
You can optimize your plans by simple things. In this case I would like to show how the number of columns/fields influences the performance of the processing.
Test conditions
- local environment, stable conditions
- 14M records generated by Random Record Generator
- 78 fields containing fixed strings or dates
- No parallelism level set
Test Cases
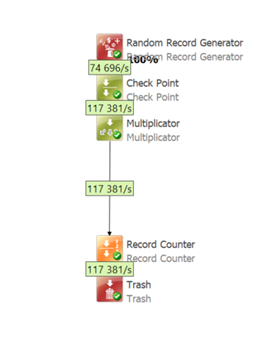
One stream – simple reading - BASELINE
- Overall progress: 117k/s
- Duration: 3:08min
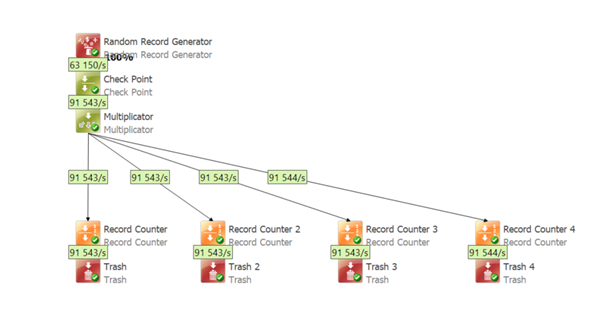
Split into 4 streams, same number of fields – you really need ALL fields in ALL streams
- Overall progress: 91k/s
- Duration: 3:42min
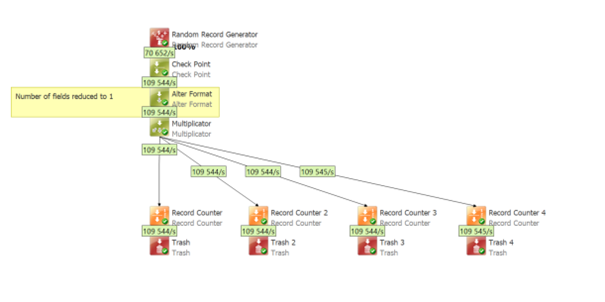
Split into 4 streams, reduced number of field to 1 – maybe you just need 1 field in each stream
- Overall progress: 109k/s
- Duration: 3:19min
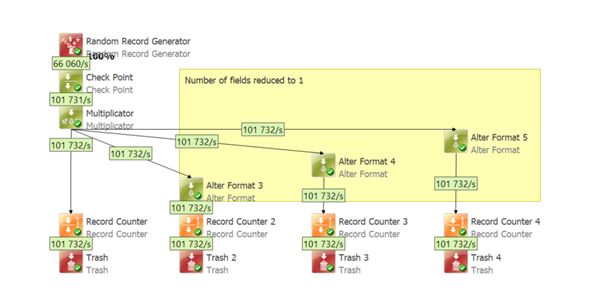
Split into 4 streams, 3 of them with reduced number of fields to 1 – you might not need all fields in other streams
- Overall progress: 101k/s
- Duration: 3:33min
In this example it’s just about simple transformation flow however in case you use JOINs, RepresentativeCreators, Aggregators etc. and you reduce the number of columns before you might safe even more processing time.
As a result - the number of streams and the number of columns/fields in streams matters. Please keep in mind when building your plans.