



In this Tips & Tricks post, I will show you how to configure a plan to evaluate your data and make a decision on whether to continue processing your data as planned or to stop processing data and exit the plan safely without the plan throwing an error.
In this scenario we will generate a data set consisting of 1 column and 100 records. The column will have either a true or false value. We’ll have a business rule that checks the values of the 100 records and stops processing the data if at least one false value is found in the data stream.
Let’s prepare the data pipe initial so that we have input and output data flows.
Starting with a blank .plan file we will add a Text File Reader step to store our results and a Random Record Generator step to generate the 100 records.
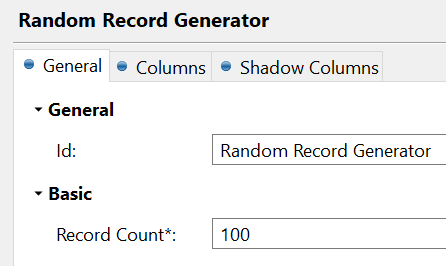
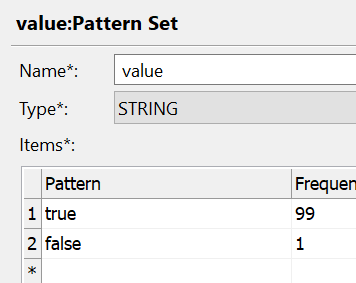
We’ll configure the Random Record Generate step to create 1 column named value, and to create the values true 99 in 100 frequency and false 1 in 100 frequency. This configuration will ensure that when we run the plan 1 false record may be generated randomly out of the 100 records being generated.
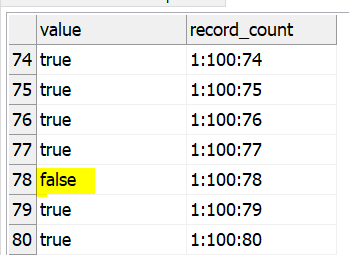
Now that we have the basic data pipeline in place, lets count how many records are in our data pipeline. The record count column will be used later in the process to support the evaluation of the business rule and take the action to either continue data processing or stop safely. (How many true values do we have compared to how many records we have in total)
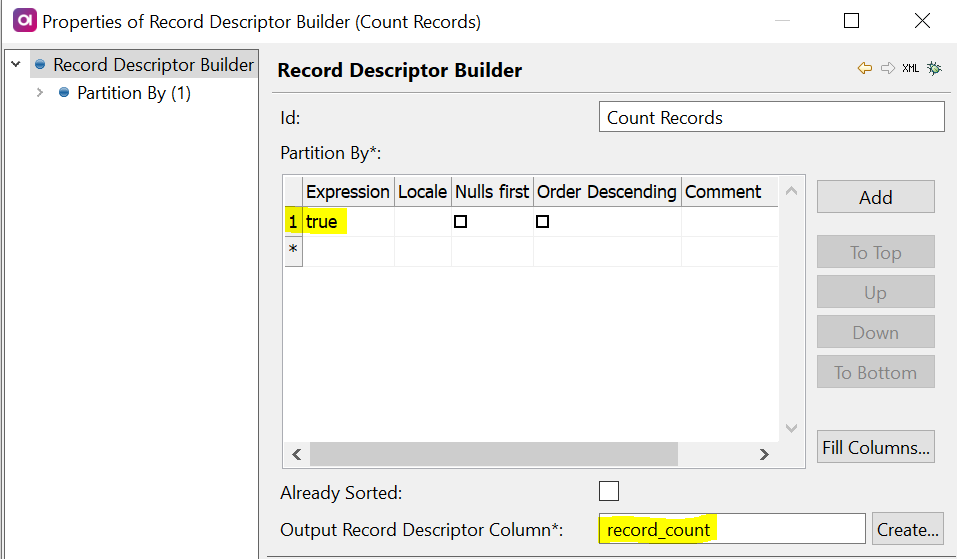
We’ll add and configure a Record Descriptor Builder step after the Random Record Descriptor step and before the Text File Writer step.

