
Introduction
This post was created to answer the following questions:
- When moving data through data pipelines, how can the Ataccama ONE DQ platform support Data Integration platforms other than its own.
- How do other Integration Platforms access the DQ rules?
- How do other Integration Platforms flag records for Data Stewards to review?
DQ platform in context of integration processes
There are three key patterns that are typically used for integration of the ETL process with Data Quality:
Option 1
The integration platform calls Ataccama DQ rules exposed as real-time API, sending in batches or micro-batches of data for evaluation.
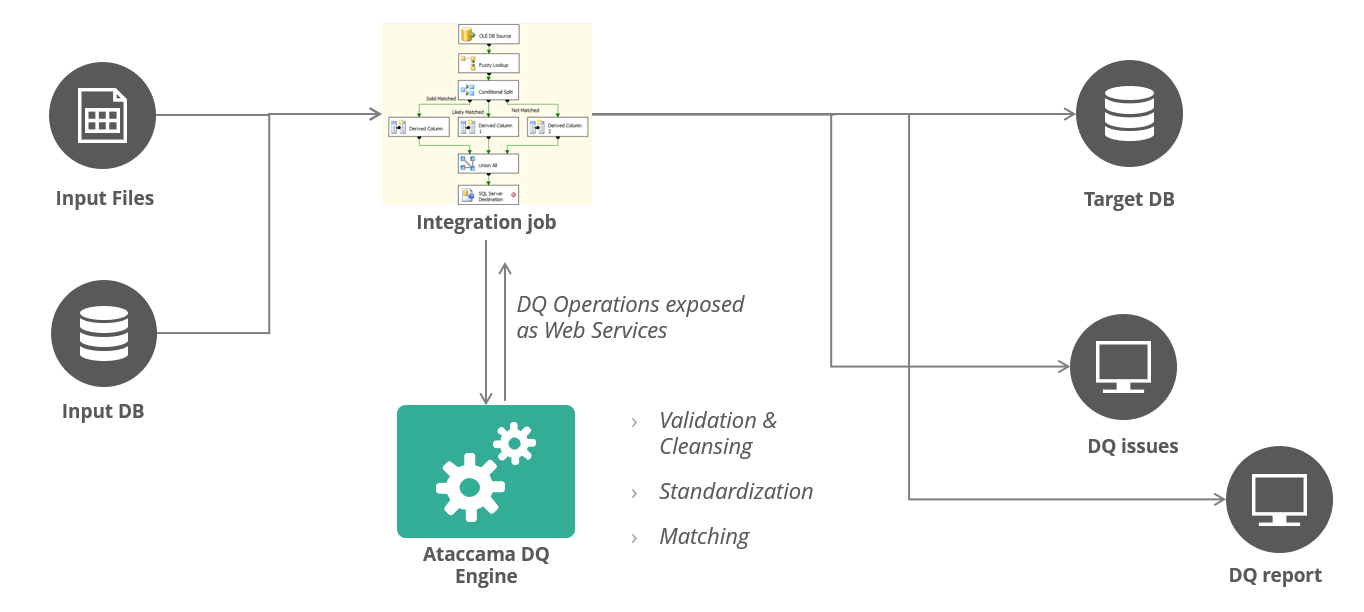
Option 2
The Integration platform loads data into a staging/landing layer and triggers (via API call) a batch process in Ataccama, Ataccama evaluates/improves the data and populates the cleansed layer in the data lake, including DQ scores and flags.
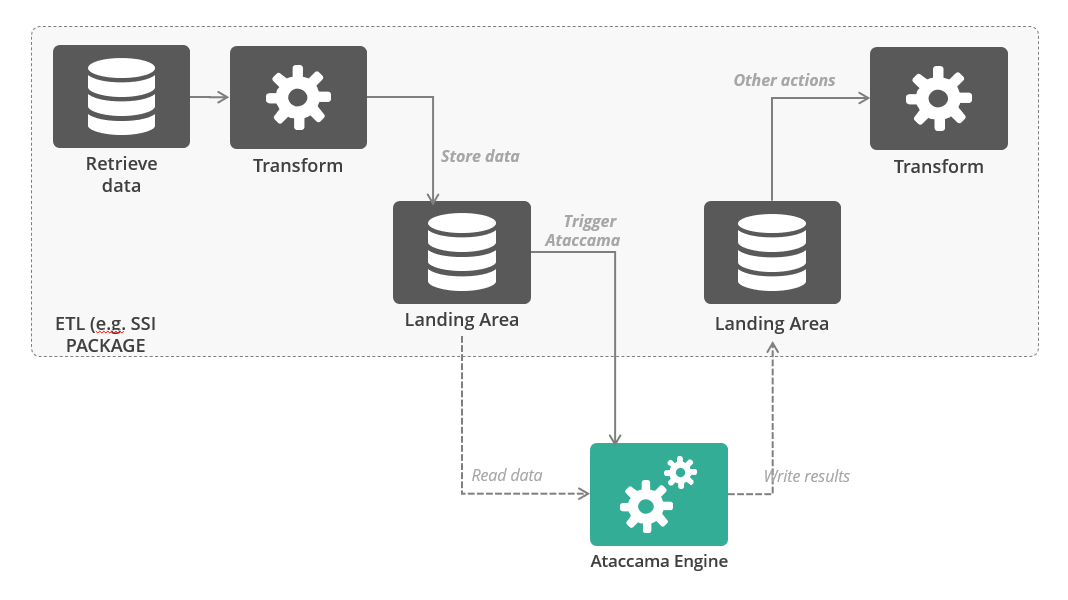
Option 3
Ataccama can be connected to a data stream, such as Kafka, and on the fly evaluating data in the stream - every message is checked, scored and returned back into an outgoing topic or even sorted into either valid or invalid outgoing topic.
