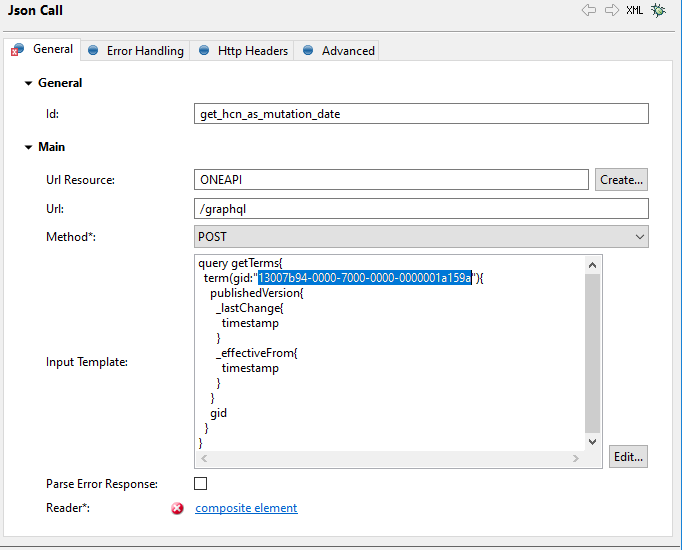
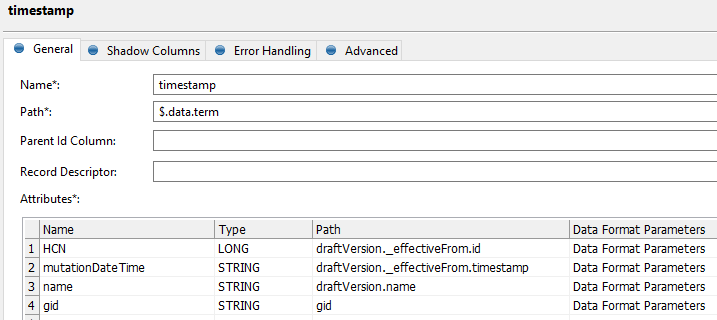
Give me some time to think about it, but once you have the term ID, you should be able to get details for it through API, including the hcn and for that you can get the timestamp (the one metadata reader doesn’t offer this). I just need to search for the proper syntax.
Kind regards,
Anna
Hi @anna.spakova ,
I guess that should be the hcn timestamp for each term that is retrieved by the ‘get terms’ json call.
Thanks a lot for all yout effort !!!
Kind regards,
Albert
Hello @Albert de Ruiter ,
so I see for example this query that returns a timestamp for the last change as well as effective from for the current published version:
Would that work for you? You can parametrize the gid for the terms so that it returns the timestamp for all terms in your flow. Let me know if you need assistance with that, I can put it into the plan.
Kind regards,
Anna
Hi @anna.spakova ,
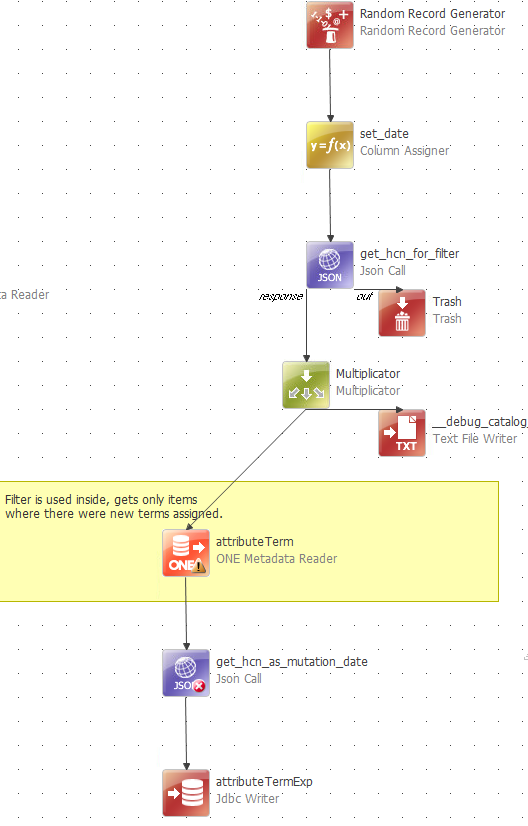
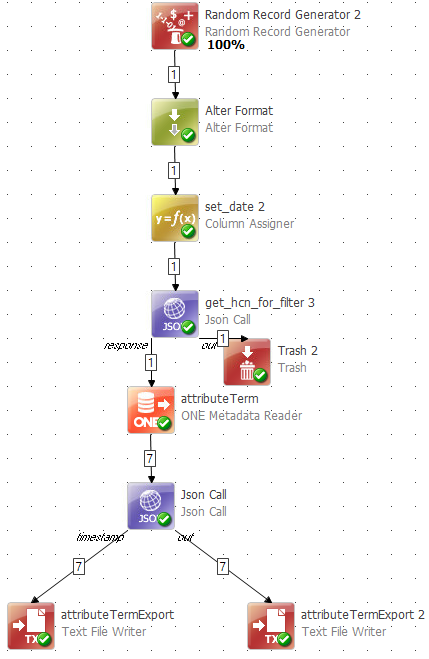
My plan is now like this:
So I filter the attribute terms based on the hcn number as per your description, following I added a new json call containing your latest query. I am not yet very familiar with these json calls, so I was wondering how to use the attributeTermID (from the previous metadata reader step) as parameter.
