
Hello,
I am currently working on a data masking project in ONE Desktop and I'm seeking some advice on how to approach a specific scenario using two tables.
I have two CSV files:
-
Classification Table (CSV #1): This table contains two columns - '
ColumnName' and 'DataClassification'. The 'ColumnName' field lists the names of various columns, and 'DataClassification' provides their respective data classifications, such as "Restricted", "Confidential", "Public", or it may be blank. -
Data Table (CSV #2): This table contains multiple columns, named according to the entries in the '
ColumnName' field of the Classification Table. Each column holds different sets of data.
Classification Table (CSV #1):
ColumnName | DataClassification |
|---|---|
Name | Confidential |
Age | Public |
Email | Restricted |
Data Table (CSV #2):
Name | Age | Email |
|---|---|---|
Alice | 30 | alice@example.com |
Bob | 25 | bob@example.com |
My goal is to mask the data in the Data Table (CSV #2) based on the classification provided in the Classification Table (CSV #1). For instance, if a column is marked as "Confidential" in CSV #1, the entire corresponding column in CSV #2 should be masked accordingly.
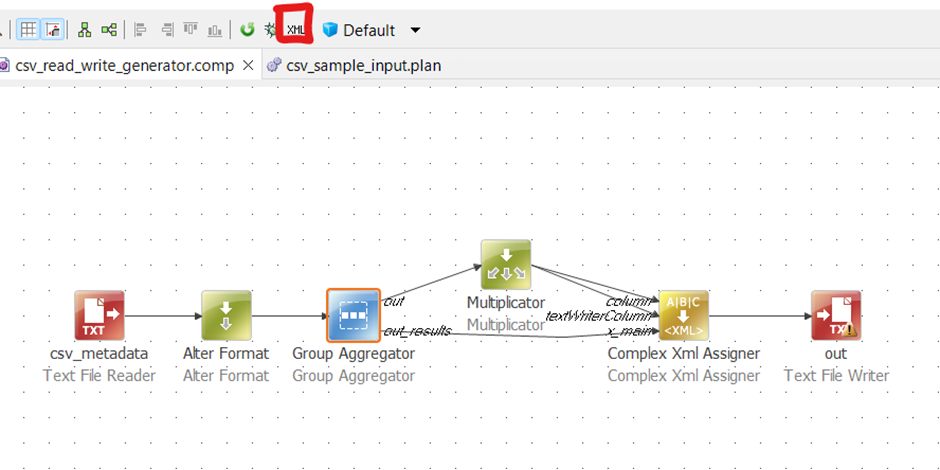
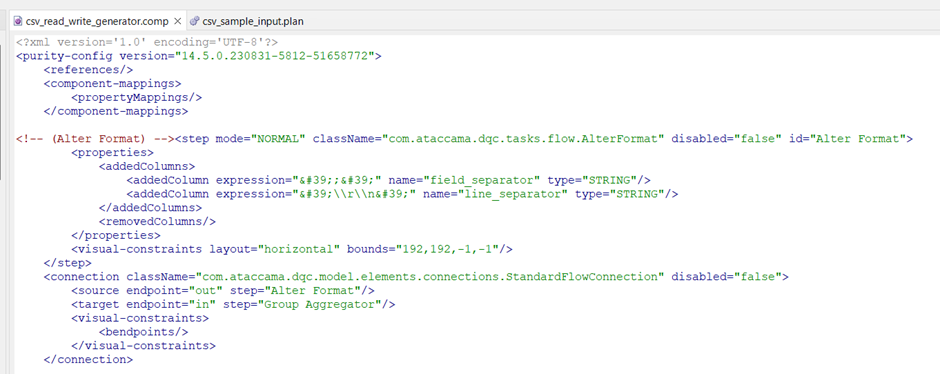
I'm looking for guidance or suggestions on the most scalable way to achieve this without resorting to writing a custom step. It seems like all of the possible steps in the desktop app go row by row, which is an issue if I’m trying to conditionally mask an entire column, or require manual input to specify the columns.
 ♀️
♀️