Hi everyone,
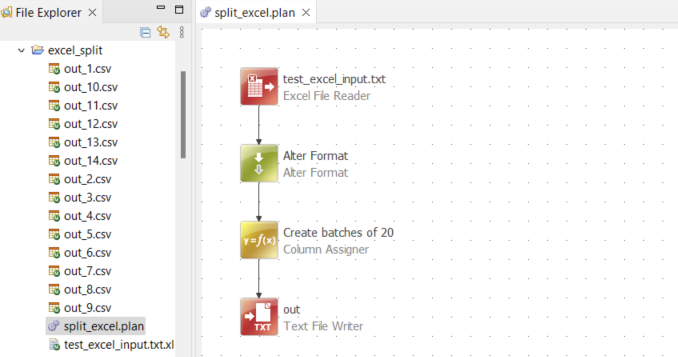
I currently have a plan that is creating a main task and populating it with sub tasks that each link to individual tables. My issue at the moment is that sometimes this creates tasks with a huge amount of sub tasks that may seem daunting for people to try to work through.
Currently the tables and their attribute ids are all stored in one excel sheet, so I was wondering if it would be possible to break it into separate excel files each containing 20 rows. If this is possible I would then be able to create additional tasks rather than just grouping everything in one.
Thank you for any help!