Thanks and kind regards!
Albert
Hello @Albert de Ruiter ,
to parametrize certain parts of the JSON call body, use the hashtag # sign, so e.g.
The part between the hastags has to be a valid column name from the incoming flow (otherwise the JSON call will report an error). When executed, you can check that the parameter was correctly translated in the request → you can enable the request/respose log under the Advanced tab of the JSON call (at the bottom).
Let me know if there is anything else I can help you with.
Kind regards,
Anna
Hi @anna.spakova ,
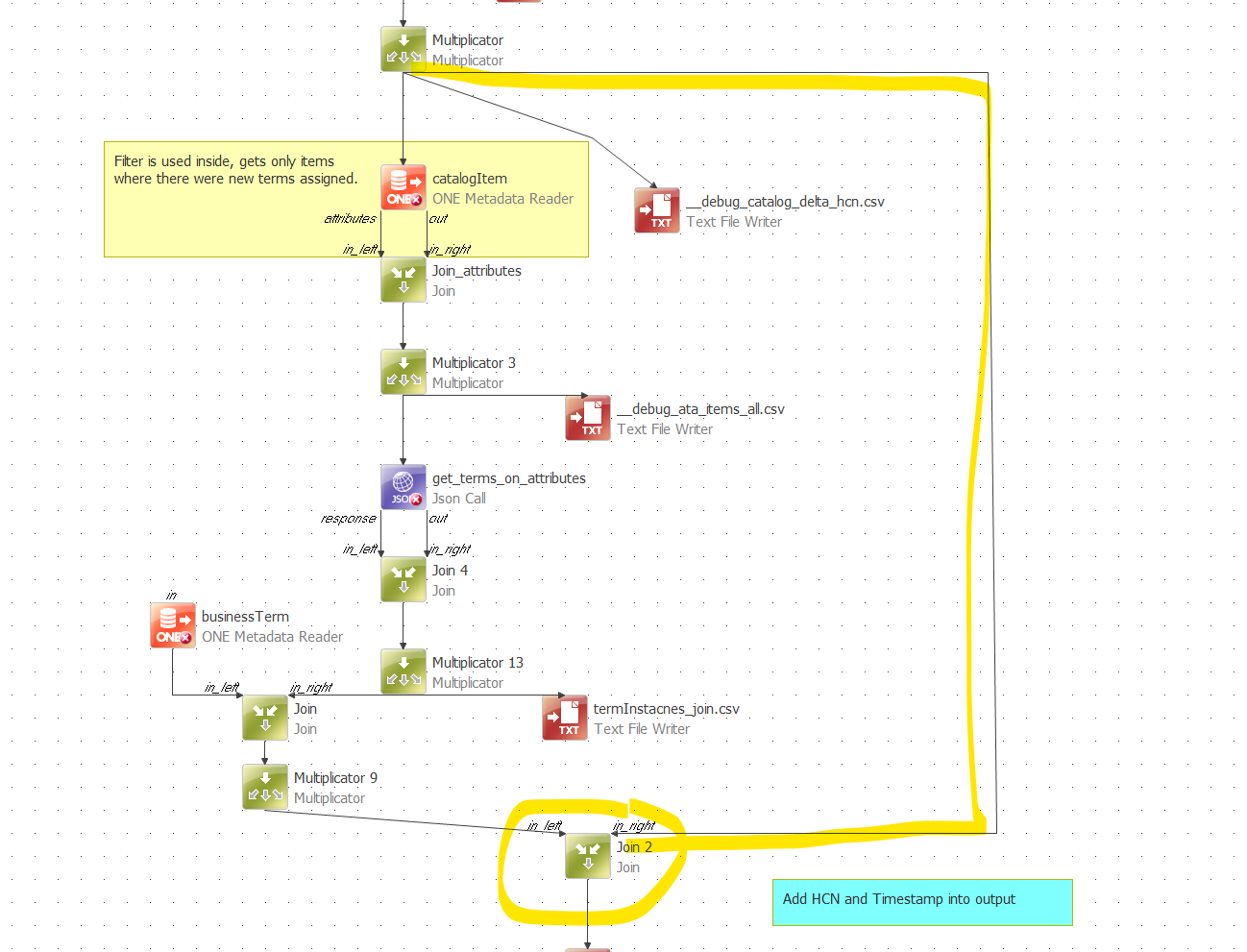
Finally I had time for the next step. Progress as follows.
Because some video indicated it, I changed the query format as follows:
I created a data stream
The plan runs without errors and the ‘run’ window shows 7 records have been processed
For testing purposes I write the output to csv files. It appears that the timestamp-flow writes 7 empty records to the file.
Checking the response debug file the error shows as: “!! This an error response. The body of the response doesn't have to be complete. The HTTP version is not known to this reporter. !!”. We have been trying to locate the cause of the error, but in our logging there are no further clues.