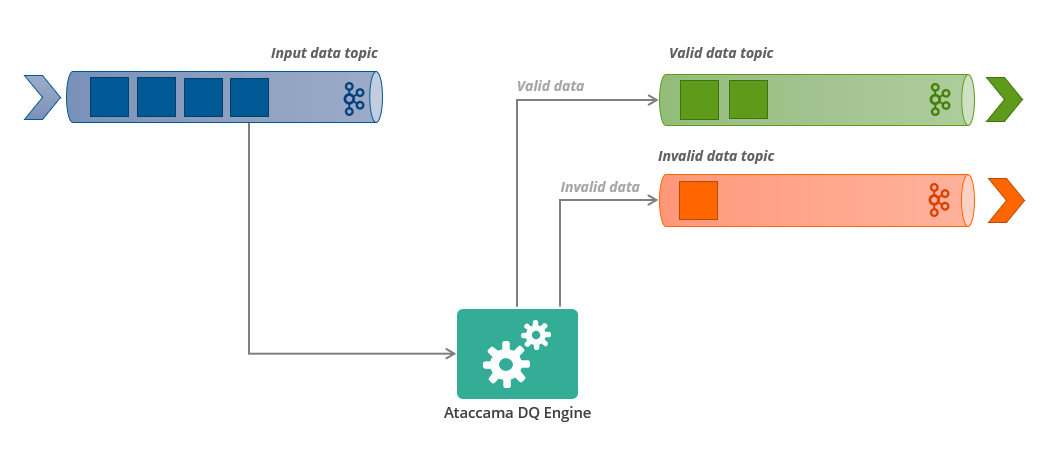
Data pass, data discard and flow stop
And as for how the DQ process fits into the overall execution of the integration flows: Data Quality is typically checked at two stages of any ETL process - at Extraction and after Transformation. Four different types of measures are typically taken when checking data that is being extracted and transformed:
-
Pass the record without error (= ignore),
-
Pass the record and mark the affected data/column (= flag),
-
Discard/sort out the record (= detect & extract),
-
Stop the integration flow (= raise critical error).
Typically what we'd want to do is flag any invalid data (in terms of completeness, correctness, consistency or timeliness) and let the integration process run. Results of the DQ evaluation and an aggregated summary of any flagged problems are typically visualized in a DQ dashboard or report - either within Ataccama platform or in 3rd party reporting such as PowerBI.
Only some particular exceptions based on defined criteria are typically turned into "issues" (= workflows) that will require Data Steward review or approval. These types of extracted issues do not typically interrupt the integration process, they are raised and resolved afterwards. Any update or resolution from the Data Steward can be applied to the transformed data "ex-post".
Critical errors that result in the integration flow being stopped are typically based on incorrect data volumes/structures (which is something the integration platform can detect on its own) or based on the relative volume of flagged/invalid data values being too high. It is typically the integration platform that would calculate the aggregated validity of the processed dataset based on the DQ outputs from Ataccama processing
This same approach applies to the cloud-based integration platform as well as traditional ETLs. With Azure it would typically be via REST API calls to Ataccama DQ rules using ADF Logic Apps. Cloud Data Fusion would also either trigger the job in Ataccama via REST API call or trigger a batch job on top of the created files, relational or non-relational databases.
Examples
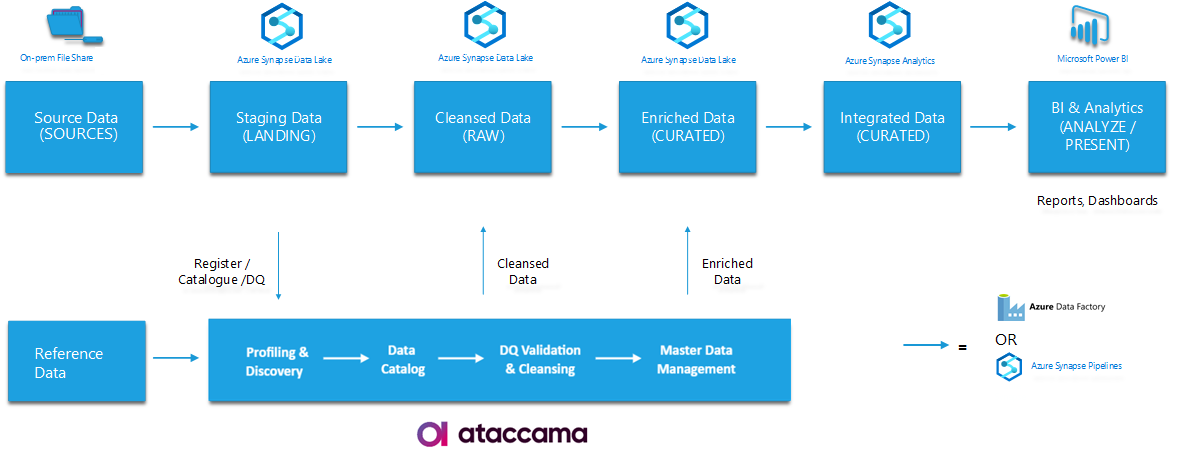
Example 1: Ataccama ONE DQ & Azure Synapse
Below is an example of a Azure-based solution where it's not just Data Quality, but also Ataccama Catalog and Master Data Management that are integrated with the Azure-based process:
Example 2: Ataccama ONE DQ & Microsoft SSIS

Thanks to
