DQS matching component results are not reflected when bundle is deployed and the entity is re-processed. I did re-build the repo with the new Extended unifier but no effect. What could be a reason?

Page 1 / 1
Hi
What are the changes that you expect some effect to happen?
Have you changed some matching rules? Can you share what exactly you changed?
Thanks
Ales
Hi
It could be that the rematch flag is not set appropriately when the reprocessing is triggered. As Ales mentioned, we would need more information to troubleshoot this.
Thank you for the response. I am not sure what screenshots to provide. But I have this entity where the leverage was on Name, address and a type. Name and type are usually populated and address was not. So I cut down on the matching rules to focus more on the name and type.
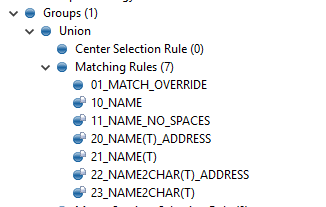
Which should ensure records with or without address to match together, when the name and type are same. I did a repo rebuild with this update, followed by reprocess. But no change.
About re-match flag I think this is what needs to be commented to ensure it grabs all the records even if already mastered
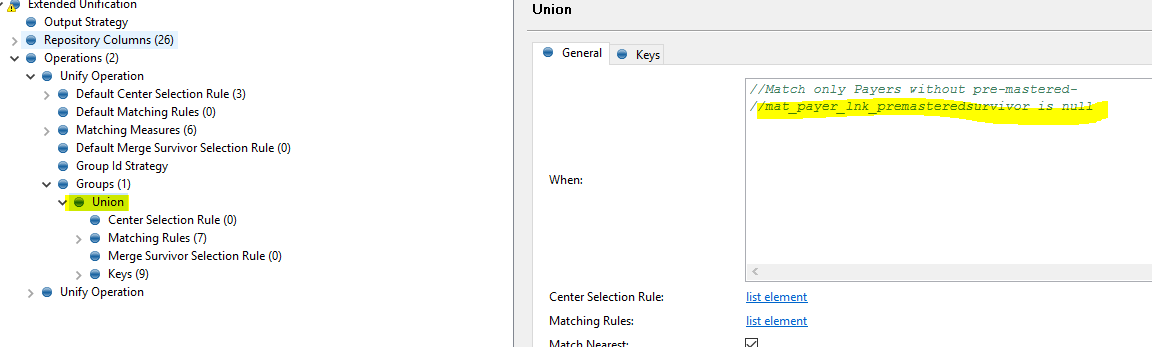
Which is good too.
Hi
Could you attach the component here, so that I can take a look?
Thanks,
Vysakh
Please check the zip file. I will ping you the password.
Hi
If the goal is to adjust matching rules and reprocess all the data, you should be able to achieve by just processing ALL the data using the updated rules.
I have a few additional questions:
- “I did a repo rebuild with this update, followed by reprocess” What exactly you did to rebuild the repo (read the data from repo and write it back)? I guess by reprocess you mean you sent all the data trough the step again.
- Do you need to keep the repository or can you just drop it? This would mean you would lose your already calculated unification keys/IDs of course.
- have you tested your new matching rules with a completely empty repo? Just to be sure that your new setup work for newly incoming data.
Thanks,
Ales
- “I did a repo rebuild with this update, followed by reprocess” What exactly you did to rebuild the repo (read the data from repo and write it back)? I guess by reprocess you mean you sent all the data trough the step again. - YES
- Do you need to keep the repository or can you just drop it? This would mean you would lose your already calculated unification keys/IDs of course.- I did DROP and rebuilt repo with the extended unifier
- have you tested your new matching rules with a completely empty repo? Just to be sure that your new setup work for newly incoming data..- I did DROP and rebuilt repo with the extended unifier. I did check few records on repo and they looked like they had same master_id. Followed by bundle update to OHD and reprocessed the subject. When I debug or create a test plan on DQS and pass the data through matching component it works very well. But when I delete the records automatically by passing deleted records so they are deleted on source /instance/repo completely. Followed by insert, the matching updates are not seen. Neither is the subject reprocess helping. Thank you for the help.