We’ll configure the Record Descriptor Builder step to partition by the value true and we’ll output our record descriptor value to a new column called record_count, which we will add as a shadow column in the Random Record Generator step.
If we run the plan after adding the Record Descriptor Builder for the record_count column. We’ll see results in the Text File Writer. You may need to run the plan a few times if you do not see a false value initially.
Next we will add a 2nd Record Descriptor Builder after the first Record Descriptor Builder we already configured, and we will configure this Record Descriptor Builder to partition on the value column (which is the column containing our true or false input values).
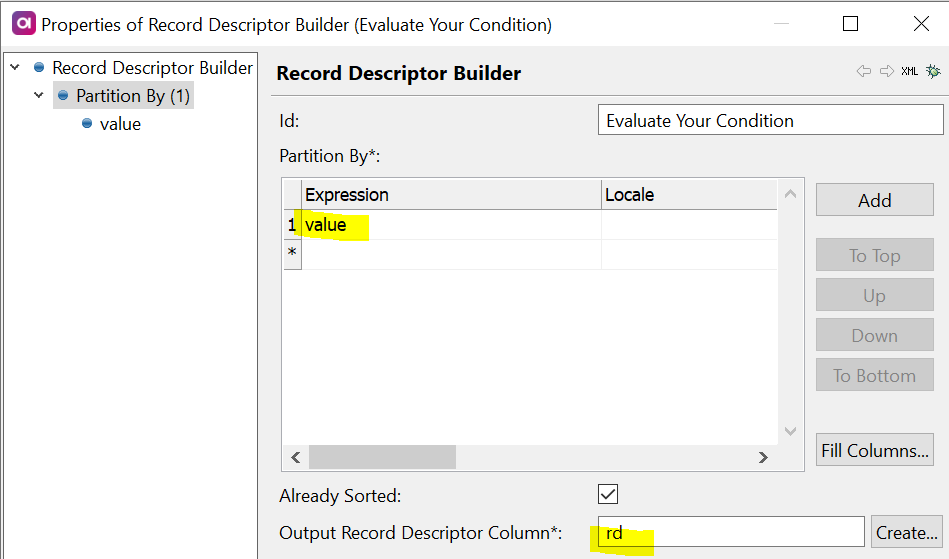
We will also add the rd column as a shadow column in the Random Record Generator as we did previously.
If we run the plan after adding the second Record Descriptor Builder step for the rd column. We’ll see results in the Text File Writer. You may need to run the plan a few times if you do not see a false value initially.
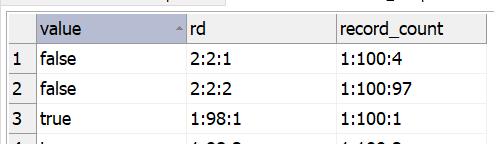
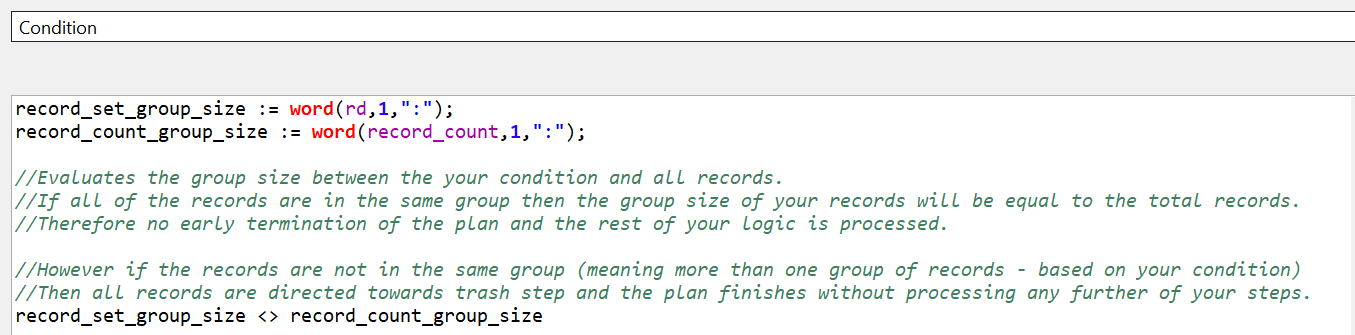
The value returned by the Record Descriptor Builder step is a composite of 3 values separated by a colon.
<group_id> : <group_size> : <position_in_group>
If we visually compare the <group_size> between the record_count and rd columns, we observe that when there is at least one false value the <group_size> in the rd column is the total count of false values, (and of true values). In the screenshot above that is 2 false and 98 true.
This observation will form the technical implementation of the business rule.
As our last change to the plan, lets add two more steps.
Add a Condition step after the 2nd Record Descriptor Builder, then connect the out_false of the Condition step to the Text File Writer.
Then we’ll add a trash step and connect this to the out_true of the Condition step.

We’ll configure the Condition step with the technical implementation of the business rule.
We have the business rule to send all the records in the pipeline to the out_true (Trash step) is the condition is met and to the out_false (Text File Writer) is the condition is not met.
We have developed the example, if we run the plan a few times and monitor the content of the output Text file we will observe the text file is only populated when all values are true.
From here we can replace the Text File Writer with the rest of our data pipeline.
Have a great day.
Danny Ryan
Technical Training Manager