Can you point me in the direction? Any idea what could be causing the issue of having no values in the data stream?
KInd regards,
Albert
Hi,
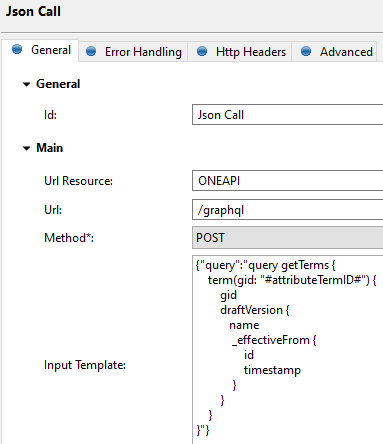
Sort of coincidently I figured this one out now. Devil is in the detail, as usual…
The query in the 2nd json call is now:
{"query":"query getTerms {
term(gid: \"#attributeTermID#\") {
gid
draftVersion {
name
_effectiveFrom {
id
timestamp
}
}
}
}"}
Please note the backslashes in front of the double quotation marks, which solved the issue.
Maybe worth mentioning that in an Ataccama video that can be found here, it is mentioned (at 01:16:17) that the query that will work in the graphql playground, will have to be formatted to make it work in the json call step in desktop. For that Postman is used (that I don't have).

") Sorry, took me a while to understand the request. So the query returns all terms that changed since some timestamp, and you want the timestamp of the LAST change of each of the term? (let’s say some will change multiple times during the period of time you are querying).
Sorry, took me a while to understand the request. So the query returns all terms that changed since some timestamp, and you want the timestamp of the LAST change of each of the term? (let’s say some will change multiple times during the period of time you are querying).