Thanks,
It seems when the Pri_match_can_ID is same on all records with same name, while pri_master_id is different (supposed to be single master_id) and match_role is ‘R’ (R. Renegades or records not similar to any center in a candidate group.). How to resolve these records to participate in the matching.
quickly checked your component and here are my observations:
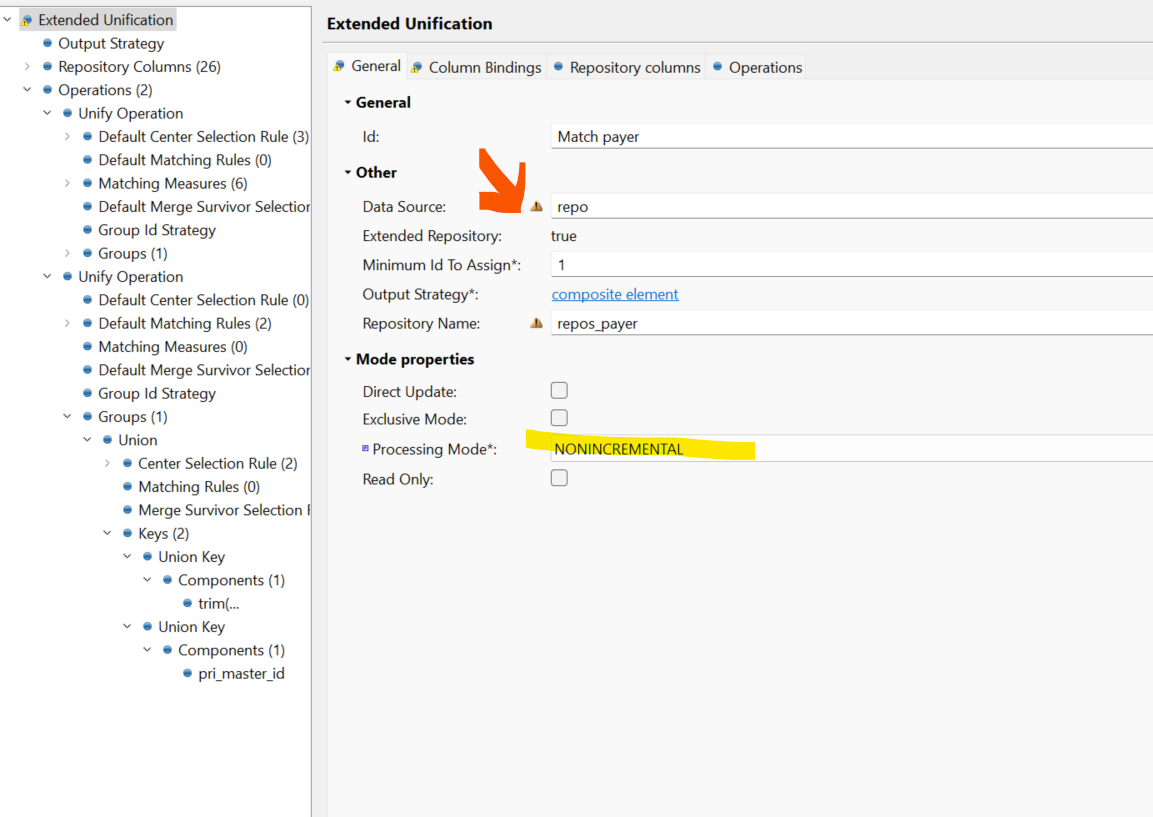
- your Extended unification is set to NONINCREMENTAL MODE which means you always need to process all the records. The repo is never use. This seems to me as the most important one. You mentioned rebuilding the repo however your configuration does not use the repo at all. I believe if you switch to NORMAL mode you can get correct results with the REPO.
-
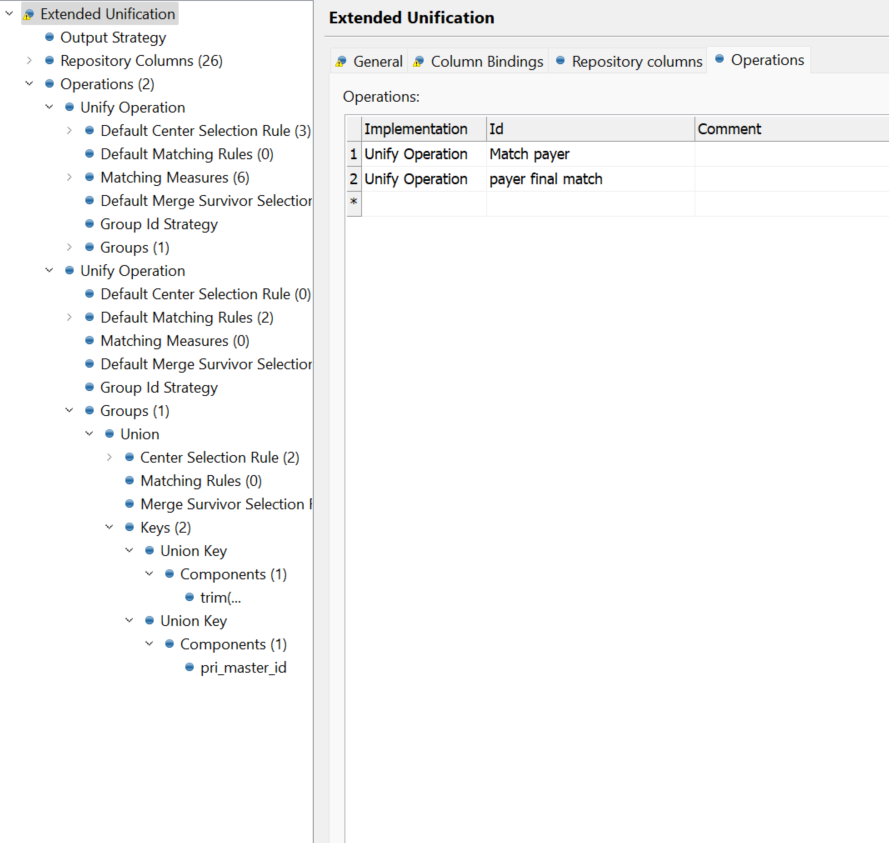
- you have two operations configured:
- match Payer - contains most of the matching rules
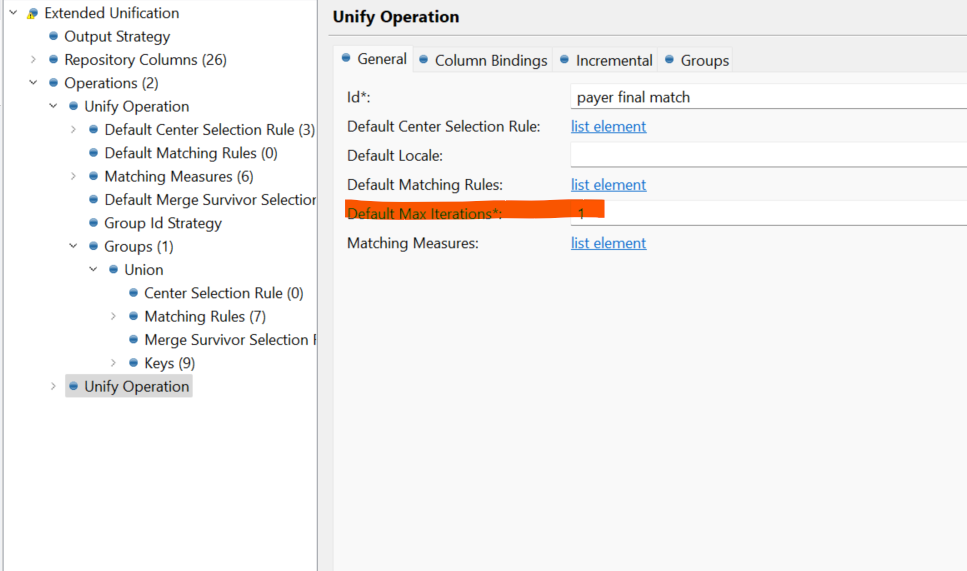
- payer final match - just two rules, seems like just technical confirmation of the match. This one actually has the number of Iterations set to 1. i.e. there can be only 1 matching group as part of the candidate one. It might be on purpose however that’s probably why you are getting the Unification Role: R - renegate - “Records not belonging to primary group are records having primary unification role
Nor possiblyR”. You can increase this parameter to increase the number of records in the matching group. -
-
“ It seems when the Pri_match_can_ID is same on all records with same name, while pri_master_id is different (supposed to be single master_id) and match_role is ‘R’ (R. Renegades or records not similar to any center in a candidate group.). How to resolve these records to participate in the matching. ”
If the match_can_id is the same on all records it means that you based on your KEY groups you matched all the records together. Then it goes to pri_master_id - using matching rules. The relevant unification role for this UNIFY OPERATION is pri_match_role.
The match_roles is the result of the second Unify operation (payer final match) which has the number of iterations set to 1 hence the R records (just 1 record is allowed in the candidate group otherwise “renegates”)
Thanks a ton Ales for your time.
- During repo-rebuild - do not have it set to nonincremental load. Instead it is set to RELOAD. And the repo is pointed to the right DB.
- I did try increating max iterations on the 2nd Unification, but it did not change. yes it was intentionally set to 1
- With the details you mentioned I have noticed something happening in all the cases
the pri_match_can_id should be different. The keys always have the combination of name and type. But the match_can_id is same although the value is different. And all these with different type are assigned match_role ‘R’.Name Type pri_match_can_id Pri_master_id match_role ABC 1 12345 11111 S ABC 1 12345 11111 S ABC 2 12345 22222 R ABC 2 12345 22223 R
Would it be right to update center selecton on 2nd unify operation
//Prefer Center records to remain the same from the first round of Matching
case(
pri_match_role is "M",
5,
pri_match_role is "I",
4,
pri_match_role is "S",
3,
pri_match_role is "R",
3,
0
)
This renders the expected result on the test. But wonder if there is any downside on it. As i wonder why these ‘R’s were not included earlier. Will keep you posted further.
Update: The change does render results only when the repo-rebuild is with few fewer payers and not when full-reload. Max iterations had been adjusted to a higher number too.
I’m not sure I follow now. If you are getting R roles that means you have bigger MATCH_CAN group than the number of MAX ITERATIONS in that Unify operation. i.e. you can actually have some records grouped together and some not because they were rejected as Renegates.
Seems like you are getting Renegates already from the first Matching operation. Isn’t that you have much bigger groups than before? Could you please do the profile/frequency count on the pri_match_can_id?
Thank you for the help.
The only worry now is that you probably have pretty large CANDIDATE groups - if you did the profile on the can_id, you can see the maximum size.
Large groups might have impact on the performance of the whole matching process. The more iterations the engine needs to do, the longer the process takes. It can also have an impact on higher memory consumption.
In general it’s a good practice not to have CAN groups bigger than 1000 records. 5k is already quite a big group, 10k might be a perf. issue.
Have you noticed any significant performance degradation with this new setup?
Hi
The only solution for this is to
- review your matching rules in terms of how the candidate group is created
- adjust the rules so that you have candidate group size max 1000 (5k is already a big group)
- HW and memory adjustments - this may require some deeper analysis where the bottleneck is. However #1 and #2 is the optimal way to go as it’s not typical to create such a big candidate groups and then try to find matches within those.
Reply
Login to the Ataccama Community
No account yet? Create an account
For Ataccama Customers and Partners
or
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.